
機器學習舉一反三(1/2)

撰文/Alison Gopnik|譯者/鍾樹人
轉載自《科學人》2017年9月第187期
重點提要
- 孩童如何從有限資訊學習新的知識?歷代哲學家都在思考此問題,現在資訊科學家和心理學家也想知道答案。
- 人工智慧(AI)專家正在研究孩童的推理能力,想要發展出能教導電腦認識這個世界的方法。
- 兩種不同的機器學習策略都試圖模仿人類的學習方法,這項趨勢已經開始改變AI這門領域。
如果你常常跟孩童在一起,一定會好奇他們怎麼能既快又廣泛學習新事物。歷代哲學家(一路回溯至柏拉圖)也想知道緣由,但一直沒有找到滿意的答案。我的五歲孫子奧吉已經學習不少關於植物、動物和時鐘的知識,更不用提恐龍和太空船。他也能理解其他人的需求、想法,以及有何感覺。他可以依據這些知識,把看到和聽到的事分類,並做出新的猜測。舉例來說,他最近認為美國紐約市自然史博物館展出的新發現物種泰坦巨龍(titanosaur)只吃植物,換句話說,牠其實沒有那麼嚇人。
奧吉從環境中感受到的是一連串撞擊他視網膜的光子,以及振動他耳膜的空氣分子。但在他藍色眼珠後方的神經電腦,能設法從他感官獲取的有限資訊,做出關於草食性泰坦巨龍的猜測。我們不斷在思考一個問題:電腦能否像孩童那般既快又廣泛學習新事物?
15年來,資訊科學家和心理學家努力想找到答案。孩童僅憑著教師或父母灌輸有限的資訊就能獲得大量的知識。儘管智慧機器已突飛猛進,但效能最強大的電腦的學習效率還是無法媲美五歲孩童。
了解孩童大腦實際上如何運作,然後創造出同樣有效率的智慧機器,是資訊科學家在未來幾十年要面對的挑戰。但此刻,他們正在發展的人工智慧(AI),已經納入一些我們對於人類學習方式的認知。
復興人工智慧
1950~60年代AI爆發第一波熱潮後,發展停滯了幾十年。不過近幾年AI展現驚人突破,特別是機器學習,而AI也成為科技界最熱門的領域。關於這些進展所代表的意義,人們衍生了很多烏托邦或末日論的預測。說穿了,這些預言不是提到永生,就是世界毀滅,很多則是同時提到這兩種可能性。
我猜AI的發展會引起如此強烈的情緒,是因為我們由衷恐懼機器變得太像人。從中世紀的泥人傳說到科幻小說《科學怪人》,乃至電影「人造意識」性感的女機器人艾娃,人類有一天或許會創造出跟自己沒有什麼差別的人造物的這種想法,總教人深感不安。
但電腦真的可以像人類那樣學習新事物嗎?這些情緒強烈的預測,有多少指出革命性的改變,又有多少只是誇大之詞?電腦如何學會辨認貓、語音或日文字,其中的細節可能難以理解,但進一步觀察機器學習背後的基本概念,就會發現其實不像一開始那樣令人費解。
解決上述問題的方法之一,是從奧吉或我們任何一人接收到的一連串光子與空氣分子著手,不過傳送給電腦的是數位影像的像素以及錄製的聲音樣本。電腦會從數位資料中找出一連串模式,以偵測或辨認周遭世界裡完整的物體。這種所謂由下而上(bottom-up)的方法源自許多人的想法,例如哲學家休姆(David Hume)、彌爾(John Stuart Mill)和心理學家巴佛洛夫(Ivan Pavlov)、史金納(B. F. Skinner)。
1980年代,科學家想到強而有力且巧妙應用由下而上的策略,讓電腦從資料中尋找有意義的模式。聯結論(connectionism)或人工神經網路系統的研究人員從神經元的運作機制汲取靈感,神經元會把視網膜上的光轉換成周遭世界的影像。人工神經網路採取類似做法,使用相互連結的處理元件(模仿神經元),在逐層分析資料時,把某一層的像素轉換成越來越複雜的影像,例如鼻子或整張臉。
拜深度學習(deep learning)這項新技術之賜,人工神經網路的概念在最近有復興之勢。如今,Google、臉書與其他科技巨擘已經把深度學習運用到商業行為中。一如摩爾定律的預測,電腦的運算能力不斷呈指數增加,也促成了這些新系統,而龐大資料集的發展也有貢獻。在聯結論系統具備更好的處理能力和更多可分析的資料後,學習效率比我們以前認為的還要高。
多年來,對於機器學習應該採取這種由下而上的方式,還是另一種由上而下的方法,AI社群一直搖擺不定。採取由上而下的方法,電腦就能依據既有的資訊來學習新事物。柏拉圖以及所謂的理性主義哲學家例如笛卡兒(Rene Descartes),相信人類是採取由上而下的方法來學習,而這種方法在早期AI的發展中也扮演重要角色。2000年代,這類方法也以機率或貝氏(Bayesian)模型的型式重生。
就像科學家一樣,採取由上而下方法的電腦,一開始會先對世界建構抽象又廣泛的假設。如果假設正確,電腦會預測資料的模式。然後電腦也像科學家一樣,會根據預測結果修正假設。
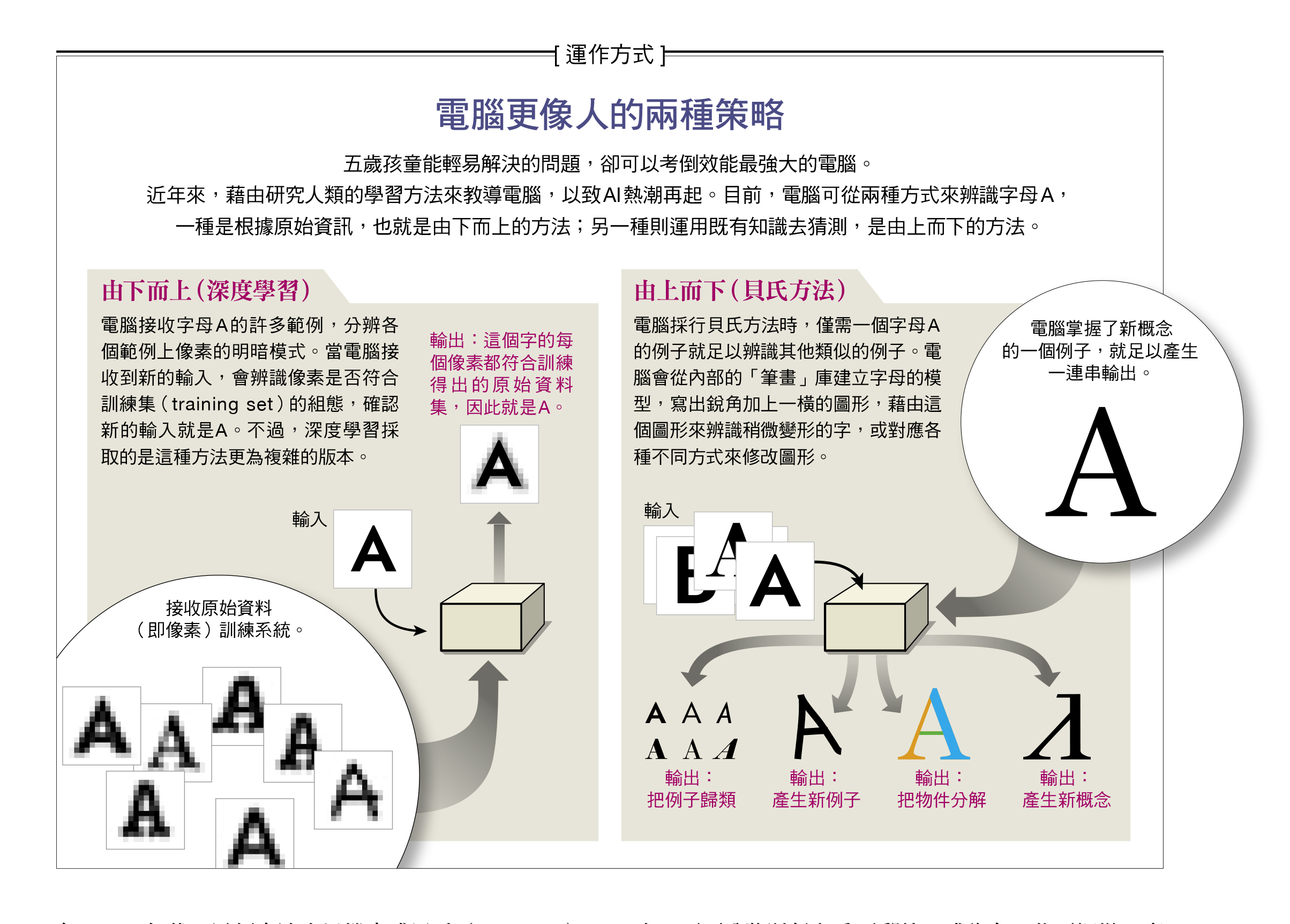
由下而上
由下而上的方法或許是最容易理解的,所以先說明這種方法。假設你想要電腦區分電子郵件信箱裡的郵件和詐騙信,你可能會注意到詐騙信有一些容易辨別的特徵:一長串收件人地址、奈及利亞或保加利亞的發信地址、信裡會提到百萬美元獎金或威而鋼。但非常重要的郵件可能看起來也一模一樣,你一定不想錯過自己獲得晉升或學術獎項的通知。
一旦你比較了夠多的詐騙信和其他類型的郵件,你可能會注意到只有詐騙信顯露某些特徵。例如,奈及利亞配上百萬美元獎金的郵件,就代表是詐騙信。事實上,要區分詐騙信和重要郵件,或許有一些更細微、高階的模式,例如拼錯字和IP位址,但兩者一點也不明顯。如果你找到這些特徵,就能正確過濾出垃圾郵件,而不用擔心錯過「你的威而鋼已寄出」的通知郵件。
採取由下而上方法的機器學習可以找出相關線索,解決這類任務。為了做到這點,人工神經網路必須進行學習過程。把龐大資料庫裡幾百萬筆例子輸入電腦,每筆例子都標示一般郵件或是詐騙信,然後電腦會擷取出一組可分離出垃圾郵件的辨識特徵。
同樣地,人工神經網路也能檢視網路上標示貓、狗或劍龍的影像,在每組影像中擷取共同特徵,得以把貓和其他影像區隔開來。之後人工神經網路就能辨識貓的影像,即使那是從未見過的新影像。
其中一種由下而上的方法,稱為「無監督學習」(unsupervised learning),雖然還在相對初期的發展階段,但可以從毫無標示的資料中找出模式。電腦會尋找影像中可辨識物體的整組特徵,舉例來說,一張臉總是有鼻子和眼睛,而且與背景中的樹和山不同。這些先進的深度學習網路透過逐層分析來辨識物體,而辨識任務在不同層中會轉換輸入。
2015年,發表在《自然》期刊的一篇論文,闡釋由下而上方法的進展。深度心智(DeepMind)是Google創立的一家公司,研究人員結合了兩種由下而上的技術:深度學習與「增強學習」(reinforcement learning),讓電腦精通一款名為雅達利(Atari)2600的電玩遊戲。電腦一開始對遊戲的運作方式一無所知,採取的策略是隨機猜測最佳玩法,同時不斷接收玩法結果的回饋。深度學習幫助電腦辨識螢幕上的特徵,增強學習則因電腦獲得高分而獎勵它。電腦在好幾款遊戲上都達到熟練程度,在某些遊戲中的表現還贏過人類專業玩家。不過,對於人類輕易就能夠精通的一些遊戲,電腦則完全沒輒。
我們讓AI透過龐大資料集學習,例如數以百萬的Instagram影像、電子郵件訊息或語音檔案,在過去幾度讓人氣餒的問題上獲得解決方案,例如影像或語音的辨識。然而,我的孫子奧吉沒有接收那麼多的資料並進行訓練,卻輕易就能認出動物或回應別人的發問。五歲孩童能夠輕易解決的某些問題,對電腦來說依舊十分費解,難度也遠超過下棋。
電腦通常要接收幾百萬個範例,才能辨識滿是絡腮鬍的臉孔影像,而人類只需要一些例子就能辦到。電腦經過密集訓練後,或許能辨識從未見過的貓的影像,但是辨識方法和人類的類化(generalization)很不一樣。因為電腦軟體採用不同的推論方式,有時會發生失誤。有些包含貓的影像卻沒標記貓,電腦也可能誤指某個影像是貓,不過那其實只是雜亂的模糊影像,人類則不會出這種洋相。(待續)
(本文由教育部補助「AI報報─AI科普推廣計畫」取得網路轉載授權)