
更人性化的電腦視覺系統

編譯/林采萱
生物圖像辨識
關於人類視覺認知系統的理論主要有六種:「模板符合」(Template matching)、「特徵分析」(Feature analysis)、「原型符合」(Prototype matching)、「多重判別標度」(Multiple discrimination scaling)、「元件辨識理論」(Recognition by components theory)與「自下而上和自上而下處理」(Top-down and bottom-up processing)。某些理論其實或多或少受到電腦視覺的啟發,而與一般影像辨識技術的開發原理不謀而合。
例如:「模板符合理論」認為當我們在學習,例如英文字母時,會記住符號的樣式與意義,並將所接收的外界資訊與內部記憶中的樣態比對,搜尋完全一模一樣的圖樣,於是符號A是字母A、符號B是字母B。「特徵分析理論」則認為神經系統透過頻繁接觸以及分析視覺資訊中的特徵,以達到圖像辨識的目的。然而在現實生活中,人類的視覺認知遠不止此。
其一,我們的視覺認知十分靈活,即使只有有限的視角、只能看到物件的一小部分,仍能推斷物體的全貌與種類,甚至能清楚知道所看到的是整體物件的哪一部位,不受觀看(或拍照)角度、時間與光線的限制。這種能力部分歸功於年幼時的「脈絡學習」(contextual learning):曾經在不同的場景下,重複接觸相同的目標物件,以及經常伴隨目標物件出現的其他物件。
再者,現有多數電腦視覺系統皆有其特殊目的,所以儘管海關的人臉辨識、手機的指紋辨識或虹膜辨識技術純熟且準確率高,但受限於編程與訓練資料集,應用範圍十分狹隘。
Viewlet
為了打破這些局限,加州大學洛杉磯分校的Samueli工程學院的團隊打造了新的電腦視覺系統,其採用沉浸式學習法(immersive learning),讓系統能有足夠的發展空間,而不受訓練方式與資料的侷限。新系統的運作可以大致區分為三部分:
- 物件原型-SUVM(Structural Unsupervised Viewlets Model)
仿效人腦的運作方式,將影像中不同顏色、質地的區塊,細分為稱作「viewlet」的個別元件,類似將圖片拆成一片片拼圖的概念。 -

圖一、在不同視角及解析度下偵測的人物臉部。(來源:L. Chen et al., 2019.)
建立空間關係-SRN(Spatial Relationship Network)
利用彈簧網絡模型(spring network model)的變異程度來了解每一個viewlet之間的構成關係、尺度比例變化,以及集體構成大圖時的空間配置。 - 連結取樣點資訊
辨認取樣點周圍的資訊,判斷哪些鄰近物件有助於目標物件的辨識,以及在不同尺度與情境下資訊的改變程度。此部分融合前述模型、GPE(global positional embedding)和其他如集群分析(clustering)、最大概似估計(MLE)等非監督學習方法,主要用以推估不同viewlets間最有可能的相對位置。
研究共使用9,000張不同人物但包含其他物件入鏡的圖像對系統進行測試。這些圖像主要來自網際網路,不僅物件的種類多樣,還有由各個角度、多種環境下的畫面,甚至那些模糊、倒置一般認為「拍壞了」的影像,讓系統在無監督、沒有外界指引的情況下,學習如何辨認人體各部位以及彼此間的相對位置,自行構築出詳盡的人體模型。
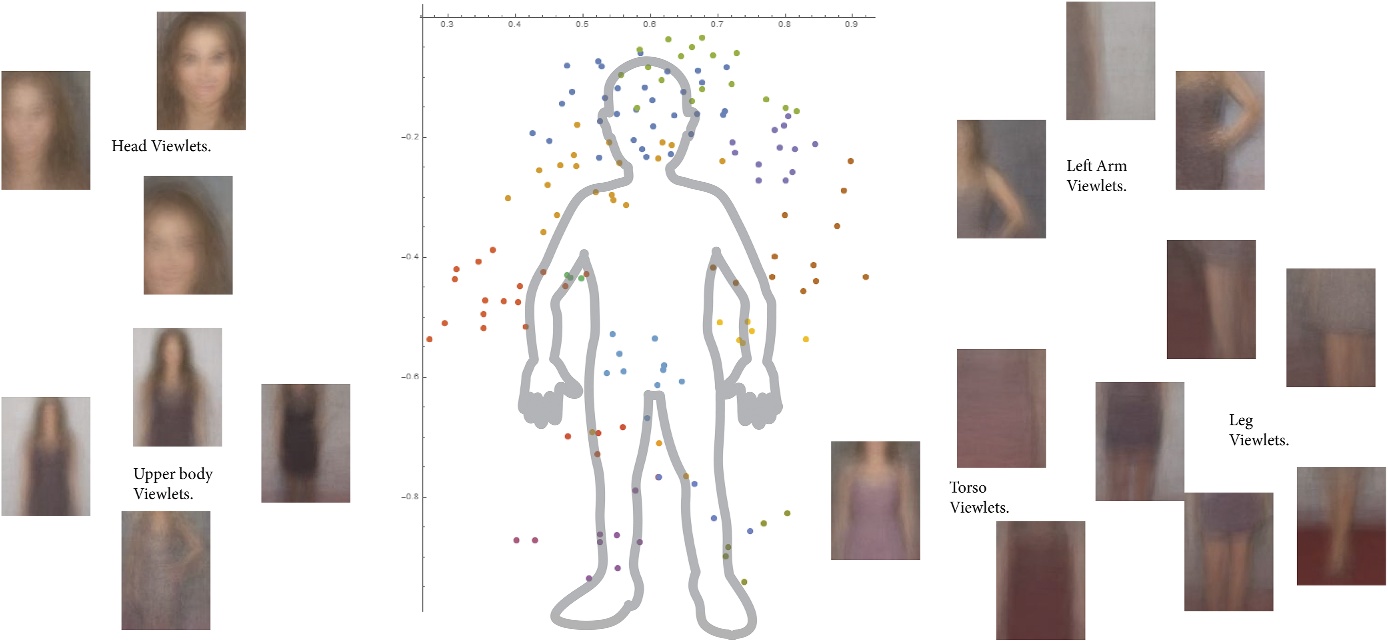
圖二、彩色的點代表系統推估各viewlet在人體的相對位置。這樣的相對位置不會因人的姿態或動作而改變。(來源:L. Chen et al., 2019.)
此外,研究團隊也以摩托車、汽車和飛機的圖像作測試,相較於已開發多年的傳統電腦視覺系統,新系統的表現有過之而無不及:不論是模糊影像,抑或不同角度、不同部位的視角,大都能模擬出該部位在完整物件中的所在位置,並且準確識別圖像類別,料將在電腦視覺領域引領一波新革命。
編譯來源
UCLA Samueli Newsroom, ” New AI computer vision system mimics how humans visualize and identify objects “, UCLA Samueli School of Engineering, 2018.
參考資料
L. Chen, S. Singh, T. Kailath, and V. Roychowdhury, “Brain-inspired automated visual object discovery and detection “, PNAS, 2019.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)