
突破自駕車的「盲點」

編譯/林采萱
與現實的落差
現今的自駕車研究,多是讓智慧體在人類設置的模擬環境中接受訓練,提升訓練效率。然而儘管模擬器再「擬真」,仍與現實存在明顯落差,成為智慧體實際決策時的盲點。例如緊隨在後發出警報的救護車,因為虛擬環境中並未納入這樣的情境,自駕車並不知道自己應該減速、暫停,甚至靠邊禮讓,反而將其視為一般大型白色廂型車,同樣的情形亦發生在警車、消防車與校車。此外,飆速車輛、突然衝出的行人、忽左忽右的蛇行機車等標準三寶行為,自駕車系統自然更是無力招架。
此次MIT與微軟合作的研究,由麻省理工學院電腦科學家Ramya Ramakrishnan主導,並首次在AAAI人工智慧會議(Association for the Advancement of Artificial Intelligence conference)上發表。研究團隊希望智慧體在遇到未知情境時,能認知到自己的盲點,並向人類徵詢適當的處理方式。
人類監督

圖一、自駕車必須克服無論源於智慧體(無法辨別救護車與一般廂型車;Sh)或人類(視覺死角;Sa)的盲點。(圖片來源:Ramakrishnan et al, 2019.)
從過去的經驗可知,模擬環境與現實世界的複雜度有著霄壤之別。某些智慧體在模擬中看似安全的決策,在現實中卻可能釀成災禍。兩者間的落差,可以藉由觀察人類反應,比較在相同情境下人類與智慧體決策間的差異而得知。這可以透過類似駕訓班的學習模式,由人類在一旁指導、演示,當自駕車偏離計劃路線,或採取不恰當反應時出手介入、控制,智慧體則記錄下其中的差異,尤其那些被遺漏的細節(例如救護車的警報聲)。經歷多次訓練,智慧體由各個人類監督員處所蒐集的回饋數據,足以建構出各種「情境-適當反應」的對應關係,作為系統修正的依據。但這引發另一個問題:人類所給予的回饋,其實充滿矛盾與歧異。
首先,人類回饋本身便有可能產生分歧。同一決策即使在相同情境下仍可能被部分人類「接受」,但被另一部分人類認為「不可接受」。
再者,特殊情境本身就較為罕見。假設自駕車十次中有九次是遇到一般的白色廂型車,於是從旁呼嘯而過,直到偶然遇到救護車時,一旁監督的人類才會出手制止。對於智慧體而言,相同的情境與行為只有在非常低的機率下才會得到負面回饋,因而理所當然地將其視為「可接受」。
識別「盲點」
研究團隊於是使用一種普遍用於群眾外包(crowdsourcing)的機器學習方法─Dawid-Skene演算法─來處理這些相互矛盾的「噪音」。
實務上,每個情境與行為,智慧體都會同時收到多個標示為「可接受」或「不可接受」的人類回饋,或許彼此相容,或許彼此矛盾。這些回饋經過整合與機率計算,智慧體可得知在多少信心水準(confidence level)之下,原先針對該情境的判斷是「安全/可接受」或「盲點/不可接受」的。
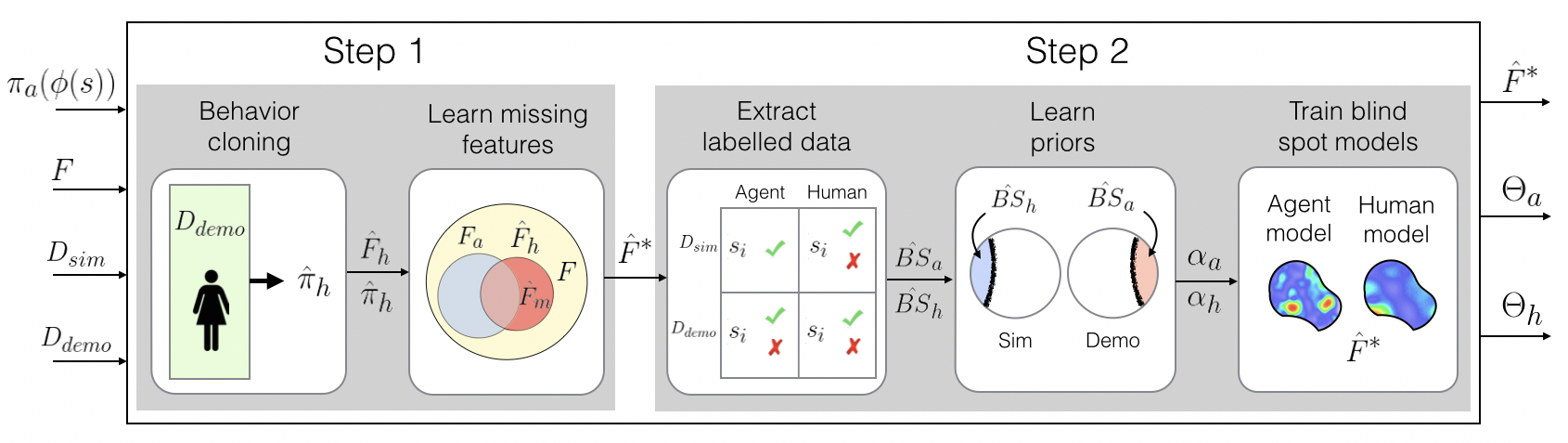
圖二、Ramakrishnan所提出新方法的流程。(圖片來源:Ramakrishnan et al, 2019.)
如此,即使智慧體有九成的把握自己在情境A下做出可接受的行為,這種以機率為出發點的演算法,仍會將其視為有「一成犯錯機率」的盲點,並依此整理出盲點「熱圖」。將初次訓練後遇到的每個情況,由低到高排列出可被視為系統盲點的機率,當某種情境被判定有較高機率會是盲點時,智慧體則會停下腳步,向人類諮詢適當的應對。
未來,研究團隊打算開放盲點模型供大眾使用,並持續精進模型有效性,縮小自駕車訓練與實際上路後的落差。
編譯來源
R. Matheson, “Identifying artificial intelligence “blind spots“, MIT News, 2019.
參考資料
- R. Ramakrishnan, E. Kamar, B. Nushi, D. Dey, J. Shah and E. Horvitz, “Overcoming blind spots in the real world: Leveraging complementary abilities for joint execution“. Thirty-Third AAAI Conference on Artificial Intelligence, 2019.
- M. Temming, “A new AI training program helps robots own their ignorance“, Science News, 2019.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)