
機器如何深度學習(2/2)

撰文/Yoshua Bengio|譯者/鍾樹人
轉載自《科學人》2016年7月第173期
為機器開堂課
目前這一代人工神經網路延續了聯結論的開創性研究。人工神經網路會持續改變每個突觸連結的數值,這些數值代表了連結強度,以及人工神經元彼此傳遞訊號的可能性。深度學習網路使用的演算法在每次接收到新影像時,都會輕微改變這些數值,穩定地接近理想值,讓人工神經網路更精確預測出影像的內容。
為了得到最好的結果,目前的學習演算法需要人類高度介入。這些演算法大多使用「監督式學習」(supervised learning),每個訓練用的範例都附有人類標示的文字,代表學習的內容,例如夕陽的影像配有「夕陽」的標籤。在這種情況下,監督式學習演算法的目標是把影像當做輸入,影像中主要物體的名稱做為輸出。把輸入轉換為輸出的這個數學程序稱為函數,產生這個函數的各項係數(例如突觸連結的數值),相當於學習任務的解。
依賴死記硬背來得到正確答案,是一種簡單的學習方法,但是不太有意義。我們想教會學習演算法什麼是夕陽,然後由它辨識任何影像中的夕陽,甚至包括不在訓練範例中的夕陽影像。學習超越訓練範例的能力(例如分辨各種影像中的夕陽)是任何學習演算法的主要目標,事實上,我們評估人工神經網路的訓練品質,都不使用先前的範例進行測試。要求學習演算法對新例子做出好決定是有難度的,因為符合諸如「夕陽」這種分類的各項係數幾乎可能有無限多組。
在深度學習網路運用的學習演算法接收眾多範例後,期望它們做出好決定,不能只依賴範例,也需要關於資料的假說,以及可能解答特定問題的假設。例如,內建於軟體的典型假說是,如果特定函數的輸入資料很類似,輸出結果就不應該有激烈變化,像是改變影像中貓的幾個像素,輸出結果通常不可能是狗。
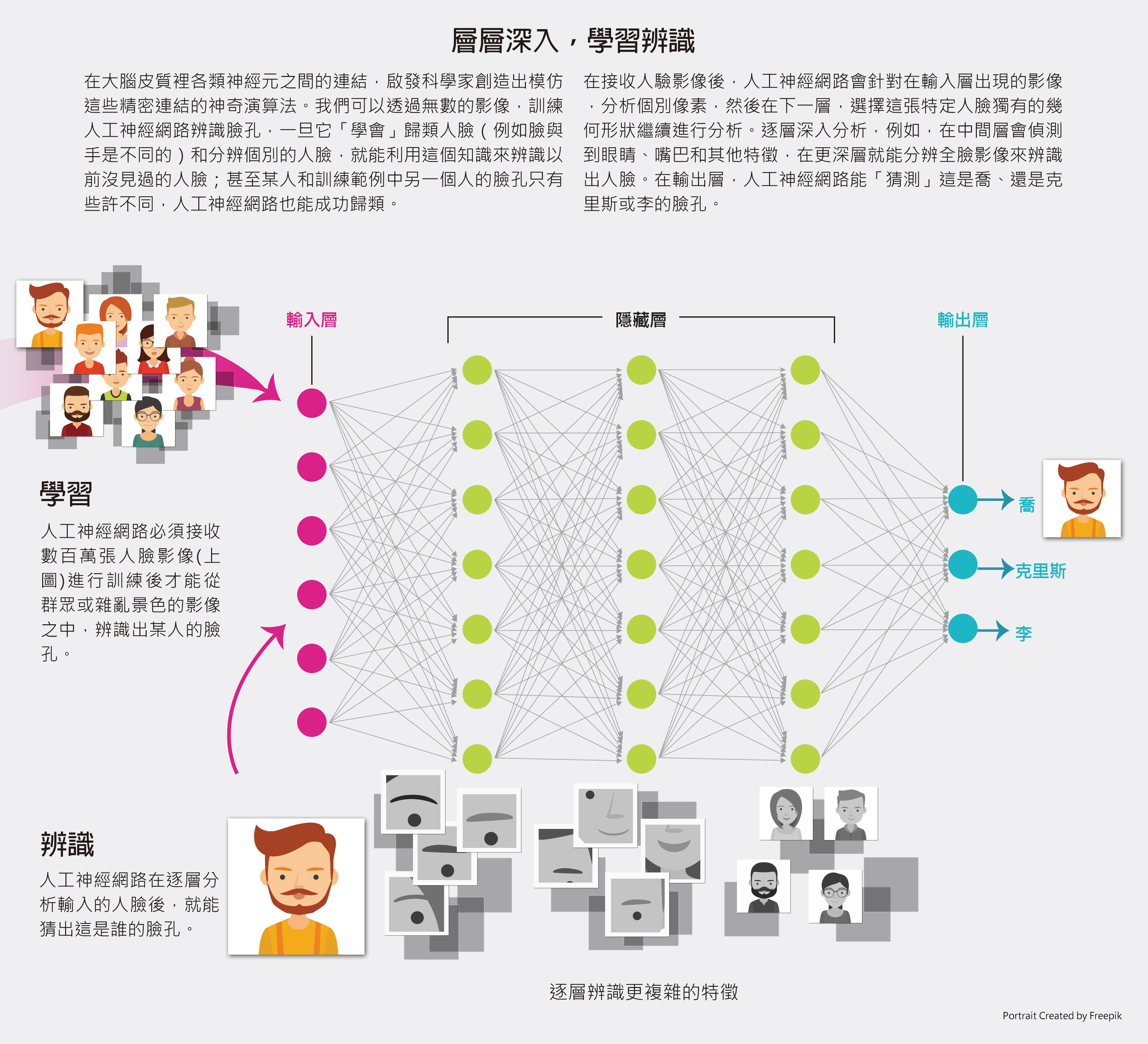
一種整合了影像假說的人工神經網路,稱為卷積神經網路(convolutional neural network),已經成為AI復興的關鍵技術。深度學習的卷積神經網路由很多層人工神經元構成,配置的方式可使輸出結果不會對影像中主要物體的變動太敏感,例如,主要物體稍微移動位置,仍然可以成功辨識;訓練良好的卷積神經網路就能辨識出不同照片中不同角度的同一張臉孔。卷積神經網路的設計靈感來自視覺皮質(visual cortex)的多層結構,視覺皮質是人類大腦中負責接收視覺訊號的部位。卷積神經網路的多層人工神經元,使卷積神經網路變得「有深度」,更能學習真實世界的林林總總。
人工智慧,突破困境
實際上,推動深度學習的功臣是10年前的某些創新研究,當時人們對AI和人工神經網路的熱情降到幾十年來的最低點。由政府和私人資助的加拿大高等研究所(CIFAR),因為批准多倫多大學的辛頓(Geoffrey Hinton)主持的計畫經費,重新點燃了AI的希望之火,這項計畫還有我和美國紐約大學的拉昆(Yann LeCun)、史丹佛大學的吳恩達(Andrew Ng)以及加州大學柏克萊分校的奧斯豪森(Bruno Olshausen)等人參與。科學社群在那段時間裡對於這個領域抱持消極態度,導致我們很難發表論文,更甭提說服研究生從事這方面的研究,但我們強烈感受到,推動這些研究是很重要的。
懷疑人士認為人工神經網路不能克服諸多挑戰,原因之一是訓練人工神經網路的研究毫無進展,這些研究涉及如何讓人工神經網路的表現最佳化(optimzation)。最佳化屬於數學的一門分支,試圖找到一組參數的組態以達成目標。在人工神經網路中,這些參數稱為突觸權重(synaptic weight),代表訊號從一個人工神經元傳遞到另一個人工神經元的強度。
這個目標就是做出最精確的預測。當參數和目標的關係非常簡單時(精確來說,這個目標是這些參數的凸函數),我們就可以逐步調整這些參數,直到逼近可能產生最佳決定的數值,也就是所謂的全局極小值(global minimum),相當於人工神經網路可能發生預測錯誤的最低平均值。
一般來說,人工神經網路的訓練過程沒有這麼簡單,而且研究人員需要處理所謂的非凸函數最佳化(nonconvex optimization)。這種最佳化問題帶來的挑戰更大,不少研究人員相信這種障礙是難以突破的。學習演算法可能會困在所謂的局部極小值(local minimum),因此研究人員無法透過稍微調整參數來減少人工神經網路的預測錯誤。
直到去年,關於人工神經網路困在局部極小值而難以訓練的這種迷思才得以破除。我們在研究過程中發現,當人工神經網路夠大,可以大幅降低局部極小值問題。大部份的局部最小值,其實相當於某種程度的知識學習,而這個程度幾乎符合全局極小值的最佳值。
理論上,雖然我們可以解決最佳化的問題,但打造超過兩或三層大型人工神經網路的嘗試經常失敗。終於在2005年,CIFAR資助的計畫有了突破,克服這些障礙。2006年,我們利用逐層進行的技巧,成功訓練了更深層的人工神經網路。
2011年,我們找到更好的方法,改變每個處理單元執行運算的方式,讓它們更貼近生物神經元,可以訓練更深層的人工神經網路。而且我們也發現,在訓練過程中於人工神經元之間傳遞的訊號混入隨機雜訊(類似大腦內的情況),有助於深層人工神經網路學習如何正確辨認影像或聲音。
有兩個關鍵因素是深度學習技術成功的推手。一個因素是,其他領域的研究人員為了電玩遊戲設計出新的圖形處理器,其運算速度提升了10倍,我們才得以藉此訓練出更大型的人工神經網路。另一個因素是龐大有標資料集(labeled data set)的出現。舉例來說,在某張影像中,貓只是其中一個元素,當學習演算法接收到這張影像時,可以藉由有標資料集辨識出正確答案:貓。
最近深度學習獲致成功的另一個原因,是它學會如何執行一連串運算,逐步建構或分析影像、聲音或其他資料。人工神經網路的深度就是這些步驟的數量。AI在很多視覺或聽覺辨識任務中表現優異,原因就是研究人員建立了非常多層的人工神經網路。事實上,我們在最近的理論研究和實驗中已經證明,必須有深層人工神經網路才能有效執行這些數學運算。
深層人工神經網路裡的每一層都會轉換輸入,產生輸出並送往下一層。更深層的人工神經網路,距離最初的原始輸入較遠,代表更抽象的概念(見下圖)。實驗證明,人工神經網路更深層的人工神經元,傾向對應更抽象的語意概念。例如,某張影像中有辦公桌,即使訓練過的人工神經網路的分類標籤沒有「辦公桌」這個概念,更深一層的人工神經元在處理過程中也能辨識影像中的辦公桌。辦公桌這個概念可能只是其中的步驟,目標是在更深一層創造一個更抽象的概念,而人工神經網路可能會把這一層分類為「辦公室場景」。
 (依原圖重繪)
(依原圖重繪)
超越圖形辨識
直到最近,人工神經網路的傑出之處,大多還是執行辨識靜態影像內容這類任務,但另一種人工神經網路也開始嶄露頭角,精確來說,它能處理依序發生的事件。我們已經證明,遞迴神經網路(recurrent neural network)能正確執行一連串運算,通常針對語音、影片和其他順序資料(sequential data)。順序資料是由實際排列順序的資料構成,無論音素或完整單字。遞迴神經網路處理輸入資料的方式就類似大腦的運作:大腦從周遭環境接受新訊號,改變內部神經狀態,之後才發出一連串指令使身體做出動作而達成特定目標。
遞迴神經網路能夠依照句型預測下個字是什麼,這可以用來產生新的字詞順序。它也能接受更複雜的任務,在「閱讀」一個句子後推測整句的意思,然後另一個遞迴神經網路可以利用第一個語意處理(semantic processing),把句子翻譯成另一種語言。
遞迴神經網路的研究在1990年代後期與2000年代初期陷入停頓。我的理論研究顯示,它難以從遙遠的過去擷取資訊,也就是整個處理過程中最初的元素。想像一下,當你讀到一本書的最後一頁時,試著背出第一頁的第一個句子。許多進展已減輕這些問題,方法是讓這些人工神經網路學習儲存資訊,如此一來就能長時間保留資訊。人工神經網路可以利用電腦的暫時記憶體來處理多個分散的資訊,例如散佈在文件裡的不同句子。
在漫長的AI寒冬後,深層人工神經網路的強勢回歸,不只是科技的勝利,也為科學社群上了寶貴的一課。尤其,我們必須支持挑戰科技現狀的想法,鼓勵多元研究組合、激發創意,才能持續獲致重大突破。(完)
(本文由教育部補助「AI報報─AI科普推廣計畫」取得網路轉載授權)