
機器人:什麼?大聲點我聽不見!

編譯/臺大電機系 吳奕萱
雞尾酒會效應
音訊分離(Speech Separation)一直是語音辨識技術亟待克服的一大問題。在過去,研究人員利用監督式機器學習,增加AI對環境噪音的鑑別度,並提升目標語音的音訊品質,進而達到降低背景雜音、分離不同講者語音的目的[2];或者,利用深度學習,訓練AI藉由語音特徵(頻譜上不同時頻區塊間的對比),將音訊分群(clustering)。當看到過去訓練集中不曾出現的音訊時,藉K-means分群法將其中的組成歸類。這樣的方法在僅有二至三人同時說話的情境下,已取得不錯的音訊分離效果[3]。然而這些研究多著重在如何將目標語音抽離出來並優化,至於如何將不同來源的語音對應到說話者身上,仍有改善空間。
另一方面,人腦與生俱來這樣的聽覺選擇能力:在吵雜環境(例如:雞尾酒會)中,若我們將注意力集中在特定聲音來源,例如注視說話者的臉部,便能自動忽略其他不相干的聲音,聽見對方的說話內容,稱作「雞尾酒會效應」(The Cocktail Party Effect)。其中的一大關鍵,在於影像與語音的結合。
音訊結合影像
以此為出發點,Google開發出新的音訊分離技術便是由影片著手,首先在一幀幀影格中進行人臉與口部動作辨識,多了視覺資訊後,再將分離的語音與人物影像作連結。一個需要克服的困難,也是近年來許多視音訊(Audio-visual, AV)分離技術共有的缺陷─他們是「speaker-dependent」,意即:辨識對象必須曾經出現在訓練資料中,系統方可識別。而這往往取決於訓練資料集的規模與內容多樣性。
研究人員於是蒐集了近三十萬部短講影片(例如:TED Talks),包含不同語言、不同年齡層的講者,並擷取其中音訊單純、人像清晰的片段,匯整為「AVSpeech」資料集,用以訓練AI針對不同說話者分離出獨立音軌。在「很多人同時講話」與「環境吵雜」等情況下,視需要強化特定音軌,以達到消除雜音(包含他人對話與背景噪音)的目的。
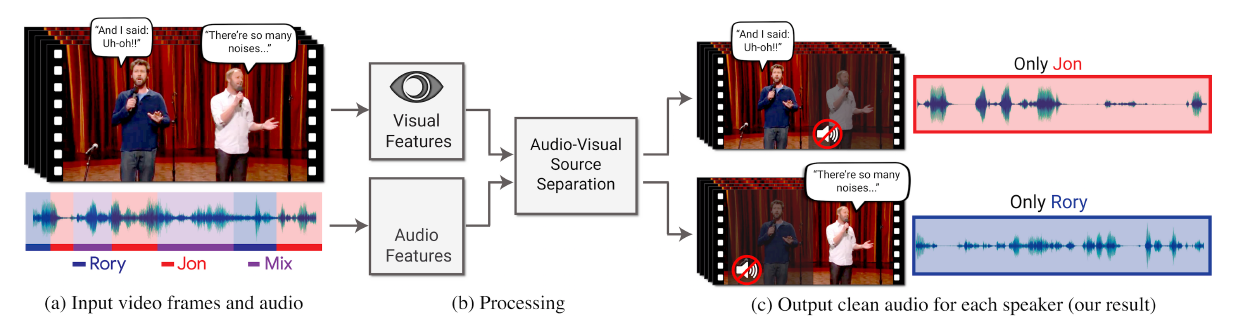
將影片中的影像與音訊分離後再配對(來源:A. Ephrat et al, 2018.)
模型架構
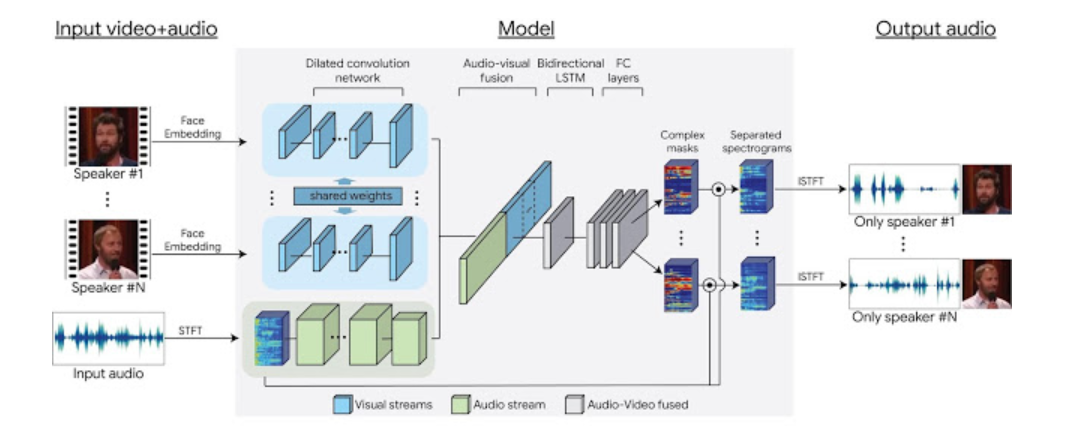
Google新語音辨識AI背後的神經網路架構(來源:I. Mosseri et al, 2018. )
- 輸入:影像+音訊
輸入的資訊包含影片的影格與對應的音軌,影片中可能有超過一個人同時說話,或有其他噪音形成干擾。首先藉由預先訓練好的臉部辨識模型,為每幀影格中的人臉,依據特徵賦予一向量表示。音軌則是進行短時距傅立葉轉換(Short-time Fourier Transform,STFT),以複數形式表示。
- 模型:神經網路架構
將不同人物臉部辨識的結果輸入多層卷積神經網路(Convolutional Neural Networks, CNN),得到視訊特徵。接著融合視訊與音訊特徵,通過雙向長短期記憶(Bidirectional LSTM)類神經網路與全連接層(Fully connected layers),產生可用於音訊分離的輸出。
- 輸出:頻譜遮罩
模型針對影片中的每個人物以及背景雜音,輸出對應的頻譜遮罩。將遮罩與輸入端充滿噪音的頻譜相乘,再進行逆傅立葉轉換後,便可得到該人物乾淨的音訊。從每個人獨立的音軌,我們可以重組一段影片,加強特定角色的話語,並降低其他干擾,使得重要對話更加清晰。
應用
觀看YouTube影片時,畫面下方往往有系統自動生成的字幕可搭配使用,然而在互動較熱烈的節目中,系統容易將不同說話者的話語混雜在一起,產生難以理解,甚至錯誤百出的字幕。而良好的音訊分離,可望幫助系統在多人對話的情境下,清楚分辨每位對話者的語音,提升字幕正確率。除此之外,也可應用於視訊會議,讓與會者能更清晰地聽見發言者的聲音。當然,也是最重要的目的,智能助理得以在吵雜環境中,更輕易地接收使用者所下的指令。
參考資料
- A. Ephrat, I. Mosseri, O. Lang, T. Dekel, K. Wilson, A. Hassidim, W. Freeman and M. Rubinstein, “Looking to listen at the cocktail party“, ACM Transactions on Graphics, vol. 37, no. 4, pp. 1-11, 2018.
- D. Wang and J. Chen, “Supervised Speech Separation Based on Deep Learning: An Overview“, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 26, no. 10, pp. 1702-1726, 2018.
- J. Hershey, Z. Chen, J. Le Roux and S. Watanabe, “Deep clustering: Discriminative embeddings for segmentation and separation“, in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Shanghai, China, 2018, pp. 2379-190X.
- I. Mosseri and O. Lang, “Looking to Listen: Audio-Visual Speech Separation“, Google AI Blog, 2018.