
不會跳舞嗎?AI讓你動起來

編譯/台大生醫電資所 葛竑志
建構骨架模型
首先,為了取得「體態」與「骨架」等資料,研究團隊要求受試者們穿上貼身衣物,依照指令或隨意動作,拍攝長達20分鐘的影片,透過常見的姿勢偵測(pose detection)模組,將人的四肢、軀幹、手指及臉部表情在平面上標上座標,一個看似火柴人的骨架便合成了。
講到這裡,讀者或許已經注意到,所謂的「骨架」其實就是一種自編碼模型(auto-encoder)在潛在空間(latent space)的表示:所輸入的影像透過編碼器投影到一個低維度空間,再由解碼器將這種低維向量重建回原先影像。若自編碼模型訓練得好,那麼只要取得解碼器,我們便可由較少的資訊(骨架),重建出影像(體態)這種高維度的資訊了。
所以,只要透過一個「固定」的姿勢偵測模組,把人的動作或舞步簡化為一幀一幀影格中的火柴人模型,那麼我們便可以「骨架」為轉換依據,將舞蹈示範影片中的人物置換為任何人。

圖一、輸入影像與姿勢偵測結果(來源:C. Chan et al, 2018.)
生成式對抗網路的影像重建技術
原理看似簡單,但仍要分成兩個部份來考量。首先,重建的品質是否足夠?其次,則是「骨架」能否成功對應到正確的「肢體動作」。前者在理論上難度不高,因為只要擁有足夠的骨架-體態配對資料,一般而言,便可輕易藉由卷積神經網路(convolutional neural network ,CNN)重建影像。相較之下,後者則需要用到較為複雜的「生成式對抗網路」(generative adversarial network ,GAN)。
近年在各大AI研討會上,GAN的討論度始終居高不下。其利用兩個模型─生成網路(Generator,G)與辨別網路(Discriminator,D)─互相切磋學習,在影像重建或三維建模上,都獲得不錯的成果。舉例來說,假設今天想要利用G網路產生一個動漫人物圖像[2]。則需準備一張真正的動漫圖片,以及透過G網路生成的圖片,兩者一同送到D網路作判別。因為G網路一開始對動漫圖片一無所知,D網路或可輕易判定G網路所生成的圖片為偽,並退回G網路要求生成更貼近實際動漫影像的圖片。如此多次反覆訓練下,隨D網路的鑑別力越強,G網路生成的能力也會更厲害,最終我們就能利用G網路產生圖片了。
柏克萊團隊將前述的CNN定義為G網路,專責從骨架資訊生成測試者的影像。之後再將「骨架-真實影像」、「骨架-重建影像」兩種配對送到後續的D網路作鑑別。反覆為之,G網路不僅能產生良好的影像品質,且能將骨架對應到正確的動作。最後,只要將示範影片每一幀影格透過同一個姿勢偵測模組產生骨架,之後送到抽取出來的G網路生成受試者樣貌,如此一來,一位舞者就此誕生了。
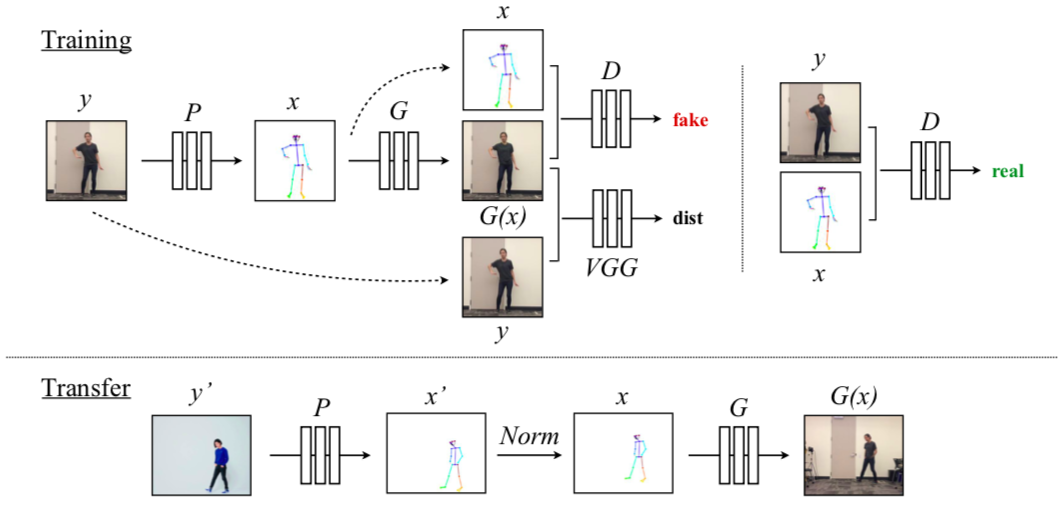
圖二、訓練流程以及生成流程(來源:C. Chan et al, 2018.)
影像優化
然而,如同許多GAN常遇到的困境,以如此低維度的資訊重建影像時,還是遇到了解析度不夠的問題。所幸團隊輔以預訓練的VGG網路進行感知損失(perceptual loss)的定量[3],相對於傳統方法,所定義的損失函數更能縮小重建影像和真實影像間的感知落差。與此同時,他們也用到了這幾年NVIDIA與柏克萊合作開發的「pix2pixHD架構」[4],以多尺度D網路為G網路生成的影像作評斷,大幅提升在細微特徵,以至廣域特徵上的影像解析度。
此外,因示範影片的骨架是逐幀投影的,且姿勢辨識模組有其限制及不穩定性,導致上下幀間的動作常有嚴重的抖動情形,使得重建出的影片看起來十分不自然。所以在設計G網路和D網路時,團隊也動用了一些巧思:要求機器在生成下一張幀影像人物骨架時,必須考量前一幀影格的資訊。如此一來,所使用的資訊就不僅是骨架,更包含了前一幀影像的資訊,當圖片串成影片時,動作更為連貫。
伴隨的道德疑慮
好萊塢電影中長相奇特的外星生物或怪物,通常由演員穿上嵌有定位裝置的服裝,再經過重重CG特效與3D建模後,才變成我們所看到的樣子,這樣的手法往往所費不貲。這項研究卻能透過普通的2D影片就能完成動作的轉移,而且重建的影像十分地流暢且自然。甚至是窗戶上的倒影也可顧及,其效果相當吸引人。
隨著GAN研究的進步,AI所產生圖片或影片的解析度也越來越高,且更貼近現實,但也引起了這種技術可能被濫用的疑慮。如同近兩年來冒出的新興名詞─Deepfake,便是指利用AI影像合成技術偽造名人影片,來製造假新聞或針對個人的輿論攻擊。

圖三、Face2Face論文結果,使用者可以讓特定人物做出任意表情(來源:J. Thies et al, 2016.)
編譯來源
Jon Fingas. “AI-altered video makes it look like you can dance.” Engadget. 2018.
參考資料
- C. Chan, S. Ginosar, T. Zhou & A.A. Efros. “Everybody Dance Now.” arXiv.org, 2018.
- TD. “MangaGAN.” Towards Data Science, December 10, 2017.
- J. Jonhson, A. Alahi & F.F. Li. “Perceptual Losses for Real-Time Style Transfer and Super-Resolution.” arXiv.org, 2018.
- T.C. Wang, M.Y. Liu, J.Y. Zhu, A. Tao, J. Kautz & B. Catanzaro.“High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs.” arXiv.org, 2017.
- J. Thies, M. Zollhöfer, M. Stamminger, C. Theobalt & M. Nießner. “Face2Face: Real-time Face Capture and Reenactment of RGB Videos.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)