
如何辨識文章是由機器或人類所寫?

撰文/陳儁翰
選出下一個字
以下面的句子為例:
「家裡的菜快吃完了,週末我們一起去市_。」
文本生成器如GPT-2在填補底線空格時,會依據上文列出可能的字詞,並按機率排序如下表:
場 61.24%
集 14.75%
區 12.07%
……
換句話說,模型認為在該句中,「市」之後的下一個字是「場」的機率有61.24%、「集」則為14.75%,依此類推。模型傾向選取排序較前的字詞,但為避免固定形式而顯得單調,偶爾也會刻意選取機率較低的字。然而,另一方面,人類的遣詞用字往往比機器自由而不受拘束,難以預測。兩者的區別,成為區分人類與機器文本的關鍵特徵。
不確定性的視覺化
研究團隊以不同的顏色來區分每個文字在模型中的排序:綠色代表該字排序在前10名;黃色前100名;紅色前1000名;紫色則為1000名以外的字。注意:同樣的字在不同位置排名也可能不同。以下提供一些範例,看看各位讀者是否也能注意到其中差別。
首先是一篇GPT-2所產生的假新聞,內容敘述科學家在遙遠且未被探索過的山谷發現一群獨角獸。我們僅需注意顏色的分佈。

可以看到,大部份的文字都標示綠色。也就是說,模型選擇了排序中較前的字詞,使語意通順。
我們再來看看兩篇由人類所寫的文章,一篇是學術論文的摘要,另一篇則是《紐約時報》的文章段落。同樣地,請注意文字的顏色標籤。


我們可以注意到,在短短數行間,紅色標籤多出許多,這告訴我們:其實人類在寫作時,所使用文字多樣、不確定性更高。
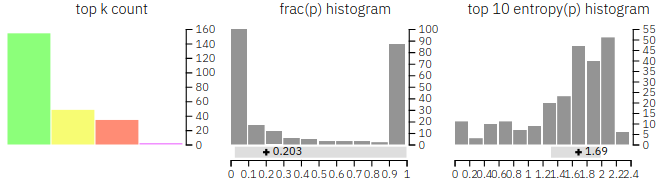
借助另一種資料視覺化圖表,我們可以更清楚地看出其中差異。以人類所撰寫的學術摘要為例,左圖統計該文本中每個顏色標籤的數量;中間則是所選文字的排序先後,越靠近橫軸左側,頻率越低。此處可看出文章創作者(人類)偏向選取那些機率較低的文字;右圖代表所選文字的多樣性,橫軸數字越大且呈負偏態或左偏態,代表多樣性較高。
不過,GLTR主要針對現今文本生成器的弱點,難保未來隨著相關技術的發展,在這場道高一尺,魔高一丈的軍備競賽中,不會敗下陣來。
參考資料
- H. Strobelt and S. Gehrmann, “Catching Unicorns with GLTR,” Gltr.io, 2019.
- A. Radford, J. Wu, R. Child, D. Luan, D. Amodei and I. Sutskever, “Language Models are Unsupervised Multitask Learners,” D4mucfpksywv.cloudfront.net, 2019.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)