
像人類一樣學習

編譯/陳儁翰
機器學習
現有的機器學習仰賴人類提供資料作為輸入,電腦經過運算後得到輸出,將輸出與已知結果相比較,然後回過頭來修正自己的模型。例如我們將一堆貓、狗圖片給電腦,讓電腦來判斷特定某張圖中是不是一隻貓。若圖片裡明明是一隻狗,電腦卻判斷為貓,電腦看完正確答案,知道自己搞錯了,於是自動修正模型。判斷、比對再修正,一來一往之間,隨著次數增加,正確率也逐漸提升。
在上述過程中,機器是否學到一些新概念呢?有的,機器學會了:貓的輪廓、貓的臉部或身體紋路等特徵,於是利用這些線索判斷圖片中的動物。這類機器看似沒有任何問題,事實上也足以解決許多問題,但是當情境越趨複雜,難度也相對提升時,問題就出現了:這些新習得的概念,在機器下次遇到類似情境時,無法被靈活運用,解決新的問題。
強化學習
另一種機器學習的變體─強化學習(Reinforcement Learning),則是在原有的架構上,再加上獎懲機制:由人類訂立一個標準,透過積分(達到標準,加分;未達標準或失敗,扣分),獎勵(或懲罰)機器人向我們所期望的目標邁進。假設我們希望機器人自己學會走路,以機器人用以觀測周遭環境的感知器作為輸入,輸出或許是各個關節的位置,人類可以在編程時內建一個獎勵機制:在一段時間內,若機器人的移動距離越長,則加分;若倒下,則扣100分。機器透過與這個世界的互動以及人類預先設定的獎勵機制,從而學習到當接收特定輸入時,應如何做出相應的回應。
在這樣的過程中,因為機器人的隨機探索,或許有可能學會意料之外,卻又很有效率的方式來解決問題。只是強化學習是以目標為導向,若我們希望機器人以同樣的方式解決其它問題,比如說學會跳躍,勢必變更所設定的目標與獎懲,再次訓練。只是當欲達成的目標越趨多樣且複雜,例如我們希望機器人可以聞樂起舞時,這樣的方法顯得緩不濟急,也不切實際。此時,假如機器人可以學習各種概念,並在適當時機使用不同的概念,是否會是一個更好的選擇?
概念的延伸與應用
幸運的是,這並不意味著我們必須完全拋棄既有的機器學習或是強化學習方法。我們需要的是一個框架,一種能將機器所學到的所有概念整合在一起,並視適當時機使用的框架。私人AI公司Vicarious的研究團隊便是在這樣的構想下開發了一套新的概念學習框架。
這樣的機器人包含視覺系統、動力學模型、工作記憶、控制器,以及基本的指令集。「視覺系統」負責物件感知,結合「生成模型」、「動力學模型」,使得機器擁有抽象思考,想像動作與物體間關聯的能力;「工作記憶」則依據物件的顏色、位置等資訊,將資料結構化管理,使得機器有對任務的記憶能力;「基本指令集」則是構成新概念的必須基本單元,多個基本指令組成一個概念。
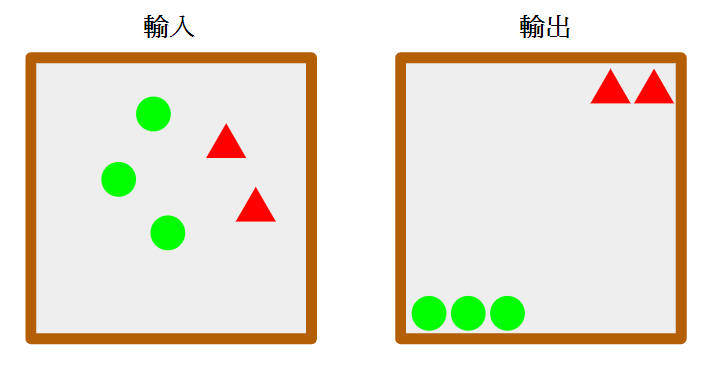
(來源:M. Lázaro-Gredilla et al, 2019.)
以上圖為例,左圖是物件一開始的分布,右圖是我們希望最終的物件排列方式。「視覺系統」會負責將輸入和輸出的圖像數位化,讓這些資訊可以為電腦使用,並根據機率與過去的經驗來判斷應使用哪一項基本指令,才能透過搭載攝影鏡頭的機械手臂,將物件移動到適當位置。
所謂「基本指令」可能是抓取物件、移動到特定位置等相對高階的動作指令。一連串可以完成該任務的指令,則會形成一個新的概念。根據研究人員的測試,機器甚至能夠結合多種概念,在各種干擾下依舊完成任務。
擁有高階概念的學習以及基本推理能力,除了將龐雜的物件偵測與機械運動等細節,以指令包裝並形成概念,簡化了模型的複雜度,使得機器可以展現更複雜的行為外,也大大拉近了人類與機器間溝通的鴻溝:人類不但可以透過給予一連串的高階指令引導機器,機器的決策也能以高階概念的形式為人類所理解。
編譯來源
C. Burns, “Robots—like people—use ‘imagination’ to learn concepts“, Science | AAAS, 2019.
參考資料
- M. Lázaro-Gredilla, D. Lin, J. Guntupalli and D. George, “Beyond imitation: Zero-shot task transfer on robots by learning concepts as cognitive programs“, Science Robotics, vol. 4, no. 26, p. eaav3150, 2019.
- D. George et al., “A generative vision model that trains with high data efficiency and breaks text-based CAPTCHAs“, Science, vol. 358, no. 6368, p. eaag2612, 2017.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)