
手腕上的人工智慧

編譯/許晉華
輕量回覆模型
最初的構想源於2016年,當時研究團隊開始思考是否能將Allo與Inbox(兩者預計於2019年停止服務)上的自動回覆功能延伸應用到行動裝置上。但基於硬體需求的限制而作罷,決定從頭開始,重新設計出一套專為行動裝置所設計、全新、輕量級的機器學習架構。
最簡單的方法是建立一套自動查找系統:在裝置上建立一套收錄基本規則與常用對話的資料集,清楚定義「輸入」與「輸出」的對應關係。在接到訊息(輸入)後,透過「查字典」的方式,選擇適當的回應內容(輸出)。這樣的系統足以應付一些簡單的任務,例如我們希望由一句話判斷對方開心與否時,可以直接以人工標記的關鍵字,如「開心」、「喜歡」等資訊特徵做簡單的預測;然而應用範圍十分有限,尤其在一般生活對話中,所使用的字彙更多、更複雜。
而能夠處理龐大、複雜字彙的神經網路,如近年來較熱門的遞歸神經網路RNN(如LSTM等),若要部署到行動裝置上,勢必得將模型壓縮以符合行動裝置的硬體規格。只是如何壓縮而不減模型實用性,兩者間的平衡相當困難,也不符合成本效益。
投影學習模型
因此,研究團隊轉向其他更有效率的策略。首先,他們將語意類似的訊息組成群組,並以類似(專業術語為「nearby(鄰近的)」)的位元向量表示。這樣的轉換過程稱為「投影」,所採用的是改良過的「局部敏感哈希法」(Locality-Sensitive Hashing,LSH),可將數百萬個獨立字元降至一短且固定長度的位元向量,且無須儲存任何輸入訊息、詞向量,甚至連訓練模型也不需佔用記憶體空間;如此一來,系統便能迅速地將輸入訊息投影至對應的位元向量,相較於其他轉換表示法更加快速。
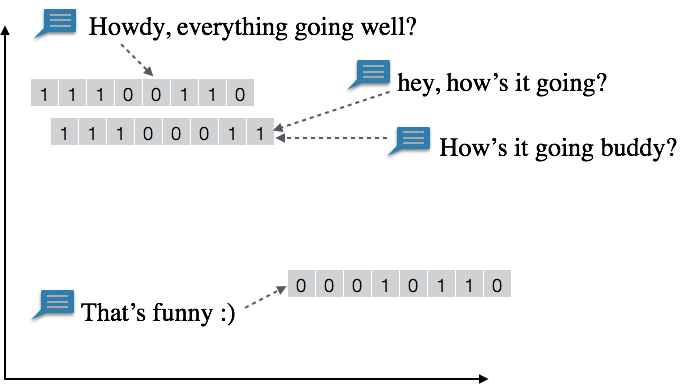
圖一、輸入的訊息被投影為位元向量。具有相同語意的語句,如「Hey, how’s it going?」與「How’s it going, buddy?」被投影為同一位元向量;語意近似的句子,如「Howdy, everything going well?」則被投影為「鄰近」的位元向量。兩者只有兩位元的差異。(圖片來源:S. Ravi, 2017.)
完成投影轉換後,系統會將輸入訊息和對應的投影向量用來訓練訊息投影模型(message projection model)。該模型的核心架構為團隊所設計的半監督式圖像學習(semi-supervised graph learning)框架,可以透過多種語意關係的組合,如:訊息─回應相互作用、單字─片語相似度、語意分群資訊等來訓練更強大的模型,並做出更準確的判斷,甚至可以模仿使用者的個人用語與說話風格等。
手腕上的AI
這種能直接於設備上獨立運行的系統,可第一手接收、處理使用者的資訊,直接做出預測與回覆,省去將資料傳輸到雲端或其他平台,運算後再接收的手續。
研究團隊表示,其實在藍圖規畫階段,大家都抱持著姑且一試的心態,畢竟Android穿戴裝置所搭載的運算資源和儲存空間相對有限,最終竟能訓練出這樣一個實用又準確的智慧回覆模型,其實相當出乎意料。他們也表示會繼續改進模型,最佳化運算效能,並訓練模型能提供更多樣化的回覆建議,帶給消費者更佳的使用體驗。
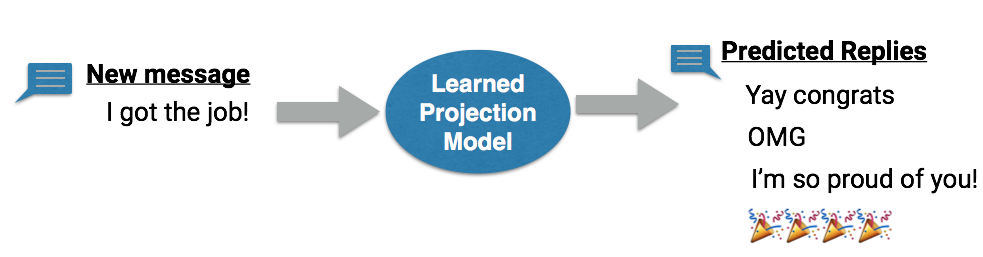
圖二、研究團隊表示,他們將訓練系統提供更多樣化的回覆建議。(圖片來源:S. Ravi, 2017.)
編譯來源
S. Ravi, “On-Device Machine Intelligence ,” Google AI Blog, 2017.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)