
不用看字典,機器也能學語言
臺灣大學生醫電子與資訊學研究所 葛竑志
淺談RNN(Recurrent neural network)
相較於以往單一輸入、單一輸出的模式,這種模型更強調在具有承接關係的資料上。舉個例子,通常只要提供足夠的字彙,機器便可以輕易地學習到Input中的特定字與Output的關係,但這在一串句子的情況下就不同了。我們必須注意到,關鍵字外還有許多形容詞、副詞及片語修飾著本來的字,這很可能就會讓語意完全不一樣了。何況像是處理語音、影片等等更複雜又連續著的資料,更必須去設計一種能保留這種承繼關係的方法。
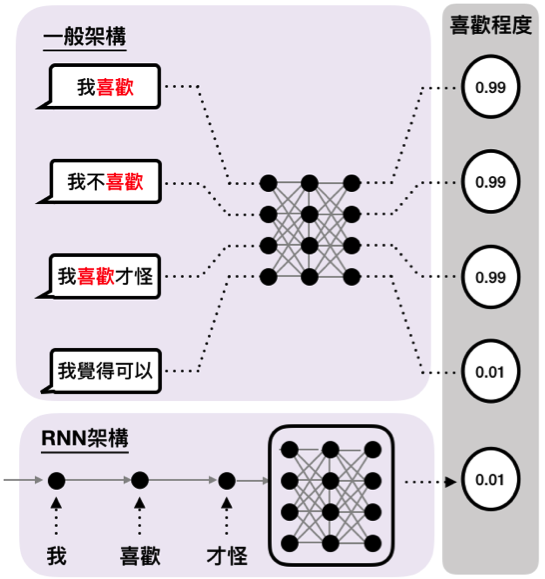
圖一、傳統機器學習架構很可能會忽略前後文的關係,導致產生截然不同的結果。使用RNN架構依序接受資料,可以幫助釐清文意。 (圖片來源:譯者自繪)
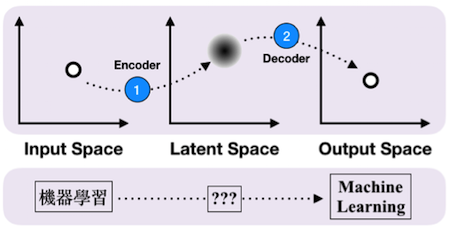
RNN的世界中,主要是將這些資料看作是沿著時間軸變動的Feature,使用了多個特殊的單元(如GRU、LSTM)能夠在讀入某個時間點上的Feature的同時,不失過去所紀錄的資訊。從資料的開始直到最後一個時間點為止,這段過程所使用的單元們總稱作「編碼器(Encoder)」,透過這種Encoder得到的產物,可以看作是個潛在空間(Latent Space)的向量,將代表著這段時間內的資訊,傳遞至更後面的神經網路。
Encoder與Decoder組合成Sequence-to-Sequence
前面提到,能將資料轉換至Latent Space的工具叫做Encoder,其實還有另一種功能反過來的工具,稱作解碼器(Decoder)。將兩者組合在一起,就是Seq-to-Seq的基本形式,能夠用來處理Input和Output都是承接性序列(Sequence)時的情況。或許聽起來複雜,但其實常見的語音輸入、聊天機器人以及本篇提到的語言翻譯,全都是建立在這樣的基礎上。
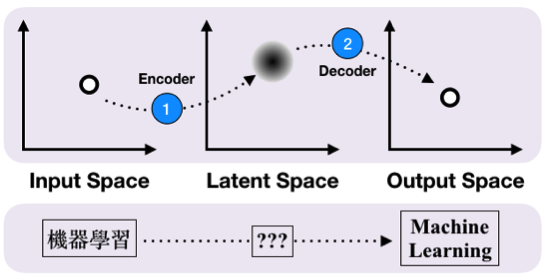
圖二、Seq- to-Seq基本架構 (圖片來源:譯者自繪)
翻譯模型的設計
當然翻譯沒有想像中地簡單,語言有時過於自由,有時也無從知道模型學習到了什麼,而這時候使用「回譯」(Back-translation)與「降噪」(Denoising)技巧,將有助於學習。
我們已經知道Seq-to-Seq做的就是藉由Encoder和Decoder,將資料在不同空間中轉換。因此可以直覺地想到,一個從Input space被轉換到Latent space上的資訊,經由Decoder轉換回Input space時,應該要能越像越好。這就有點像把翻譯過的句子再翻譯回原本的語言,意思不能差太多才對。

圖三、回譯的概念,Auto-encoding使用一組編解碼器,Cross-domain則使用了兩組,兩者皆必須盡可能地讓回譯的結果接近。 (圖片來源:譯者自繪)
另一方面,一條句子裡面可能充滿了不重要的語助詞或同義字,這都會被視為是噪音(Noise)。在訓練的過程時,為了避免模型容易被Noise影響,會在資料前處理的階段就隨機抽掉幾個字或是做重新排列(通稱「加噪」),再送入模型中。經過這步驟訓練出來的模型,比較能看出大片段的語意,所以表現通常較佳。
監督(Supervised)與非監督式(Unsupervised)學習
事實上,大多數的機器學習都屬於前者,也就是模型根據投入資料提出預測,對照真實答案,再回頭修改參數的過程。後者則是沒有真正的答案可讓機器做比較,那這樣如何實現學習的效果呢?
其實這是有可能的,稍微觀察一下語言的脈絡,就會發現字彙聚集的方式通常很類似,如同「椅子」的附近就容易出現「桌子」,這無論是何種語言都能看出類似的現象。若機器將這樣的相關性描繪成一個巨大的地圖(如同前面提到的Latent space)——字彙是城市,它們之間的相關性是道路,那麼就算是不同語言,這樣的圖集應該也會很類似。只要藉著演算法尋找這種「語言地圖」的最佳映射方式,這麼一來,句子的脈絡就可被簡化成路線問題,翻譯也只是讓圖上城市的名字不一樣罷了。
為將概念付諸實際,各自從input及output在latent space上產生的向量間存在著對抗項(Adversarial term),是為了讓兩個不同Encoder輸出的向量足夠接近,盡可能使模型無法分辨這個向量是來自於input還是output。最後只要結合前面所提過的損失項,便可以得出整個模型的損失函數(Loss function),在訓練過程中提供參數調整的方向。
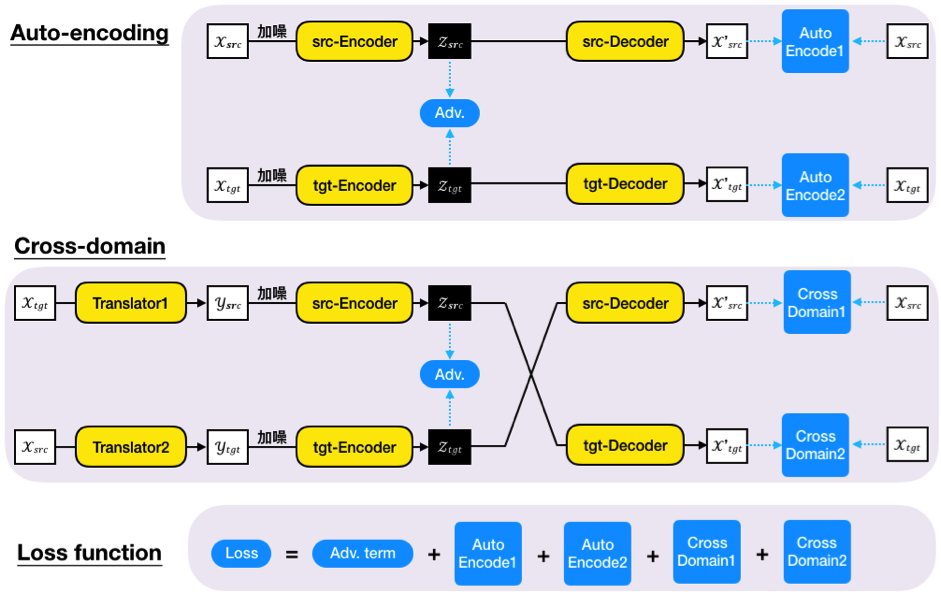
圖四、非監督式學習法結合Seq-to-Seq架構 (圖片來源:譯者自繪,參考自[1])
表現不差亦不是最佳,被認為有潛力可以做得更好
以最常用來衡量翻譯品質的BLEU(Bilingual Evaluation Understudy)評估,這種架構大概能從滿分100之中得到15分,相較於Google翻譯——監督式學習方法能達到的40分低了不少(一般人大約能夠達到50分)。儘管如此,作者認為這可以透過半監督(Semi-supervised)的方法得到改進,也就是預先提供數千個平行文本作為訓練集,再放手讓機器去學習。
縱使在沒有人監督的情況下,機器還能夠學習翻譯,這真的是很令人震驚的結果,Di He這麼說。他是個微軟的電腦科學家,這兩篇文章都多少受到了他之前的研究影響。這種非監督式的翻譯方法還只是剛開始,距離能夠被應用還有一大段距離要走,卻可能有機會去取代一直以來被視為主流的學習方法。
編譯來源:Artificial intelligence goes bilingual—without a dictionary Matthew Hutson, Science, 2017
參考文獻
- [1]Guillaume Lample, Alexis Conneau, Ludovic Denoyer, Marc’Aurelio Ranzato, “Unsupervised Machine Translation Using Monolingual Corpora Only”, 2017
- [2]Mikel Artetxe, Gorka Labaka, Eneko Agirre, Kyunghyun Cho, “Unsupervised Neural Machine Translation”, 2017