
迎向人工智慧的燦爛陽光─由教機器聽人類語言說起

講者/李琳山(台大電機及資工系教授)|彙整/陳育婷
整理自2019.02.13〈錢故校長思亮111歲誕辰紀念學術演講〉
人工智慧到底哪裡勝過人類?
機器其實只在兩件事情上遠勝人類─大量資料的記憶及快速運算。不論過去或現在,機器都只會做這兩件事。至於如何進行,則是由人類透過程式下達指令。所以,機器其實只是依循著開發者所建構的模型與演算法按表操課。例如:類神經網路試圖仿照人腦處理資訊的方式,大量可調整的參數讓機器可以在巨量數據中,看到人眼所看不到的蛛絲馬跡與不曾察覺的規律。靠著這樣的模型,機器能夠活學活用,但仍不離記憶與運算兩大範疇。所以,科幻小說中所描述能反過來統治人類的強人工智能並不會發生,因為機器無法脫離人類的指令做事。但是,我們仍必須思考如何將其用在好的地方,權衡利弊,否則機器仍可能被用來傷害人類。
不過,既然人工智慧自始自終執行的任務都大同小異,為何直到現在才蓬勃發展?這是受到早期軟硬體及網路的限制,運算與儲存能力有限;隨著軟硬體演進以及雲端資訊的出現,巨量數據的儲存、使用與分析及巨量運算變成可能,搭配無遠弗屆的網路,人工智慧才得以如虎添翼,一飛千里。
聽懂人類的語言
李琳山教授的專長在於語音辨識。1980年代,當時還是大鍵盤中文打字機的天下。教授剛回台灣沒多久,便決心投入華語語音辨識的研究。從金聲一號到金聲三號,從一次只能輸入一個音,並且速度緩慢,到能做到連續語音輸入,速度也加快許多,教授可說是全球華語語音辨識的先驅,對於台灣及華語世界的貢獻卓著。2011年蘋果公司推出的多語言語音個人助理,其中華語語音的基礎架構幾乎和教授當年建立的如出一轍,展現教授對華語語音辨識研究的開創性與完整度。這些看似顯赫的成就,背後可是有著道不盡的艱辛。
基本的語音互動流程可以簡化為下圖(圖中所有機能皆在雲端):
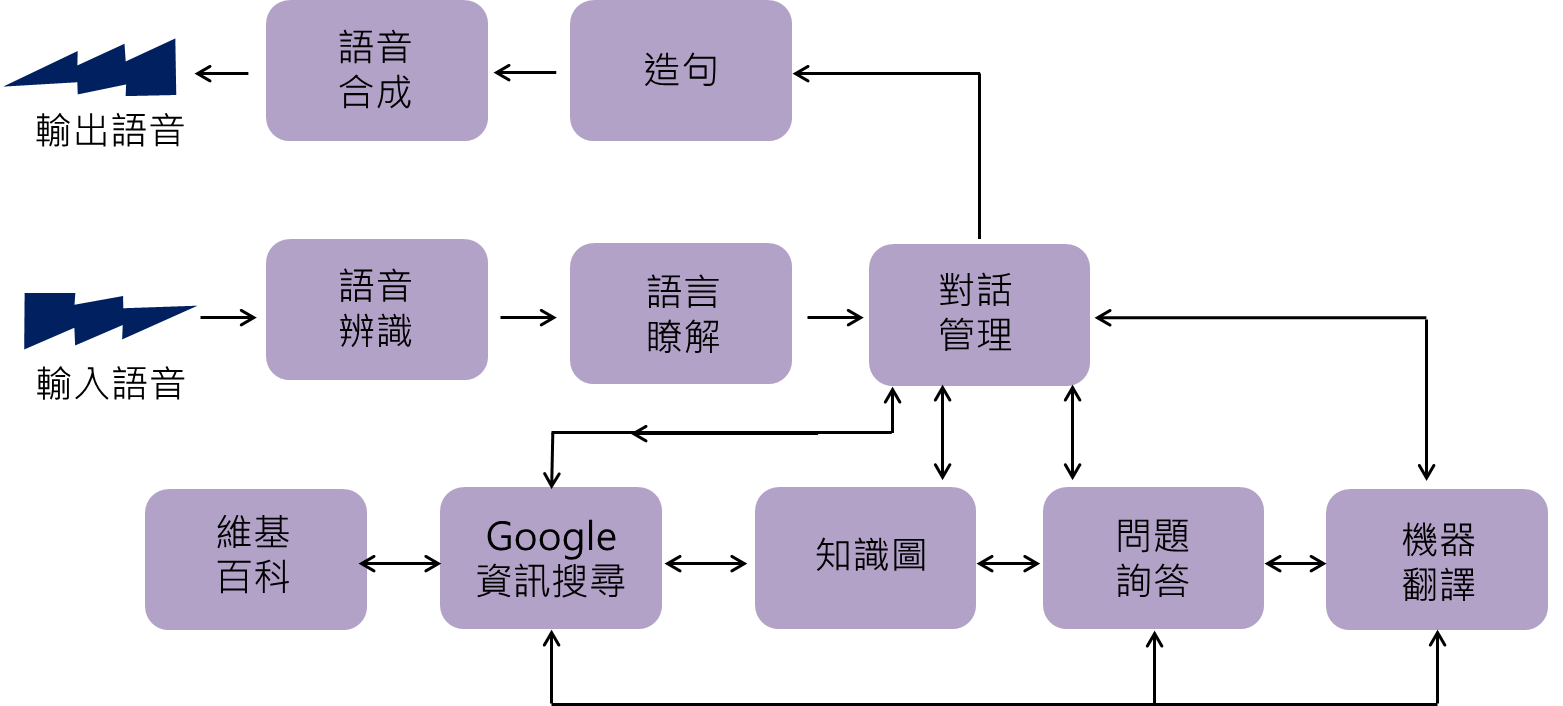
語音輸入後,除了要正確辨識說話者所說的話,也要理解句中的詞彙、句法及語意等,並透過資訊檢索得到問題的答案,再將答案由文字轉化為語音後輸出。這也是平常我們向Siri尋求幫助時,Siri必須經歷的過程。我們與語音助理短短幾秒的互動,背後其實錯綜複雜、環環相扣,只要其中一個環節的模型出錯,便可能造成答非所問的窘境。
華語的挑戰與困難
而華語語音辨識,相較於英語,因為獨特的語言結構而有一定的差異:不但是一字一音,而且每一音可以對應許多同音字,且各有不同意義,徒增語音辨識到語意理解的難度。再者,華語是聲調語言,不同聲調更代表不同的字與意義,例如:衣食/遺失/軼事/意識、程式/城市。雖說華語的組成單位與英語類似,但華語文句中詞的邊界不明確,並且可以更自由地調動句中詞的順序與位置,這些都是華語語音辨識必須獨自克服的難處。
知識爆炸的年代
21世紀是人工智慧蓬勃發展的世紀,許多研究者直接將最新的研究發現含程式碼張貼在網路上,只要學生夠聰明、用功,就可以立刻接觸並學習最新技術。站在巨人的肩膀上,不再是牛頓的專利,而是人人只要有心便唾手可得。
最新研究結果與演算法充斥網路,線上也不乏名校大師的課程,無限量幾乎免費的知識更印證「將相本無種」,單憑個人修行。而過去困難的跨領域研究,在現今門檻也已大幅降低。知識自由流動,與人工智慧相輔相成,不論產學皆能自由探索人工智慧的應用潛力。開源程式碼、大數據及雲端服務使科技產業瞬息萬變,現今多數成功企業,無論大小,多少與人工智慧有關。
李教授認為:人工智慧將來未必是一種專業,尤其在程式碼的編寫納入義務教育後,門檻會很低,或許國高中就可以應用人工智慧於日常生活中;但是,相關基礎研究仍會是專業人士的天下,持續研發最新技術。
鑑往知來
最後,教授提到對人工智慧的展望,坦言他想不到任何領域用不到人工智慧,也想不出多少年以後會歸於沉寂。若以人的一生作比喻,現今人工智慧只是呱呱墜地的嬰兒。然而在資本主義社會中「產業帶動科技」的前提下,人工智慧的興起卻是無法改變的事實與趨勢,任誰也無力阻擋。我們應該思考的是:面對人工智慧的年代,我們應如何因應,方能與其一同前進?畢竟,唯有迎向陽光,才能晴空萬里。