
看不見的細節──對抗樣本

編譯/陳儁翰
什麼是對抗樣本?
首先,讓我們來看看「對抗樣本」(adversarial examples)的範例:

原圖(左)加上雜訊(中)後,成為對抗樣本(右)。(圖片來源:Goodfellow et al., 2015.)
最左側的圖片,人眼一看便知是一隻熊貓,以分類器的角度而言,則有57.7%的信心認定圖片中就是一隻熊貓。最右側的圖片,人眼看仍是一隻熊貓,但是分類器卻因為圖片被添加了雜訊(中間的圖片),而誤判其為一隻長臂猿!像右圖這樣具誤導性的樣本,便稱為「對抗樣本」。
那如何排除或降低這些對抗樣本的干擾呢?一個可能的想法是:既然對抗樣本是因為資料中的雜訊造成的,那麼只要將輸入的圖片去噪,便可迎刃而解。然而,實際上,神經網路的其他部份也須同步去噪才能達到效果。
另一個方法,則是主動在訓練資料中加入對抗樣本,使得模型能從中區辨對抗樣本的干擾,稱之為「對抗訓練」(Adversarial training)。儘管需要額外準備大量高品質的對抗樣本,但仍是目前最有效的方法。
穩健與非穩健特徵
了解了什麼是對抗樣本與對抗訓練,我們回到本文的重點。Andrew Ilyas等人首先將一張圖片的特徵區分為「穩健」(robust)與「非穩健」(non-robust)兩類。前者是那些不容易受到雜訊干擾、人眼可區辨的特徵,比如貓狗的整體輪廓,反之則為非穩健特徵。
Ilyas等人認為:有些對抗樣本,其實是模型捕捉到圖片中的非穩健特徵所造成的結果!這些非穩健特徵,雖然容易受到雜訊干擾,但對於模型而言,所能提供的線索不亞於穩健特徵。
為了證明這一點,他們另外創建了一個新的訓練資料庫,做法是在一般訓練資料庫的圖片中加入雜訊,使得圖片的穩健特徵保持不變,但非穩健特徵則指向另一種分類,並且以非穩健特徵指向的分類重新標記圖片。
舉例來說:一張普通的圖片,其穩健與非穩健特徵理應指向相同分類。也就是說,一張狗的圖片看起來像狗,而且人眼察覺不到的特徵也暗示圖片中是隻狗;然而在新的訓練資料集中,研究人員刻意加入特定雜訊,使得同一張照片看起來像狗(穩健特徵維持是「狗」),但人眼察覺不到的特徵卻暗示其中是隻貓(非穩健特徵是「貓」),並且告訴電腦這是隻貓(重新標記為「貓」)。
接著,他們將這個新的訓練集所訓練出的模型套用於一般圖片,結果獲得不錯的辨識準確率!也就是說,這個只識得貓的非穩健特徵的模型,卻能在看到一般貓圖片時,單憑非穩健特徵正確判斷圖片中是隻貓。顯示非穩健特徵確實也是模型辨識圖像時的重要依據之一。
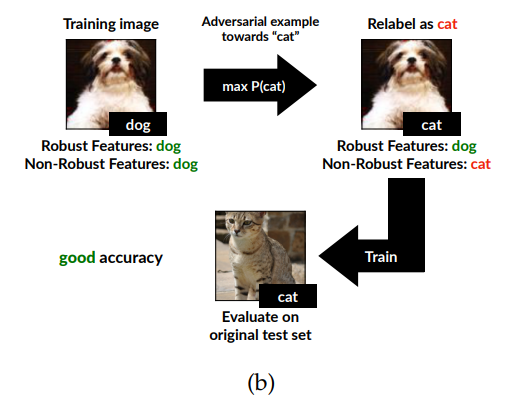
新的訓練集所訓練出的模型,也可以在一般圖片上獲得不錯的辨識準確率。(圖片來源:Ilyas et al., 2019.)
更穩健的模型
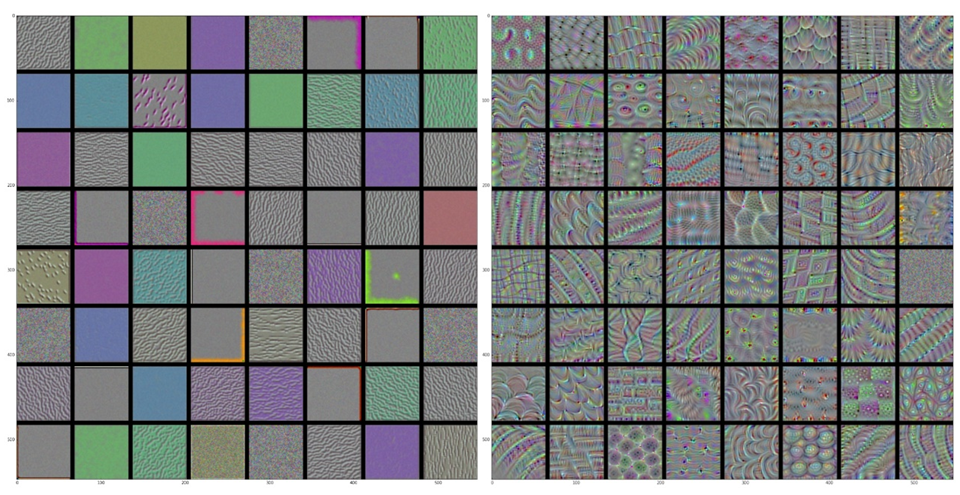
神經網路淺層與深層卷積層的可視化結果。可以看到深層的特徵(右圖)較接近於人類可理解的整體輪廓(近似穩健特徵),而淺層(左圖)僅僅是一些色彩與紋理。(圖片來源:Chollet, 2018.)
Ilyas等人的假說有兩層意義。其一,解釋了對抗樣本的可轉移性(transferability),也就是為何針對特定模型生成的對抗樣本,卻可以被用來欺騙其它模型?如果對抗樣本只是資料中的非穩健特徵所造成的結果,那麼當其他模型在訓練時也捕捉到這些非穩健特徵,最終造成誤判也就沒有什麼好奇怪的了。
另一層,則呼應本文一開始提及的問題:我們如何降低資料中雜訊的影響(也就是對抗樣本),建立一個更穩健的圖像辨識模型?在另一項實驗中,Ilyas等人由另一個已受訓練的深度學習網路中,收集那些在較深層卷積層所捕捉到的圖像特徵,彙整為一個可視為只包含穩健特徵的新訓練集(DR^)。以DR^經過一般訓練過程訓練而出的模型,即使未曾經過對抗訓練,仍然有不差的表現。顯示除了訓練方法外(例如採用對抗訓練),訓練資料事前的處理(例如移除其中的非穩健特徵)也是一大關鍵。
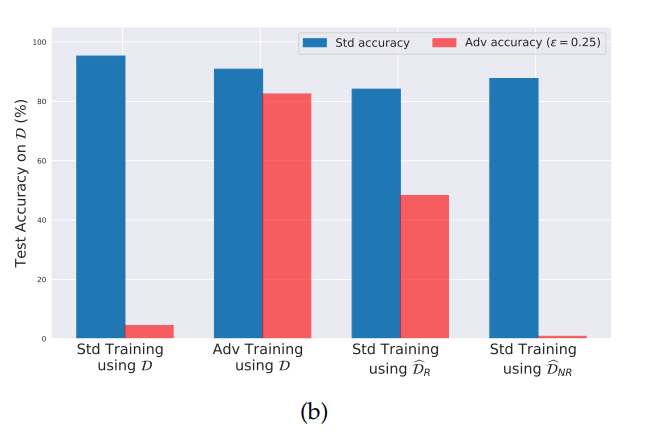
模型面對一般圖像(藍)與對抗樣本(紅)時的準確率。依照訓練方法與訓練資料集的不同組合,由左到右分別為:標準訓練/一般訓練資料集、對抗訓練/一般訓練資料集、標準訓練/僅包含穩健特徵的訓練資料集、標準訓練/僅包含非穩健特徵的訓練資料集。藍色直條與紅色直條越相近,顯示所訓練出的模型不易受雜訊干擾,也就是越穩健的模型。(圖片來源:Ilyas et al., 2019.)
編譯來源
A. Ilyas, S. Santurkar, D. Tsipras, L. Engstrom, B. Tran, and A. Madry, A, “Adversarial Examples Are Not Bugs, They Are Features,” arXiv.org, 2019.
參考資料
- C. Szegedy, W. Zaremba, I. Sutskever, J. Bruna, D. Erhan, I. Goodfellow, and R. Fergus, R, “Intriguing properties of neural networks,” arXiv.org, 2014.
- I. Goodfellow, J. Shlens, J. and C. Szegedy, “Explaining and Harnessing Adversarial Examples,” arXiv.org, 2015.
- F. Chollet, Deep learning with Python. Shelter Islands: Manning, 2018.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)