
考試都考100分?測驗AI智慧的新試題

編譯/許守傑
Winograd基模挑戰
人工智慧到底有多聰明?這個問題自AI發展以來就不斷地挑戰著電腦科學家們,希望能夠設計一套測驗來衡量機器的智商,著名的涂林測試(Turing test)即為這類評鑑的始祖。隨著技術演進,多倫多大學電腦科學家Hector Levesque於2011年提出了「Winograd基模挑戰」(Winograd Schema Challenge,WSC)──其中包含273組由專家特別設計過的選擇題組──試圖取代傳統的涂林測試。然而時至今日,各式各樣自然語言處理模型在這組試題上都已經能夠達到約90%的高準確性,讓科學家們不禁開始懷疑:這些機器學習模型能考到90分,究竟是真正反映了模型的能力,抑或其實只是把題目硬背了下來?
為了解答這個疑問,專家們想出的方法很簡單:如果考太簡單測不出AI的程度沒關係,那就再考一次,而且考難一點!2019年美國華盛頓大學的Keisuke Sakaguchi等研究員發表了一個全新的單選試題集──WinoGrande,在原先WSC的基礎上將內容擴充至4萬4千組選擇題,無論在規模或難度上都更勝一籌。
如何設計新考題
WinoGrande的題目主要來自於群眾協作,參與的協作者需寫出符合WSC要求的兩組句子,符合避免單詞相關、句子不完全相同但需盡量相近等規則,內容橫跨社會與物理常識兩大範圍。此外,Sakaguchi等也限制協作者必須從WikiHow網站中的文章中隨機選擇有意義的錨詞(anchor words,僅會在特定主題中出現的字詞)來創造測驗句,大大提昇了測驗集的創意和主題的多樣性,並且蒐集而來的測驗句會再透過群眾進行嚴格的人工驗證,初步篩選出適用的題目。
然而經過上述的步驟後,試題集中的文字可能仍然存在某種程度的統計偏誤(bias),使得機器在訓練過後可能藉由詞與詞間的關聯性就可以推出答案,而不是完整地了解測驗句的意思。舉例來說:
題目:猴子喜歡玩球而忽略積木,是因為牠覺得它很有趣。請問「它」指的是?
選項:1. 球;2. 積木
答案:1. 球
對於模型而言可能就會形成一個機率上「喜歡-有趣-球」三個詞彙高度相關的模式(pattern),因此往後只要看到「喜歡-有趣」這些文字,就會反射性地回應:「球」。這樣具有高度關聯性詞彙的測驗句即屬於有偏誤而讓模型不求甚解的填鴨題,必須盡量減少,因此Sakaguchi等特別設計了「輕量對抗過濾演算法」(Light-weight adversarial filtering,AFLITE)來過濾掉這類題目。
AFLITE演算法的概念是將題目隨機分成幾個群組,再將每個群組一分為二,分出訓練集和測試集後,用訓練集來訓練一個答題分類器。如果分類器在回答某題時,算出某個選項有很高的機率是這題的答案,代表這個句子和答案對統計模型有很高的辨識度,就會被過濾出而從題集中淘汰。簡而言之,就是使用低階分類器當做基礎的答題系統,並藉此找出簡單的題目後將這些題目剔除,減少整體試題集的統計偏誤,進而讓WinoGrande能夠更精準地測驗出模型的聰明程度。
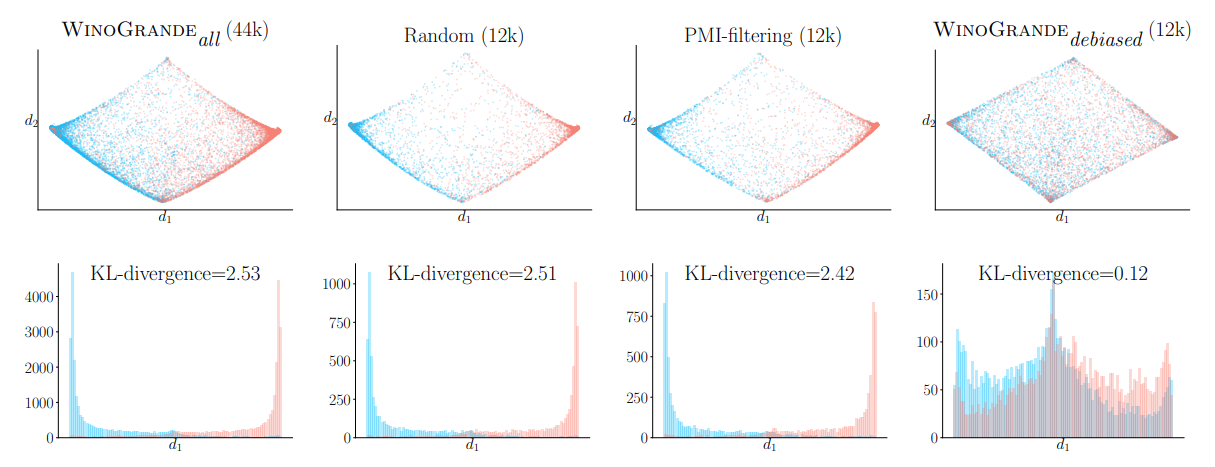
使用AFLITE演算法去除偏誤後的效果,可以看到篩選過後的WinoGrande題集在KL散度上較為平均。(圖片來源:K. Sakaguchi et al., 2019.)
新考題的成效
在設計出新考題後,Sakaguchi等也對各種曾經在WSC獲得好成績的機器演繹模型──如Wino Knowledge Hunting、Ensemble Neural LMs、BERT、RoBERTa──進行測試,結果發現各模型測驗出來的成績確實降低了不少。其中以RoBERTa表現最好,但準確率也僅有79.1%。顯示WinoGrande相較於WSC能更進一步鑑定各模型的能力。另外,人類的WinoGrande測驗成績是94%,代表現階段的測驗對人腦而言還是相當簡單,但對機器仍然具有相當的難度,顯然目前AI要追上人類還有許多可以努力的空間。
WinoGrande的誕生與過去數十年來人工智慧社群建立測驗集的方式不同且更精緻,其中所提出的方法很值得各個領域借鏡,尤其當技術飛快突破和演進時,我們也需要為AI準備難度適當的挑戰,才能一起學習、成長。
編譯來源
K. Sakaguchi et al., “WinoGrande: An Adversarial Winograd Schema Challenge at Scale”, arXiv.org, 2019
參考資料
- H. Levesque et al., “The Winograd Schema Challenge”, AAAI, 2012.
- R.L. Bras et al., “Adversarial Filters of Dataset Biases”, arXiv.org, 2020.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)