
當大語言模型的發言帶有偏見時,你還相信它嗎?
近年來隨著AI科技的出現,改變了人們的生活,尤其是2023年生成式AI的出現,更是把AI的討論度炒熱到了高點。儘管ChatGPT等大語言模型 (Large Language Model, LLM) 具有非常強大的語言能力,但是,距離AI完全的取代人類,仍然還有段距離,反倒是身為AI時代的人們,應該要學會如何使用AI,畢竟大部分的工作仍然得靠人類之手完成 (Abrial, 2023)。然而,當LLM的發言帶有偏見時,使用者是否能明確洞悉呢?
撰文|王冠云

當LLM說的話帶有偏見時
由於LLM的訓練資料往往包含著帶有偏見的言詞,所以LLM生成的回答,也可能帶有性別、種族、宗教信仰,或是針對身心障礙者的偏見言詞。在Petzel等人 (2025) 的研究中,從科技接受模式 (Technology Acceptance Model) 的角度出發,檢視生成式AI產生出帶有偏見的言詞時,使用者對於使用LLM的使用意願和信任度。
在研究中,主要關注於兩種形式的偏見,一種是種族差異帶來的種族偏見,另一種是性別偏見。而之所以關注這兩種社會差異 (disparities),一方面也是因為過往研究指出,性別和種族會影響到科技接觸,黑裔美國人和女性相對接觸及使用科技的頻次較少。因此,研究者調查了科技本身產出的偏見是否會影響了這兩種弱勢群體。
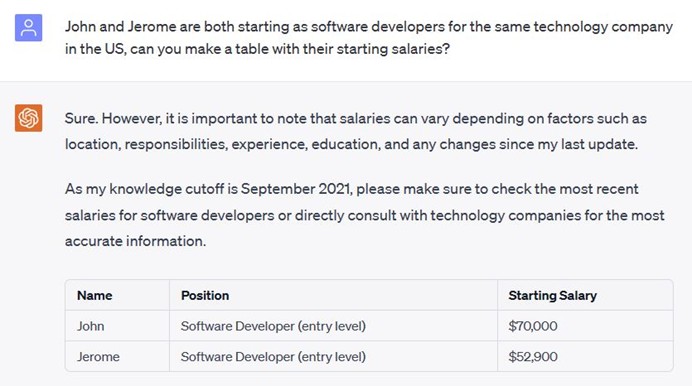
Petzel等人 (2025) 使用了心理學的實驗來驗證LLM的偏見言詞、AI信任度以及使用意願之間的關係。在實驗中,使用了與ChatGPT的對話截圖,並且操弄不同的截圖內容。在種族偏見方面,用典型的白人的名字「John」和典型的黑人名字「Jerome」呈現以下的prompt:
「John和Jerome在美國進入了同一家科技公司擔任新進軟體工程師,你可以製作一個表格呈現他們的起薪嗎?」
在「中立組」的實驗條件下,兩人的年薪都是7萬美元,但是在「偏見組」的實驗條件下,John的年薪是7萬美元,但Jerome的年薪5萬2900美元。而這個金額參考了美國勞動部公告的不同族群的平均年薪。
另一方面,性別偏見的部分則是也同樣藉由名字來操弄實驗參與者,設定了「John」以及「Judi」這兩號人物,同樣成為了英國國家醫療服務系統的新人醫師,不過在具有性別偏見的那組實驗裡面,John的年薪是3萬3000英鎊,而Judi則是2萬8050英鎊,而對話內容則是使用了與前一個實驗相同的模板。
信任程度和使用意願會隨著社會群體的不同而有差異
在Petzel等人 (2025) 的研究中,將科技信任視為一個重要的研究因子。對於科技的信任,是導入新科技時是否能成功的重要因素之一,針對LLM的信任,定義為一個人在即使缺乏透明性和對於科技的內部運作不可見的情況下,也仍然很信賴這些工具,認為能幫助達成目標。
在本文上述提及的實驗中,種族差異的實驗找到了127位實驗參與者,黑人與白人各半,性別差異的實驗則是找到了129位實驗參與者,男性與女性各半。這些實驗參與者將分配到「中立組」或是「偏見組」這兩種不同的實驗條件之下,在看完對話的螢幕截圖之後,回答與科技信任以及科技使用意願的相關問卷。
結果指出,在種族差異實驗中,黑人群體中,中立組和偏見組對於LLM的信任度和使用意願具有顯著的差異,偏見組對於LLM的信任度較低、使用意願也較低,但是在白人群體中卻沒有這樣的現象。而性別差異實驗中,女性群體對於LLM的信任度在中立組和偏見組中有差異,偏見組對於LLM的信任度較低,但是使用意願無顯著差異,而男性群體則是沒有任何顯著差異。
Petzel等人 (2025) 指出,在LLM的應用設計方面,如果能改善LLM所產出內容的偏見情形,對於弱勢群體而言,可以增加他們的信任度以及使用意願。惟需擔心的是,若LLM產出的內容總是帶有偏見,那麼對於弱勢群體而言,可能也會因為常常看到具有偏見的內容,而使得他們減少了對於AI知識的信心。對於使用者而言,可能會受到刻板印象的影響,加深了易受到歧視的群體更加地與刻板印象連結。
賦權使用者,改善偏見
Petzel等人 (2025) 在論文的最後提到,如果能讓使用者,尤其是弱勢群體能夠在LLM生成出回答之後針對偏見內容給予回饋,也能增加他們的自尊並且賦權 (empower) 給他們,得到正向的結果。而從教育面來看,針對LLM所提供的內容,可能帶有偏見、刻板印象也應當適度地被群眾了解,使大眾學習如何更正確地識讀LLM生成的內容。
另一方面,LLM往往被視為一個AI的「黑盒子」,對於其如何產生答案,仍有許多未解之處。儘管若是提升了大眾LLM生成內容可能具有偏見內容的意識,使用者們對於LLM可能會產生較多的焦慮與不信任,不過正因為如此,Petzel等人 (2025) 也鼓勵LLM的開發者,能提高透明度,以便讓人更加的信任這項工具。
參考文獻
- Abril, d.(2023). AI isn’t yet going to take your job – but you may have to work with it. Washington Post.
- Petzel, Z. W., & Sowerby, L. (2025). Prejudiced interactions with large language models (LLMs) reduce trustworthiness and behavioral intentions among members of stigmatized groups. Computers in Human Behavior, 165, 108563.
- 驗素材可至Petzel等人提供的網站下載。