
【生活統計】IMDb幫你選好片-Bayesian estimator的直覺解釋

撰文|王悅
我們看一部電影,都可以依自己好惡上網評價。就像問卷一樣,評價方式通常是以等級0-10進行評價,0表示最不喜愛,10表示最喜愛 (有時也可以加上小數點),藉此等級區分電影排名。現在問題來了,如何只用簡單的一個數字表達眾人對一部電影的評價而不遺漏太多資訊?直覺的想,可能是平均值吧。將大家對一部電影的評價平均起來就行了。但樣本少時平均值較容易受到極端值的影響而失真。再不然就使用中位數,除了可以展現多數人的評價等級,也不輕易受到極端評價影響而變動 (統計學有個專業術語『穩健』藉以形容此現象),但中位數的估計效率 (efficiency) 較平均值來得差。效率低則估計值的變異較高,也就是估計值較不穩定。IMDb (Internet Movie Database) 的Top 250排名,採用的方法既不是一般的平均數,也不是中位數,而是Bayesian estimator (IMDb稱之為true Bayesian estimate,一樣的意思,都是貝氏統計的估計方式)。
IMDb Top 250使用Bayesian estimator的評價計算方式如下: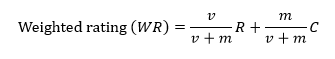
其中,WR是透過Bayesian estimator計算出眾人對該電影的評價、R為此電影的評價平均、C是所有電影的評價平均 (目前為7.0)、v是對該電影進行評價的人數、m是前250名電影中至少要達到的評價人數 (目前為25,000)。
其實,操作起來就像是種廣義的平均值,只不過做了一點手腳。什麼手腳呢?一部電影進入IMDb Top 250之前,會過濾是否有足夠多的人數評分,且預設有25,000的假人給了7.0的評價 (m = 25,000,C = 7.0),從這邊我們可以知道,基本的評價並不是從0開始,而是從所有電影的評價期望值 7.0 開始。這樣一來,IMDb Top 250 一共架設了雙重把關,第一個是評價人數在足夠多的情況下才能進入排名;第二個則是進入排名後會再受到25,000個假人的中間評分影響,這兩個把關都直接使得少數極端值不會對平均值造成影響而失真,其中第二道把關顯示了Bayesian estimator的優點:
- 不易受極端值影響
- 由於計算方式就像廣義的平均值,Bayesian estimator保留了效率較好的性質
除此之外,為維護評價的客觀性,IMDb 也設計了評價次數足夠多的使用者評分才會被納入計算的篩選機制,進一步確保了評價的公正性。
在資訊不足時,眾人對電影的評價只能依照以往所有電影平均評價7.0進行設定,這是我們對這部電影的先驗知識 (prior knowledge)。隨著時間的推進,觀眾對於電影的真實感受將慢慢修正先驗知識而主宰平均評價的走向,當IMDb評價足夠多,平均評價就反映了大量觀眾的真實評價。
雖然使用Bayesian estimator好處多多,還是要注意一些小地方。由於初始評價是依照以往平均評價決定,當一段時間後大多數觀眾評價超過平均時,此評價仍會受到原始平均的拉扯產生低估的情況;相反的,若大多數觀眾評價低於平均,加權後的評價也會受到原始平均往上拉扯而高估。換個角度想,往原始平均拉扯就像是某種程度的保守作為,並不會造成像是大量灌票這樣太誇張的評價結果。
除了IMDb之外,知名桌上遊戲論壇Board Game Geek 也是使用Bayesian estimator來進行遊戲評價整合。下次看到IMDb、Board Game Geek、或其他使用Bayesian estimator為排名依據的網站時,不用再為計算或是可信度感到困惑了。
參考網站:http://www.imdb.com
--
作者:王悅 臺大流病所博士生。立志以統計在流病界撐出一片天,熱愛桌遊,喜歡從桌遊中思考戰略... 還有人生大道理!!
![]()