
從資料之海撈出冠軍杯(1/2)

撰文/林軒田|轉載自《科學人》2012年11月第129期
重點提要
- 資料探勘與機器學習是一體兩面,但資料探勘更強調實際預測時的表現及執行效率。
- 藉由舉辦世界性的比賽,讓學術界以及業界研究團隊競爭開發預測模型,是資料探勘的一種研發策略。
- 台灣大學團隊整合了組合式與平均式系統模型的優點,在2011年資料探勘杯以Yahoo!線上音樂服務系統的資料進行預測分析,奪得冠軍。
做為一名在大學講授「機器學習」課程的老師,我在第一堂課最常被學生問到的問題之一是:「機器學習和資料探勘有什麼不一樣?」
我的老師阿布‧莫斯塔法(Yaser S. Abu-Mostafa)在〈會思考的電腦〉中已經為我們勾劃了現代機器學習的面貌。機器學習可視為一種實現人工智慧的方式,它融入了統計學、機率學、演算法設計及計算理論分析,希望讓電腦能從充足的資料中,自動歸納出可以用於預測的規則;資料探勘則是電腦科學中一個歷史久遠的領域,在電腦科學發展的早期,人們就想運用電腦能運算及儲存大量資料的特性,從這些資料中找出些有用的蛛絲馬跡。舉例來說,超市的行銷部門可能想從銷售的資料中,找出哪些商品之間具有高度的關聯性,來做為商品排放的依據(有興趣的讀者,不妨去搜尋一下「尿布」、「啤酒」及「星期五」的故事)。
機器學習與資料探勘都著眼於讓電腦自動對「資料」加以運用,如果運用的方向是「預測」的話,那麼機器學習與資料探勘的目標是一致的。比較細緻的差別,在於機器學習源自於一個理則學的目標:對智慧(預測能力)的終極追尋;而資料探勘則較接近工程學的目標,且更重視方法在特定應用上的實用性,包括方法的實際預測表現及執行效率等。近代的機器學習與資料探勘其實可說是一體兩面,難以切割。許多源自機器學習的方法,已經被有效用於解決資料探勘上的各式問題;許多資料探勘上的重要工具,也成為機器學習系統密不可分的一部份。
在這兩個領域中,由計算機協會(Association for Computing Machinery, ACM)所屬的資料探勘小組(SIGKDD)主辦的大型比賽「資料探勘杯」(ACM KDD Cup),是現今全世界最重要的機器學習與資料探勘比賽。這項比賽每年舉辦一次,吸引了全世界學界及業界許多重量級的研究團隊參加,例如2008年的冠軍隊伍之一來自IBM研究部門,2009年的冠軍隊伍之一來自澳洲墨爾本大學。
資料探勘杯的目標,是在特定的主題上,設計能更準確「預測」的機器學習與資料探勘系統。每年的主題都不一樣,例如2008年的主題是希望能自動由病人的X光片判定是否得到乳癌;2009年的主題是希望能自動由行動電話的銷售資料中,預測顧客未來的行為(升級月租費、轉換公司等);2010年的主題是希望能由學生在一個數學線上學習軟體的學習歷程中,自動判定學生的學習成效。
挑戰資料探勘杯
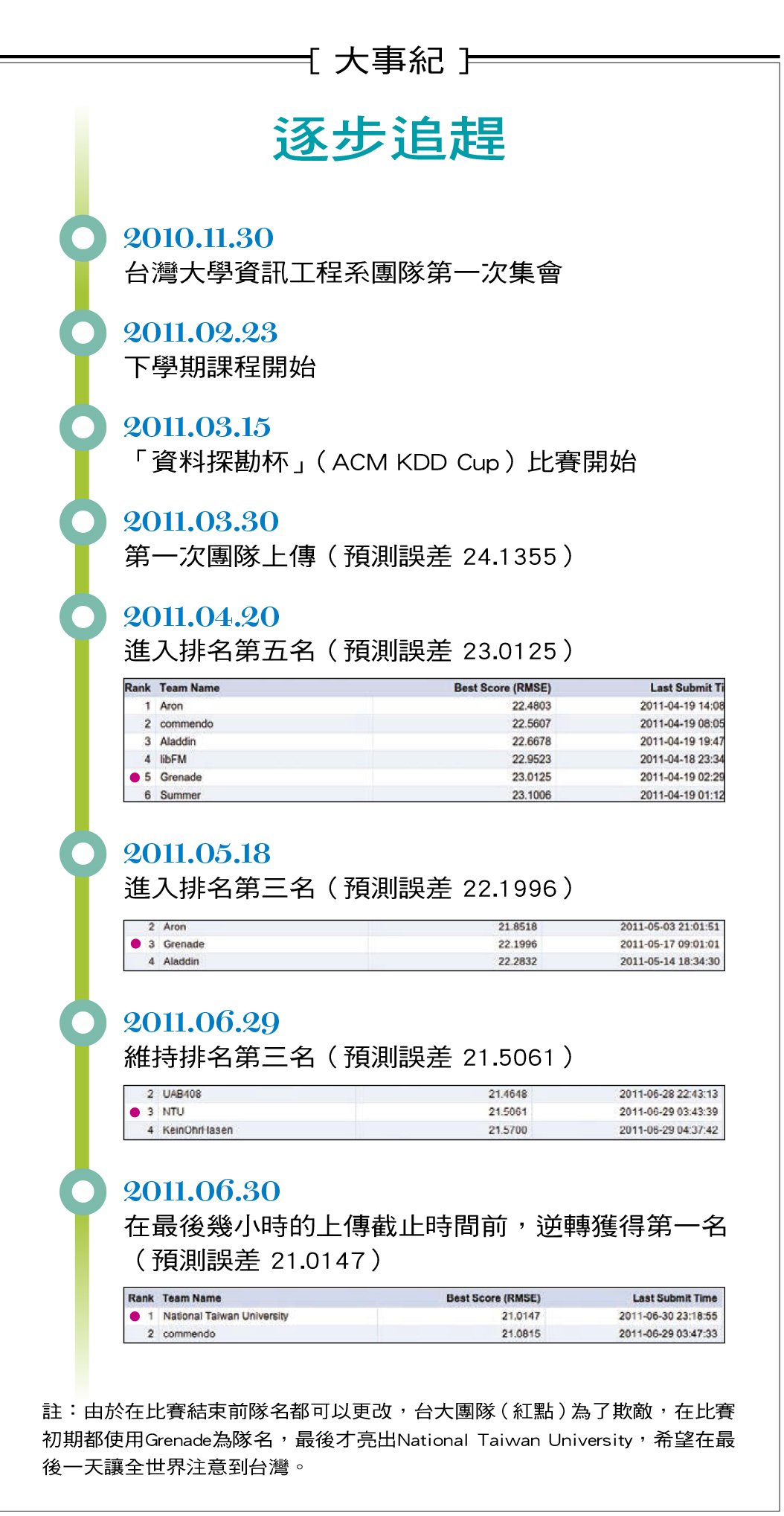 台灣大學從2008年起,每年都組隊參加這項大賽,隊伍成員以資訊工程系大學部及研究所的師生為主,這四年來屢獲佳績。2008年和IBM研究部門並列世界冠軍、2009年得到長期組(slow track)世界第三名、2010年得到世界冠軍、2011年得到兩組子比賽的雙料世界冠軍,成果十分豐碩。
台灣大學從2008年起,每年都組隊參加這項大賽,隊伍成員以資訊工程系大學部及研究所的師生為主,這四年來屢獲佳績。2008年和IBM研究部門並列世界冠軍、2009年得到長期組(slow track)世界第三名、2010年得到世界冠軍、2011年得到兩組子比賽的雙料世界冠軍,成果十分豐碩。
在資料探勘杯中,主辦單位通常會提供一個巨大的資料集,稱之為訓練資料。參賽者必須運用機器學習與資料探勘的演算法,透過對訓練資料的分析,來建立適當的預測模型。主辦單位另外會提供一組測試資料,參賽的隊伍要把預測模型應用在測試資料後,將所得的預測結果上傳給主辦單位。主辦單位會把他們手上的正確答案和預測結果相比對,來評定預測的精準程度。以人類的學習來比喻的話,訓練資料就像上課的教材一樣,提供機器學習與分析;而測試資料就像考試的考題一樣,要用來評定學習的成效。
舉例來說,2011年第一項子比賽的主題,是希望能自動預測使用者對音樂的喜好,這在商業的音樂推薦系統中是個重要的課題。這個比賽的資料來自Yahoo!的線上音樂服務系統,總共橫跨11年的時間。每筆資料類似於「張三,兩隻老虎,85,2007年7月8日9:10」,意思是張三這位使用者,在2007年7月8日9點10分,給「兩隻老虎」這首歌評定為85分的喜好度;其中0分代表非常不喜歡,100分代表非常喜歡。這11年中,Yahoo!從許多不同使用者收集了大約2億6000萬筆這樣的資料,並且把每名使用者最後所評定的四筆資料,列為測試資料,其他(更早期所評定)的資料則做為訓練資料。
在測試資料裡,主辦單位把「喜好度」這個欄位隱藏起來當做他們手頭的答案,參賽系統的目標,就是預測這個隱藏欄位。也就是說,參賽者的預測模型,要能由使用者早期所評定的資料(可想成已經聽過的歌)預測他們之後對歌曲的喜好度。預測的精準與否,會以所預測的值和隱藏起來的答案的均方根誤差(root mean square error)來計算,越小代表越準確。
這樣的問題通常稱之為「協同篩選」(collaborative filtering),意思是希望協同自己與其他使用者的資料,來做出準確的喜好預測。要怎麼協同地預測使用者對歌曲的喜好呢?我們來聊聊一個簡單的方法。如果系統在訓練資料裡面發現,張三和李四都非常喜歡「兩隻老虎」這首歌,這可能表示他們有相似的喜好,而張三還聽過「快樂天堂」這首歌,也給了很高的分數,則系統或許可以推論,李四也會給「快樂天堂」這首歌很高的分數。所以從李四所評過的歌裡,我們可以找出「跟李四有相似喜好」的幾位使用者(例如張三),算一算「快樂天堂」這首歌平均在這些使用者中得到了幾分,就可以依此預測李四所給的分數。
這聽起來是個簡單的方法,也有個很有趣的名稱,叫「芳鄰法」(nearest neighbor,亦稱「最鄰近法」)。姑且不論這個方法的精確度如何,先讓我們來算算這樣做可能要花多少時間。我們要先幫李四在所有使用者中找出和他有相似喜好的人,2011年資料探勘杯的資料中有大約100萬名使用者,如果算一次相似度要花0.01秒的話,算完所有使用者和李四的相似度就要花上將近三小時,而算完所有使用者兩兩間的相似度要多久呢?158年!這說明了資料探勘杯的困難性,不但要精確,更要「有效率」(注意!這是資料探勘領域著重的特點之一),才能在短短數個月的比賽中奪得佳績。(待續)
(本文由教育部補助「AI報報─AI科普推廣計畫」取得網路轉載授權)