
寵物攝影機提供另類學習法

編譯|葛竑志
很多主人會在自己的寵物身上裝個攝影機,來看看自己家的狗狗貓貓是怎麼度過牠們的一天。你有想過這種影片除了具有窺探寵物隱私的功能(咦?),還能夠做什麼嗎?最近有一篇投稿至ArXiv的文章,表示他們還能夠使用這些影片,在一些情境下模擬機器狗的動作。
人們常自然而來地把自己的觀點帶到其他生物身上,私以為狗狗搖尾巴代表開心,貓咪折手手是信任你,在玩弄寵物的時候,有人有想過寵物的感受嗎?這裡不是要談濠梁之辯,但是得去思考一下,傳統上,當我們想要模擬動物的行為時(仿生機器人),都是依據套好的刺激與動作下去建模,如此人工的模型是否會偏離了動物真實的習性?相對的,這篇文章的作者則提供了不同的學習角度,試著為動物的行為模式賦予意義。
●以動物做為題材並不少見
就讀華盛頓大學的Kiana仔細地幫一隻阿拉斯加雪橇犬穿上各種裝備,在牠的背上固定了一台GoPro之後,就讓飼主帶著牠到處散步。相機記錄著牠走過河岸,晃過交叉路口,奔跑在草地上,跟各種路人互動再回到小窩的一天。在這之後的事情也不複雜,就是取出記憶卡,把資料送進機器裡進行訓練。
像這樣的影片資料集,可以追溯至2014年由九州大學團隊建立的"DogCentric Activity Dataset"。他們搜集了幾個寵物狗身上的影片,由人工標記狗的各種動作後,就送到機器裡訓練出一個能做動作辨識的模型。Kiana的團隊同樣也建立了一套名為"DECADE"資料集,從字面上的意思來看,資料集便是以狗的視角出發,設法切入牠們自我中心(ego-centric),了解這樣的一個智慧生物是如何在真實世界中與環境互動。

身為電腦視覺研究者的他們稱這些寵物叫作「具有視覺智慧的個體」(Visually intelligent agents)。是因為他們的行為比人類簡單許多,也不像人們在行為出現之前會想很多,此外,透過與其他個體的互動,又能做出一些更複雜的行為與反饋。在電腦視覺的進程邁入更複雜的任務之前,從寵物身上做模擬應該會是個較佳的選擇。
●建立資料庫的考量
除了在狗的頭上安裝一台GoPro,他們也讓狗兒穿上一套安裝著加速度計和陀螺儀的衣服,用來記錄牠身體、關節、四肢的相對移動量。「首先,這種設計必須夠堅固耐用,能承受住狗的所有動作和甩動,再來也得夠輕薄舒適,確保這樣的紀錄方式不會影響到狗本來的習性。」

●非典型的監督式學習法
機器學習應用在電腦視覺上早已行之有年,多數時候做的還是相當特定的任務,像是物件辨識、數值估計等等。這類任務相對而言很好去做定義,諸如標記的是非對錯、區分類別又或是代表的數值,只要有足夠的資料對,選擇適合的損失函數,都很容易評估學習的確效。相反的,這種模擬狗行為的任務卻是複雜許多,也不易評估,那為何他們團隊仍要嘗試呢?
他們的想法是這樣的。一般來說,傳統電腦視覺的訓練任務都要準備數以萬計的圖片或影片,過程中確保資料的一致性、進行前處理等等還算是小事,麻煩的是每張圖片還需經由人手一一做標記,才能在監督式學習的架構下教導機器做出跟人一樣的判斷。為此,有些人提供了非監督式學習的辦法,但往往效果不比本來的方法好。
他們則想到,這些標記(Label)事實上是一種人工的代理作業,而忽略了本質上產生標記的意義——從人們產生的客觀事實認為狗在做某種動作,但狗的主觀感受可能會是截然不同的。在這樣的出發點下,團隊索性不對動作做任何標記,而是直接利用狗的習性對機器做監督式學習,也就是提供刺激(狗的視野)與反應(肢體動作),訓練機器來模擬出狗會做出的動作。
●令人驚豔的結果
考慮到狗的行動應該具有避開障礙物的考量,Kiana等人實作了一項被稱作「辨識可行走區域」的任務,要求機器標示出影像內的可行走區域,並與真實區域做重疊比較。他們發現使用ResNet-18(一種CNN架構)在DECADE上訓練出來的結果,比起使用同樣的模型在ImageNet(圖片資料庫)上的結果高出了3%。
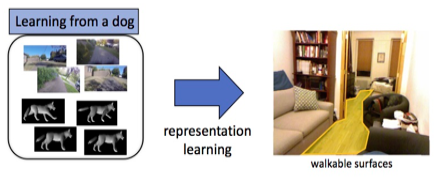
關於Kiana團隊的下一步,他們認為AI的核心議題還是如何將模型朝一般化方向推進。也許是多進行在不同品種上的實驗,也許還需要許多志願者的幫助,只要在狗兒身上安裝一些設備,主人只需要多跟牠玩,出去散散步就能夠持續讓模型變得更好。
編譯來源:Jeremy Hsu. “Dog Cam” Trains Computer Vision Software for Robot Dogs. IEEE SPECTRUM. 18 Apr 2018.
參考資料:
[1] Kiana Ehsani, Hessam Bagherinezhad, Joseph Redmon, Roozbeh Mottaghi, Ali Farhadi. Who Let The Dogs Out? Modeling Dog Behavior From Visual Data. Mar 2018.
[2] Yumi Iwashita, Asamichi Takamine, Ryo Kurazume, M.S. Ryoo. First-Person Animal Activity Recognition from Egocentric Videos. ICPR 2014.
[3] DogCentric Activity Dataset
[4] dogTorch
![]()