
AlphaGo:從棋盤到電網
台大電機系吳奕萱
解析AlphaGo
圍棋長久以來被視為機器最難駕馭的棋類,因為儘管他的規則單純,卻有相當高的複雜度。圍棋的棋盤大小為
格,使得整個棋局的排列組合數約為
,複雜度遠高於西洋棋的
種組合。因此,超級電腦「深藍(DeepBlue)」在下西洋棋時,可用類似窮舉(brute-force)的搜尋方式,探索代表未來局勢的樹狀結構,推導後續步驟勝負的可能性,但同樣的方法在圍棋上卻行不通。那麼 AlphaGo 是如何做到的?AlphaGo 的演算法,可分為三個部分:策略網路(policy network)、評價網路(value network)、與蒙地卡羅搜尋樹(Monte Carlo tree search, MCTS)。前兩個網路本質上是由卷積神經網路(Convolutional Neural Network, CNN)構成,將棋子可能出現的位置組合縮小至可控制的數量,再利用第三步的蒙地卡羅搜尋樹計算答案。三個步驟,模擬了人類進行決策時的邏輯思考,並能取得在有限運算時間內的最佳解。
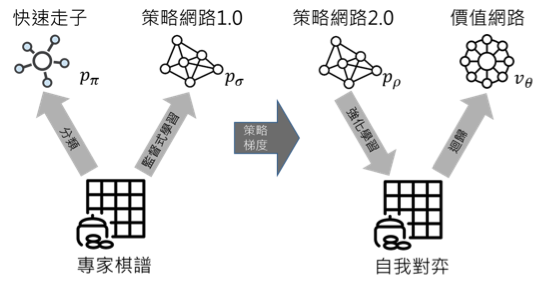
圖一、AlphaGo 神經網路架構 (資料來源:參考資料[1],圖片來源:譯者自繪)
策略網路中,首先藉由監督式學習,輸入大量職業棋手的棋譜,讓 AlphaGo學習高手的棋步。接下來,利用強化學習(reinforcement learning),讓內部兩個策略網路自我對弈進行訓練。訓練後,網路能更精準預測高手落子的位置,進而減少後續需計算的組合。價值網路則是取策略網路得到的結果,評估落子後的局面,判斷最終勝負的機率。為求計算速度,在此取用卷積神經網路涵蓋範圍內的平均勝率,得到一近似解,AlphaGo亦能自行調整往後預測的步數,有效率地減少計算的深度。圖一顯示AlphaGo 以專家棋譜、自我對弈作為訓練素材,計算機率分布,並運用隨機梯度下降(stochastic gradient descent)更新參數的流程。
最後是蒙地卡羅搜尋樹的四個步驟:選取(Selection)、展開(Expansion)、評估(Evaluation)、回傳(Backup)。藉由隨機抽樣擴大搜尋樹,沿著搜尋樹往下展開並評估勝率,再將計算的價值往上回傳更新。
提升自我學習力,拓展應用領域
最新版的 AlphaGo 可用更少的資料,進行更多的自我學習。他的目標也不再只是棋類遊戲,而將智慧運用於供電電網的優化。我們可以發現,圍棋與電力系統優化這兩個問題,在本質上有許多相似之處。以下將 AlphaGo 在電力系統的應用,根據目的、模式的交互性及複雜度,分為兩大類:以遊戲為基礎(game-based)、以搜索為基礎(search-based)。
市場如遊戲:知己知彼,最大化利益
以遊戲為基礎的模式:有兩個以上的個體參與其中(例如:發電廠、電力公司、消費者),彼此間處於競爭狀態,必須考慮對手在多個階段可能採取的行動,以選擇最有利個人的策略。這些理性的玩家會使市場處於平衡狀態,其邏輯思考與 AlphaGo 在棋盤上進行的運算有異曲同工之妙。相關應用包含多階段競標(前一日市場、前一小時市場、即時市場)、分散式市場交易、充電式電動車能源管理,如圖二所示。
值得一提的是,分散式市場交易中,個體間存在行動次序的區別,可用斯塔克伯克競爭模型(Stackelberg leadership model)解析。扮演「領導者」的中央控制者訂定一零售價,擁有分散式能源(DER)的「跟隨者」則在觀察價格後,規劃輸電量及時程以最大化收益。領導者與跟隨者行動時,均面臨不確定因素:領導者未掌握發電機運量與客戶消費習慣,跟隨者則須猜測未來價格的漲跌,使問題存在高複雜度。另外,充電式電動車的特色,則是使用者得以在角色間轉換:充電為電能消費者,放電時轉為電能提供者。他們在有限的輸電能力與電池容量下,尋找最低成本的策略以達成充電需求。
建立情境樹,搜索最佳解
以搜索為基礎的模式:局面中僅有單一個體,無個體間的互動,關鍵元素為整個系統所處的狀態。在電力系統中,因為存在負載及風力變異、發電機中斷等潛在突發狀況,因此探索時需考慮多重情景。首先畫出「情境樹」以代表各種可能的狀態。樹木「根部」的節點為當下系統所處的狀態,將各節點下可能出現的變異數作為分支向下延展,而從「根部」走到末梢「枝葉」的路徑,代表一種情景。為達到即時監控,AlphaGo 演算法在此會篩選較關鍵的狀態進行評估,有效利用運算資源,找出潛在的高風險情景。相關應用如圖二所示。
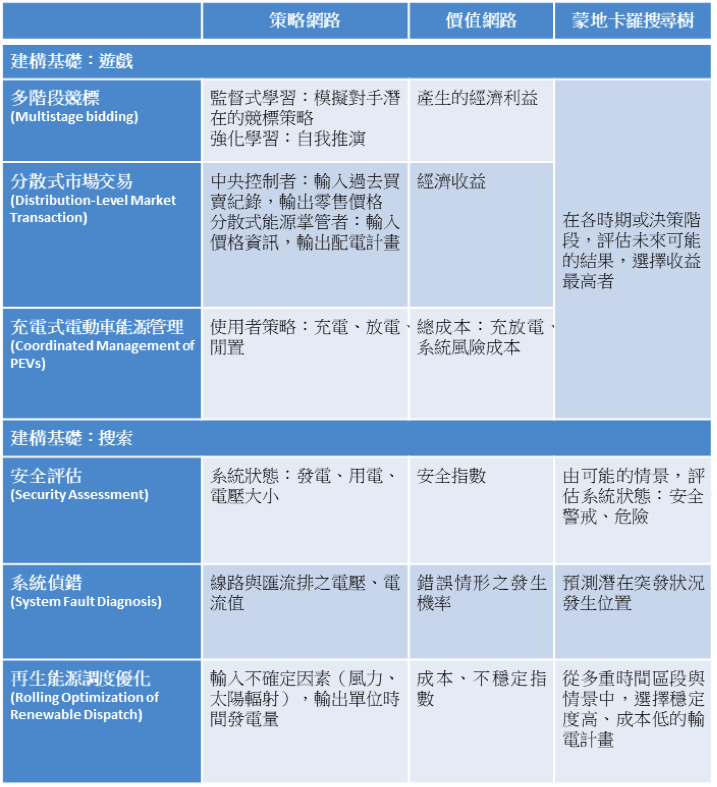
圖二、AlphaGo 演算法於電力系統之應用
AlphaGo的下一步:提升能源效率,創造經濟利益
AlphaGo 開發團隊 DeepMind 正與英國國家電網(National Grid UK)合作,將「棋局」從棋盤帶向現實生活中的電力供應問題。英國國家電網掌管電力輸送的基礎設施,以確保各地有足夠的電力供應。然而近年來,由於再生能源供應的不穩定性,使得電網的供需平衡面臨挑戰。他們的目標便是利用 AlphaGo 演算法,預測電力供應與需求的尖峰,最大化再生能源的利用,進而提升電力系統的效能。如此不用新建基礎建設,只需透過優化手段,便預期可減少 10 % 的電力使用量。
事實上,DeepMind 在減少電能消耗上,已有相當的成效。2016年他曾模擬Google 的資料中心系統,學習有效控制風扇和其他硬體設備,將冷卻機器所需的電能降低 40 %,相當於讓資料中心整體用電量減少15 %,為Google大幅節省電費。走出棋盤,走向新世代能源運用,AlphaGo的影響層面與涉及效益逐漸擴展,正邁向下一個里程碑。
編譯來源:From AlphaGo to Power System AI: What Engineers Can Learn from Solving the Most Complex Board Game Fangxing Li, Yan Du, IEEE power & energy magazine, 2018
參考文獻
- [1] David Silver, Aja Huang, Demis Hassabis et al., “Mastering the Game of Go with Deep Neural Networks and Tree Search”, Nature, 2016
- [2] Richard Evans, Jim Gao, “DeepMind AI Reduces Google Data Centre Cooling Bill by 40 %”, 2016
- [3] Cade Metz, “Google’s AlphaGo Levels Up from Board Games to Power Grids”, 2017