
多變多巴胺——第十一部:RPE和APE協同學習
每次我們做出選擇時,都感覺事情是在自己的掌控之中,但實際上,我們的大腦會受到「隱藏力量」的影響。動物和人類一樣,往往會做一些能帶來獎勵回報的事,比如尋找食物或贏得比賽。他們還會重複以前進行後有效獲得回饋的事物,即使他們不完全理解為什麼。在過去,科學家們認為發生這種情況是歸功於多巴胺的獎勵預測誤差 (Reward Prediction Error, RPE),就像上回我們談過的,即使是AI也要向RPE拜師學藝。但近期多巴胺對學習所發揮的作用,不再僅限於通過加強對獎勵價值的追求,科學家發現另一個確保與動作有關的多巴胺釋放,加強了「狀態–動作」的關聯可促進學習機制,這是一種記憶和反射間的訊號對話,通過加強重複的關聯來支持學習,稱之為「動作預測誤差」(Action Prediction Error, APE)。
撰文|A. H.

回顧獎勵預測誤差 (Reward Prediction Error, RPE) 科學史可知,早期源於1997年劍橋大學神經科學教授Wolfram Schultz證明了多巴胺能神經元編碼獎勵預測誤差,為「強化學習」提供了神經生物學的基礎。時至二十一世紀,RPE的神經編碼更在如何調節紋狀體的可塑性,從而影響強化學習和感覺預測研究的廣度和深度。這些多巴胺參與獎勵相關過程的各式研究,成為我們理解學習和行為的基礎。簡單的說,RPE能幫助我們學習做一些能帶來獎勵回報的事,多巴胺對我們的大腦傳遞出:「嘿,這比我預期的要好(或更糟)!」訊號,教會我們重複那些能帶來好結果的行為。
但這並不能解釋一切。即使獎勵不再是重點,只是「重複」的事情會如何?認真思考、權衡利弊,我該選擇哪條路去上班、該喝哪種咖啡?但其實很多時候,我們只是在「做」事情。我們開著同樣的路去上班,喝著同樣的咖啡。為什麼?過去可能會認為這一切都是為了獲得某種獎勵,但究竟是什麼驅使我們養成這些重複的、看似沒有價值的習慣呢?先前的研究發現,學習所需的多巴胺神經元位於中腦的三個區域:腹側蓋區、黑質緻密部和黑質外側部。雖然一些研究表明,這些神經元參與了獎勵編碼,但早期的研究亦發現,這些神經元中有一半負責編碼運動,但原因仍然是個謎。RPE神經元投射到紋狀體的所有區域,除了紋狀體尾部 (the tail of striatum, TS)。而運動特異性神經元投射到除伏隔核以外的所有區域。這意味著伏隔核專門發出獎勵訊號,而紋狀體尾部專門發出運動訊號。
為解開這些問題,倫敦大學學院 (UCL) 發表在《自然》上的一項新研究 (2025/5/14) 表明,另一種平行的多巴胺訊號正在發揮作用,也就是所謂的「動作預測誤差」(Action Prediction Error, APE)。這個訊號不關心獎勵,它只關心你採取的行動是否是你可能採取的行動,科學家稱之為多巴胺能「價值中立 (value-free) 的教學訊號 (teaching signal)」。此研究實證了先前動作、習慣和行為的諸多假設,如2020年牛津大學科學家所提出的——多巴胺在學習和動作與習慣形成的學習假設。而UCL此研究的實證重點在大腦的紋狀體,非有關「獎勵」部分的腹側蓋區 (VTA) 或腹側紋狀體 (ventral striatum, VS),而是紋狀體尾部(TS)。在該研究單位發布的新聞稿中說明:「這是第一次確定第二個學習系統,它可能有助於解釋習慣是如何形成的,並為解決與習慣性學習相關的條件(如成癮和強迫症)的新策略提供科學基礎。」
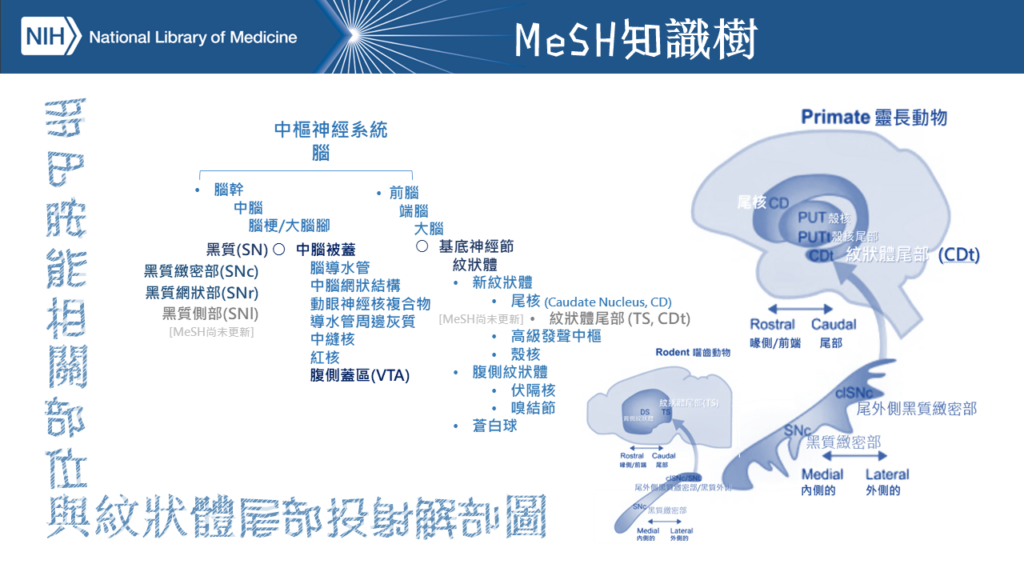
首先,我們先認識一下紋狀體尾部、腹側蓋區和黑質等這些我們在本文中提到與多巴胺能相關的部位。按照美國國家醫學圖書館的醫學科目標題(圖二)可知,主要分布在中腦與端腦的基底神經節。與此同時,行為科學的當前觀點越來越將紋狀體尾部視為一個獨特分支,特徵是密集的感覺輸入和投射來自一組獨特的多巴胺神經元,如視覺定向、音調引導選擇和避免威脅性刺激等。
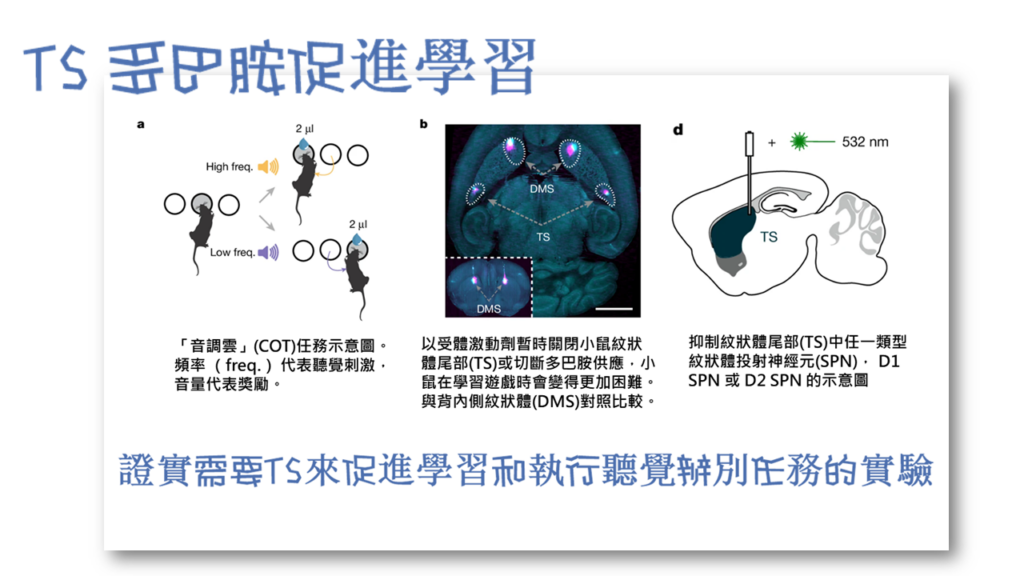
Greenstreet等人 (2025) 為進行調查,研究小組對小鼠進行「聽覺辨別任務」訓練。小鼠學會將特定的聲音頻率,稱為「音調雲」(cloud-of-tones,COT) 的任務(一種測試聽覺表徵如何轉化為動作指令的研究設計)。首先,他們確定紋狀體尾部 (TS) 至關重要。暫時關閉TS會損害訓練有素的小鼠的表現。更重要的是,在訓練前,永久性地損傷TS或消除其產生多巴胺的輸入,會嚴重阻礙小鼠學習的能力,降低它們的學習速度和最終表現。這證實了TS及其多巴胺供應對於學習這種「聲音–動作」的關聯至關重要(圖三)。
其次,研究人員使用名為dLight1.1的螢光多巴胺感測器即時觀察紋狀體尾部 (TS) 和獎勵區域腹側紋狀體 (VS) 的多巴胺活動。結果顯示,當小鼠獲得獎勵時,VS顯示大量多巴胺峰值,而沒有獲得獎勵時,VS顯示出下降,這是一個清晰的獎勵預測誤差 (RPE) 訊號。與此形成鮮明對比的是,TS對獎勵的反應極小。然而當小鼠做出動作時,多巴胺水準達到高峰。這項活動與聲音提示、甚至任務本身都無關,證實了TS多巴胺編碼動作。但它只是一個動作訊號,還是具有更多意義,如動作預測誤差 (APE)?如果TS多巴胺充當APE訊號,它的活動應該根據動作的「可預測性」而變化,為了測試這一假設,研究記錄了學習過程中的TS和VS多巴胺訊號,並將這些訊號與基於雙重值/價值中立強化學習模型的RPE和APE值進行了比較,實驗結果摘要如圖四。

那麼如果動作預測誤差 (APE) 存在,它真的可以「教」嗎?透過使用光遺傳學技術在特定時刻人工刺激TS多巴胺的釋放,研究人員使小鼠產生偏差。刺激導致小鼠越來越喜歡與刺激相關的動作,顯示出TS多巴胺可強化特定的「狀態–動作」聯繫,而無需獎勵。為了解APE和RPE如何協同工作,團隊建立了一個計算模型。此實驗模型的結果顯示:
- 只有APE的系統無法學習基於獎勵的任務;它只是不斷重複隨機動作。
- 僅有RPE的系統可以學習該任務。
- 結合RPE和APE的雙控制器系統比單獨的RPE系統學習得更快、更穩健。
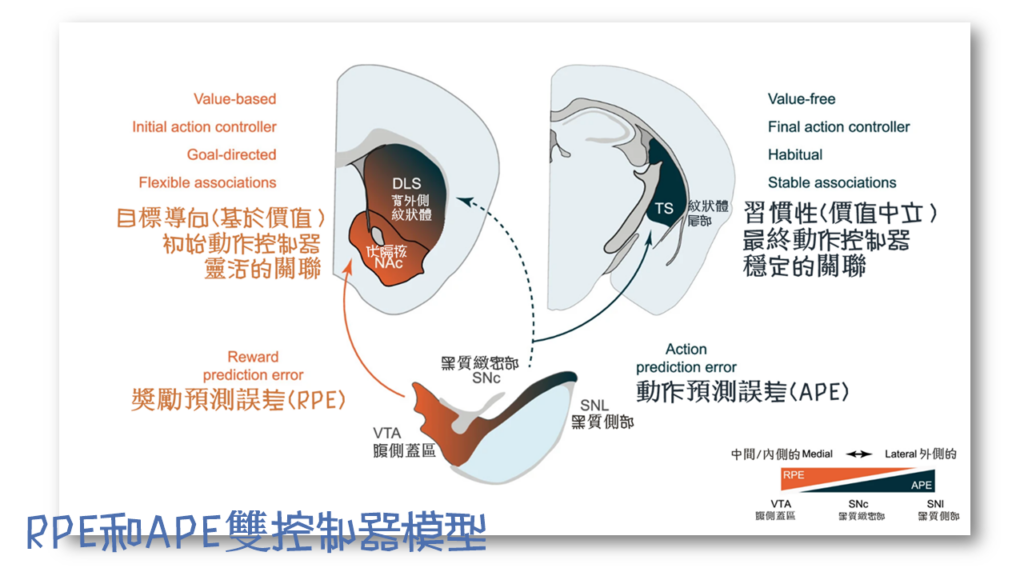
此研究最後討論與建議,整個紋狀體中所有與運動相關的多巴胺活性都可能反映出作為價值中立教學訊號的APE。RPE和APE可以用作不同的教學訊號,以推動紋狀體不同區域的目標導向(基於價值)和習慣性(價值中立或基於頻率)的學習(圖五)。研究的通訊作者Stephenson-Jones博士解釋:
「想像一下去當地的三明治店。第一次去的時候,你可能會花時間選擇一個三明治,根據你選擇哪個,你可能會喜歡也可能不喜歡。但是,如果您多次回到商店,您就不會再花時間想知道該選擇哪個三明治,而是預設開始選擇您喜歡的三明治。我們認為是大腦中APE多巴胺訊號允許您儲存這個預設策略。」
時隔近30年,二個英國代表性研究將多巴胺獎勵預測誤差 (RPE) 和動作預測誤差 (APE) 理論引入神經科學的學習機制中,APE更重新定義了我們對多巴胺和強化學習的理解。兩種多巴胺教學訊號的協同,首先與獎勵有關的RPE啟動學習過程,弄清楚哪些行動帶來好的結果。一旦我們持續做某件事,與動作有關的APE就會介入。APE協助鞏固那個特定動作,使其變得更順暢自動和穩定,進而把它變成一種「習慣」。換句話說,APE建立了一種預設策略,當這種情況發生時,就依此這樣做,而不必每次都考慮獎勵,APE也因此使學習變得更穩定更有效率。
參考文獻
- Björklund, A., & Dunnett, S. B. (2007). Fifty years of dopamine research. Trends in neurosciences, 30(5), 185-187.
- Greenstreet, F., Vergara, H. M., Johansson, Y., Pati, S., Schwarz, L., Lenzi, S. C., ... & Stephenson-Jones, M. (2025). Dopaminergic action prediction errors serve as a value-free teaching signal. Nature, 1-10.
- UCL Sainsbury Wellcome Centre News, Scientists discover new way the brain learns. 14 May 2025.
- 圖二:美國國家醫學圖書館的醫學科目標題:黑質(MeSH: D013378),其中黑質側部(SNl)尚未更新; 腹側蓋區(VTA): (MeSH: D017557) ; 紋狀體(MeSH: D003342)、尾核(Caudate Nucleus, CD): (MeSH: D002421),其中紋狀體尾部 (TS, CDt) 尚未更新。
- Green, I., Amo, R., & Watabe-Uchida, M. (2024). Shifting attention to orient or avoid: a unifying account of the tail of the striatum and its dopaminergic inputs. Current Opinion in Behavioral Sciences, 59, 101441.
- 米奇老鼠圖像為維基公眾領域圖。