
我們能信任人工智慧嗎?

撰文/Peter Bentley|譯者/常靖
轉載自《BBC知識》2018年3月第79期

(圖片來源:Getty)
臉部辨識、語音辨識、語言翻譯、自動玩電腦遊戲,什麼都難不倒深度學習。這種方法已經徹底革新了人工智慧(AI)領域,成為近十年的新寵兒,並且成效非凡。
然而同時出現越來越多質疑其透明度的聲音。深度學習的原理到底是什麼?我們能放心將涉及人身安全的工作(例如自動駕駛汽車)交給它嗎?一般來說,我們都希望電腦演算法越公開透明越好,但對深度學習而言卻不是如此。
深度學習的本質其實是過去一種電腦學習方法新瓶裝舊酒的結果,這種技術名為人工神經網路(ANN),可追溯至電腦剛問世的時代。ANN是種模擬人腦神經網路的電腦程式,但簡化許多,也不是以類似神經的方式運作,不過它能讓電腦擁有學習能力(見右欄)。
深藏不露
神經網路研究始於1950年代,歷經數十年調整概念,技術漸趨成熟。但當時專家發現,神經網路比不上其他機器學習方法(幫助電腦利用資料學習,藉此分類與預測的AI學科),因此相關研究在1990年代初期漸漸沒落,仰賴精巧統計的學習方法遂成為主流。
大約20年前,事態再度轉變。來自多倫多大學的ANN先驅Geoff Hinton(也是Google旗下Brain Team Toronto的領導人),以及來自瑞士IDSIA達勒莫勒AI研究所Jürgen Schmidhuber開發出更有效的新方法,能訓練神經網路建立更多層架構。神經網路因此能擁有數百個「隱層」,也就是位於輸入神經元和輸出神經元之間,連結各種感測器的一排排神經元。當連接神經元的新方法,碰上大數據、雲端運算和更快的處理器(包括原本用來讓電腦遊戲更生動的顯示卡),便帶來更強的學習能力。到了2006年,這項技術已經能夠建立巨大的「深度」網路、利用大量資料訓練之,並同步運用許多高速電腦運算。
深度學習正是AI最新革命的開端,雖然它還是以極度簡化的大腦模型為基礎,卻能運用軟體中成千上萬個模擬神經元,建立一組規模前所未見的網路。只要有足夠的資料(今日有的是資料)和足夠的電腦(現在也不缺電腦),就能讓網路依照資料來調適並學習,達到接近小型軟體大腦的能力。
如果我們訓練這個網路辨識人臉,將這個迷你認臉大腦複製幾百萬次,並安裝至每台相機,日後拍照時,相機就能辨識人臉,並確保焦距的正確性。如果我們訓練它辨識語音,並將它裝至手機,就能讓手機聽懂你說的話。如果神經網路的神經元夠多,還能在雲端運作,你說的每個字都會被傳送到遠端電腦進行深度思考,其結果會在轉眼間回傳至你的裝置。
過去十年間,深度學習為機器學習領域帶來許多驚人發展,Siri、Cortana和Alexa等等虛擬助理軟體的問世,都要歸功於深度學習;自動機器翻譯、臉部辨識和圖片自動標註也都是它的功勞。然而並非一切都如此完美,雖然這些龐大的神經網路表現非常出色,甚至接近生物大腦的表現,它們卻也和真實大腦一樣,充滿謎團。
應用未知?
對於生物大腦不瞭解的地方還是出奇地多,我們不知道資訊儲存在哪裡,也不知道大腦如何下決定。儘管已知這一切都和神經元有關,卻沒辦法指著一群神經元說,「這區專門記憶巧克力的味道。」或是指著另一區說,「這裡決定是否要買新牙刷。」
同樣地,我們不知道這些龐大的ANN到底用哪個部位儲存資訊或做決定,它對我們來說就像個暗箱,我們無法得知裡頭有什麼。對於科學和工程而言,這不是件好事;當我們手上握有關乎安危的科技,自然希望能證明這項科技永遠不會失敗。例如我們之所以信任自動駕駛火車,是因為數學已證明車上軟體是可靠的。
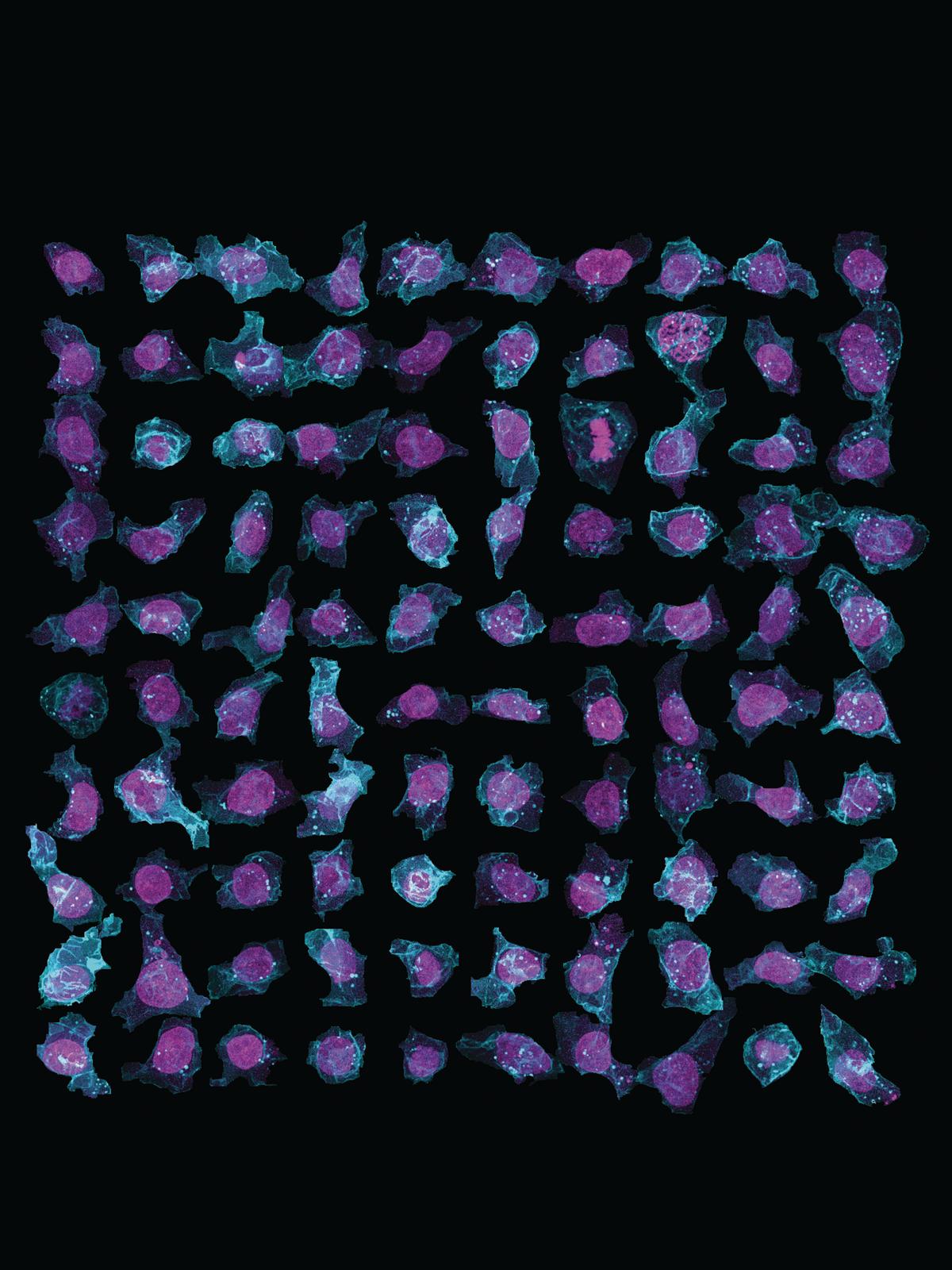
Allen Cell 計畫正在建立一套深度學習網路,用於辨識3D影像中的細胞組成。(圖片來源:Allen Institute for Cell Science)
現在許多汽車製造商都在研究自動駕駛車,這些車大多運用深度學習,作為解釋感測器資料與辨識道路危險系統的一部分。特斯拉是最早推出有自動駕駛模式汽車的廠商,也是最先出問題的自動駕駛車之一。2016年有位特斯拉車主過於信任自動駕駛系統,結果撞上一輛拋錨的廂型車車尾。儘管特斯拉警告駕駛人,使用這套系統時必須時時保持警戒,但Google大腦計劃創辦人、運用無監督深度學習的先驅吳恩達,在推特上對此表示,「給人一套能運作1,000次、讓人有錯誤安全感,然後就撞車的系統,這樣很不負責任。」
美國紐約西奈山伊坎醫學院最近在做另一項研究:使用深度學習分析病歷。他們的深度學習網路在2016年查看超過75,000份病歷,包括78種疾病,並且能夠預測嚴重的糖尿病、思覺失調症和多種癌症,精確度相當高。這項成果當然很有價值,也能拯救無數生命,但要怎麼告訴病人「深度網路認為你可能會罹患思覺失調症」?醫生應該相信這種無法解釋的預測,並著手預防嗎?
法律難題
歐盟非常關心這些新科技,因此已採用新的「通用資料保護規則」(GDPR),規定與機器學習相關的權利,預計今年(2018)5月於所有歐盟成員國生效;例如第22條規定每個人「有權免於接受完全由自動化處理產生的決定」,並且在面對電腦所做的任何決定時,有權得到「關於其使用邏輯的合理資訊」。
這些預防措施頗有道理,卻也與深度學習格格不入。如果你的抵押品被深度學習的演算法退件,在法律上你有權要求解釋,但實際上可能辦不到。專家正在努力解決這個問題。Google DeepMind近期研究顯示,利用認知心理學,或許能找出一些解釋。他們利用神經網路做實驗,嘗試瞭解這些神經元是在回應哪則訊息,就像我們試著瞭解人類大腦一樣。但要是你的抵押品被退件,得到的解釋卻是,「網路有時會花很多注意力消磨休閒時光,這可能是您被退件的原因。」你大概不會滿意。
深度網路欠缺透明度,這點並不見於其他機器學習方法。其他AI技術可以應付大部分的應用方式,同時提供人類能理解的完整解釋。這些方法還有個優勢,就是更穩固的基礎數學形式,我們因此能更清楚瞭解運算結果有多可靠,進而判斷我們能信任這種方法到什麼程度。但這些方法不是深度學習,所以現在的成果沒那麼厲害。
人類駕駛造成許多車禍事故,並非不可能做出比人類駕駛更安全的自動駕駛車,然而若不瞭解深度學習原理及預測它的行為(直到它已經做了),就無法量化將它應用於特定領域的風險,這對於達成安全目標可不是好事。我們的道路、汽車、建築物和城市樣貌一直在改變,若是無法瞭解自動駕駛車的深度學習大腦在做什麼,要如何確定它們在面對未知情境時能正常運作?
歐洲的解決方法是立法規範AI演算法。但我們都知道,AI並不是「一項」科技,而是上千種方法用於上百萬種應用的總稱。深度學習是劃時代的科技成就,但就像所有新科技一樣,必須接受測試與認證,確保它在每種應用方式上都能安全運作,這樣我們才能安心地把自己的性命交給它。
(本文由教育部補助「AI報報─AI科普推廣計畫」取得網路轉載授權)