
資料也有成本

編譯/陳儁翰
資料的成本
一般來說,機器學習使用的資料,會包含許多「特徵」(feature)。例如我們可能會選取骨骼密度、血壓、甲狀腺激素濃度、身高、體重、性別等「特徵」,作為預測一個人健康與否的依據。為避免濫用,使用者必須付出一定的成本取得這些資料,除金錢費用外,尚包括隱私權、病患的抗拒與不適心理等看不見的外部成本。
這也衍生出另一個問題:每一個特徵的取得成本是多少?換句話說,我們如何計算取得「骨骼密度」這項資料需要付出多少成本,才能有效避免資料濫用,卻又不至於扼殺相關研究?這對那些仰賴私密資料,尤其在醫療衛生領域上的機器學習應用,至關重要。加州大學洛杉磯分校的研究團隊就此提出一套可以一體適用的框架,來解決這類問題。以下,我們分三步驟─資料的預處理、指派成本及成本敏感學習演算法(cost-sensitive learning)─簡單介紹。
資料的預處理
研究團隊擷取「美國全國健康與營養體檢調查」(National Health and Nutrition Examination Survey,NHANES)1999年至2016年間,由數千位成人與孩童收集而來的健康資料。有別於以往類似研究多採用合成資料,真實資料除了難以追蹤與估算取得成本外,也往往夾雜許多無關的資訊。我們可以先剔除這些雜訊,降低潛在成本。舉例來說,光是NHANES的資料就含有9,385種特徵,而實際應用於糖尿病預測的僅45種。
指派成本
現在我們要來解決最基本的問題:「每一個特徵的取得成本是多少?」研究人員利用Amazon Mechanical Turk(MTurk)服務來標記特徵的取得成本。MTurk是一個人工智能任務的外包平台,業主可以在這個平台發布任務,交由自由工作者承攬,例如框選出目標物件,或針對物品的美觀程度評分,以獲得相對的報酬。
研究團隊利用這個平台,設計出一系列的問題,並假設這些資訊都是與健康相關的有用資訊,以免影響資料所有人「出售」這些資訊的意願,並要求資料所有人自行為這些資訊的取得訂價,以量化這些特徵的取得成本。
成本敏感學習演算法
當有了特徵的取得成本後,研究團隊便可利用成本敏感學習演算法來解決機器學習常見的分類問題,例如判斷目標是否有得到某特定疾病的潛在風險。成本敏感學習演算法可大致分為兩種:一是基於敏感度,一是基於強化學習。兩者有著相同的核心理念:取得特徵是需要成本的,故若A特徵可以讓演算法在不提高太多成本的前提下,顯著提升預測的準確性,則演算法傾向選取該特徵。兩種方法的差別只在於:前者是估計在特定時間選取某特徵的準確度期望值;後者則是直接任選一特徵,再根據選取後的回饋來調整選擇策略。
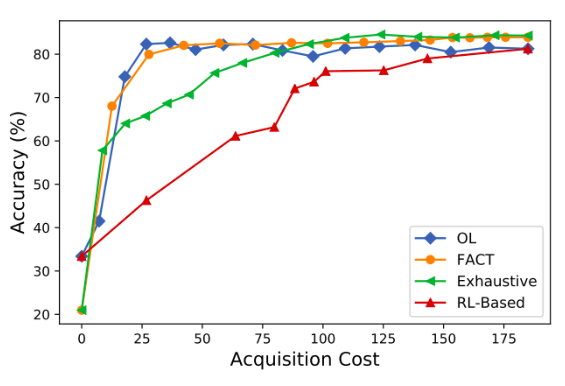
(來源:Kachuee et al., 2019.)
研究人員嘗試了不同成本敏感學習演算法,上圖為預測結果。橫軸為成本,縱軸為糖尿病的預測準確度,表現較好的是是基於敏感度的FACT(橘線)與基於強化學習的OL(藍線)演算法。我們可以看到:當成本(橫軸)高於50個單位後,即使花費更多的成本,兩種演算法的準確度增幅都不明顯。
這大大體現了成本敏感學習演算法的價值:一個專案通常有固定的預算,我們必須在這樣的前提下盡量提高預測準確度,在準確度與資料取得成本間取得平衡。而MTurk則可作為成本標記的輔助工具,配合資料預處理,解決機器學習在實務上所面臨資料成本的問題。
編譯來源
M. Kachuee, K. Karkkainen, O. Goldstein, D. Zamanzadeh, and M. Sarrafzadeh, “Nutrition and health data for cost-sensitive learning“, arXive.org, 2019.
參考資料
- M. Kachuee, S. Darabi, B. Moatamed and M. Sarrafzadeh, “Dynamic Feature Acquisition Using Denoising Autoencoders“, IEEE Transactions on Neural Networks and Learning Systems, pp. 1-11, 2018.
- H. Shim, S. Hwang and E. Yang, “Why Pay More When You Can Pay Less: A Joint Learning Framework for Active Feature Acquisition and Classification“, arXive.org, 2019.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)