
機器學習與人工神經網路(二):深度學習(Deep Learning)

■戰勝圍棋九段的 Google AlphaGo 正是以深度學習作為核心。比起一般的機器學習,深度學習是如何有深度呢?
撰文|陳奕廷
ImageNet 是一個致力推動電腦視覺 (Computer Vision) 相關研究的組織,其收錄了千萬張照片,每一張都手動標明照片內的物品。ImageNet 每年都舉辦影像辨識競賽,來自各國學界和業界的團隊在其中一較高下,看誰的人工智慧最能準確地標註照片。2012 年之前,主宰排行榜的團隊主要都是使用經典的影像處理方法,分析並比較照片中的某些特徵。2012 年,來自加拿大的團隊採用「深度學習」,將錯誤率從 26% 大幅下拉至 16% [參1],成為當年冠軍。像一陣旋風一樣,從此大部分的團隊改用深度學習。如今,深度學習締造了 3.6% 的佳績,甚至比人腦的辨識率還要高!
●深度學習(Deep Learning)是什麼?
廣泛地說,深度學習是指具有層次性的機器學習法,能透過層層處理將大量無序的訊號漸漸轉為有用的資訊並解決問題。但通常提到深度學習,人們指的是一種特定的機器學習法─「深度神經網路」(Deep Neural Network)。
在同系列的文章我們曾經介紹過人工神經網路及其原理,它包含許多神經元,有些負責接受資料,有些負責傳遞資料。以手寫數字辨識為例,這個神經網路包含三層神經元,除了輸入和輸出層外,中間有一層隱藏層(意指不參與輸入或輸出,隱藏於內部),傳遞並處理資料。其實,隱藏層可以有一層以上,而複數個隱藏層的神經網路通常被稱為深度神經網路 [註1]。圖一B是一個深度神經網路示意圖,也許只有兩個隱藏層看起並沒有很深,但在實務上神經網路可以高達數十層至數百層,非常具有「深度」。
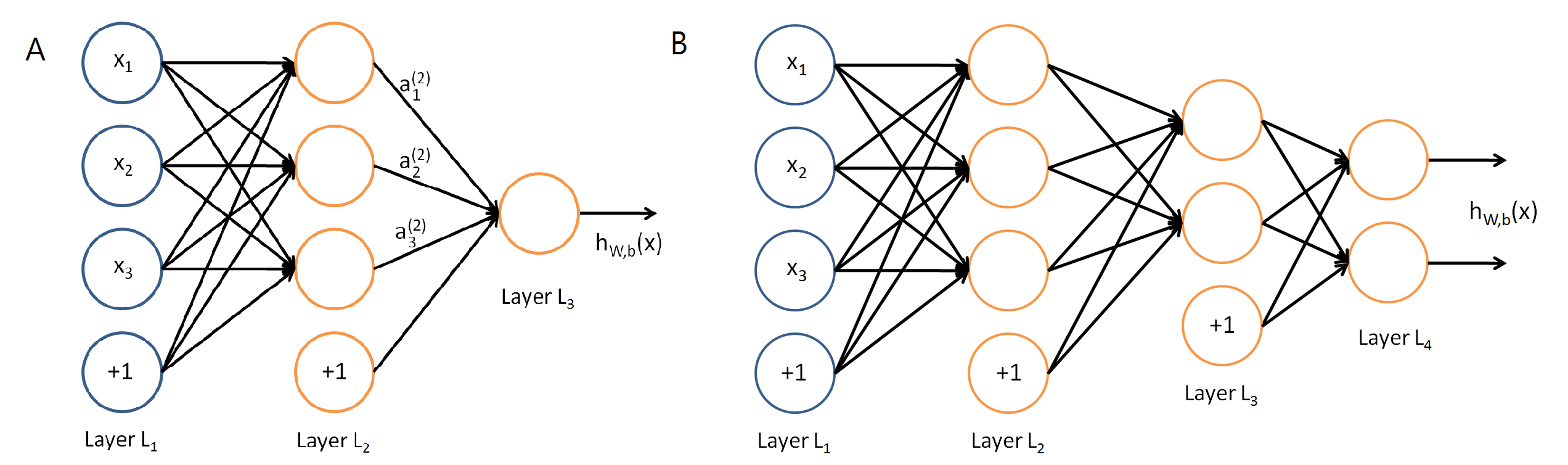
●為什麼需要深度?
從手寫數字辨識的例子中,我們提到的一個單一隱藏層的簡單神經網路就能達到97%以上的準確率,若加以改進,甚至能達到99%以上 [參2]。為何辨識照片經過多年的努力還是只有接近97%的正確率呢?首先,相較於只有28*28個像素的手寫數字,照片通常有500*500個像素。再者,手寫數字中每個像素只有0和1兩種可能,但照片卻有256種,而且RGB三色都需要這麼多。最後,數字只有0到9共10種可能性,而照片裡面的物品可以是任意的,幾乎有無限多的可能性。不管是輸入或是輸出,變數都巨大許多,也因此,我們需要尺度更大的神經網路。
尺度越大,代表的是神經網路中的神經元需要更多,但不一定代表需要更深的網路。同樣100個神經元,我們可以將它分為1層100個神經元,也可以分成10層10個神經元。科學家曾做過實驗,在一個語音辨識的測驗中,無論是淺的或深度神經網路,辨識率都隨著神經元數目的增加而成長。但是在相同數目的神經元時,深度神經網路的表現總是比較好 [參3],因此獲得廣泛應用。
●深度學習背後的祕密
其實,數學上可以證明,如果我們有無限多個神經元,任何深度神經網路都可以等效於一個單層的神經網路。但你我都知道,現實世界中不存在「無限」個
神經元。實務上,神經元越少越能降地計算成本,而深度學習能在這一點上幫助我們。
許多數學家曾嘗試解釋為什麼多層通常比單層好,至今仍沒有定論。美國哈佛大學和麻省理工學院物理系教授 Henry Lin 及 Max Tegmark 提出一個猜想 [參4],認為這和對稱性與結構性有關。大自然充滿著結構性:歷史由人構成,人由細胞組成,細胞由原子組成。在每一個階級都有不同的特徵,需要不同的理論來描述。就像儘管我們找出物理中的大統一理論,仍不能用此解釋川普為什麼會當選,而是需要政治學和社會學。
單層網路就像大統一理論,深度結構就像現有的學科架構。大自然也充滿著對稱性,例如在辨識人臉時,可以利用人的左右對稱。在單層的神經網路,左眼和右眼會被當作不相干的東西分開處理。但在深度學習中,神經網路可能就以眼睛作為一個特徵來比較,大大簡化計算的複雜度。這兩位教授認為,深度學習因為具有這些特質(圖二),相較於單層結構是一個比較接近自然的結構,所以表現優良。
![圖二:在人臉辨識中深度學習展現了結構性。 (來源:參考資料[5])](http://case.ntu.edu.tw/blog/wp-content/uploads/2016/12/Fig2.jpg)
[註1] 深度學習需要的隱藏層數目因人而異,並沒有嚴格的定義。有些人認為十層才算是深度學習;有些人認為一層就算是深度學習。
參考資料:
- Olga Russakovsky et al., ImageNet Large Scale Visual Recognition Challenge, Int J Comput Vis (2015) 115:211–252
- Michael A. Nielsen, Neural Networks and Deep Learning, Determination Press, (2015)
- Frank Seide et al., Conversational Speech Transcription Using Context-Dependent Deep Neural Networks, Interspeech (2011)
- Henry W. Lin et al., Why does deep and cheap learning work so well?, arXiv:1608.08225 (2016)
- Rene Meyer, Deep Learning Smarts Up Your Smart Phone, AMAX (2015)
--
作者:陳奕廷,台大物理系學士,史丹佛大學應用物理系博士班就讀中。
![]()