
強化學習模型的診斷工具──bsuite

編譯/陳儁翰
7種核心能力
bsuite將一個強化學習模型應具備的能力分為:基礎、歸因、探索、通則化、記憶、雜訊、規模等7種,以下我們依序解釋這幾種能力的內涵:
- 基礎能力(Basic)
測試模型是否能解決一系列簡單的決策問題和標準分析,藉此確認模型已可掌握其中的獎勵機制,這是所有強化學習模型應具備的基本能力。
- 歸因能力(Credit Assignment)
模型是否有能力推斷出到底是過程中的哪一個行為或決策導致了最後的結果,找出其中的關鍵因素。
- 探索能力(Exploration)
強化學習模型常會面臨這樣的兩難:嘗試與平常不一樣的行為,向外探索(exploration),尋求更好的解法;或利用(exploitation)已知知識,固守既有的行為模式,保守行事。模型是否可在兩者間取得平衡,甚至確保自己的每一次探索更加有效率。
- 通則化能力(Generalization)
模型是否能將所學延伸,應用在其他類似但又有些微差異的問題上。
- 記憶能力(Memory)
考驗模型能否藉由一系列觀察,有策略地規劃未來決策與行動,而非僅考慮當下狀態。
- 雜訊處理能力(Stochasticity/Noise)
這個世界是具有隨機性的。同樣情境下採取相同的行為,依然有可能得到不同的結果。模型能否處理處理這樣的問題,去除資料中的雜訊、選擇更好的策略,也是應具備的能力。
- 各種規模的處理能力(Scale)
這裡的規模指的是獎勵(reward)的大小。針對不同大小的獎勵,模型應有適當的計算方法。
簡便的診斷工具
一個具有代表性的實驗環境須同時符合「目標明確」(targeted)、「簡潔」(simple)、「有挑戰性」(challenging)、「可擴展」(scalable)、「快速」(fast)等五項條件。每個實驗環境僅檢測7個核心能力中的一部分,綜合多個具有代表性的實驗環境,便可評估模型的整體表現,並以雷達圖的方式呈現。
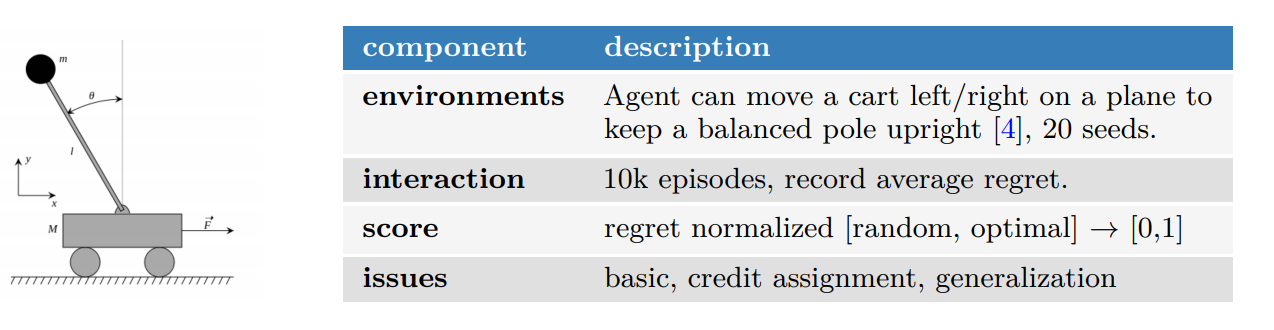
「CartPole」是bsuite中的一個實驗場景,藉由移動車子以平衡車上桿柱。該場景主要檢測模型的基礎能力、歸因能力與通則化能力(圖片來源:Osband et al., 2019.)
以下圖為例,其中針對7種能力的評分,是運行多個具代表性的實驗累積而成,經視覺化後我們可以很容易地看出不同類型的深度強化學習模型在各項能力上的優勢與弱點。對於演算法開發與研究團隊而言,能以更少的資源與時間,更精確地判斷模型的瓶頸與缺陷,bsuite無疑是一大福音。
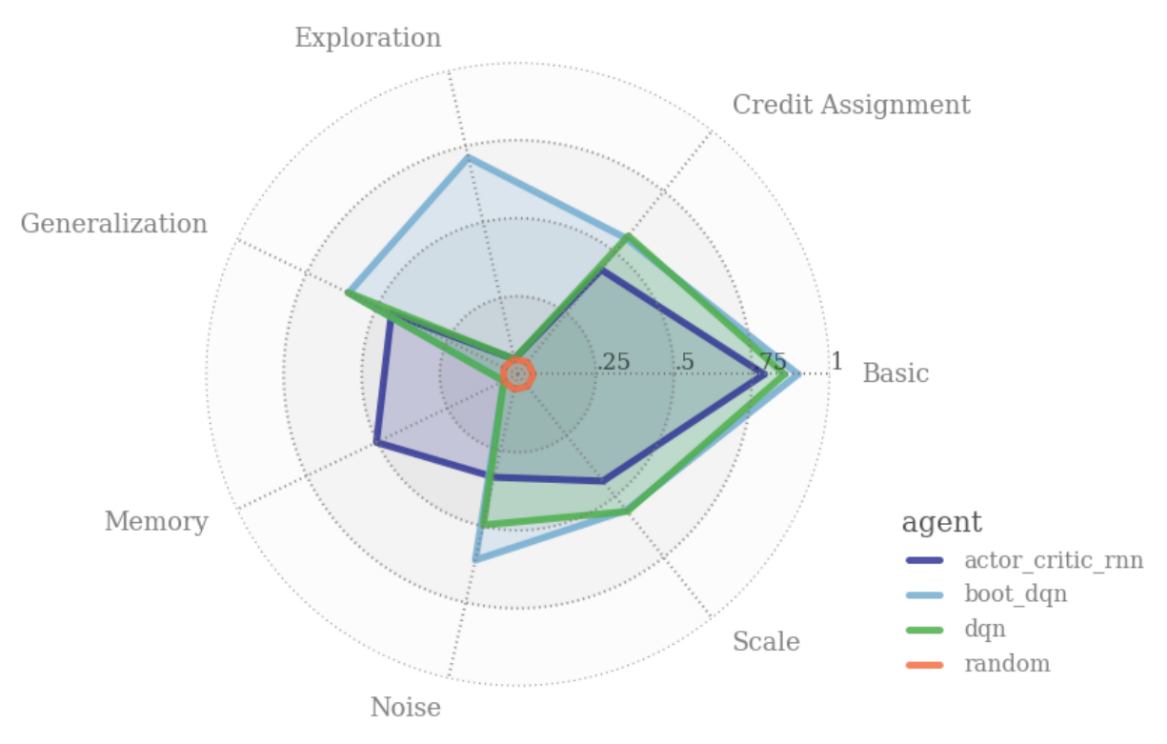
透過雷達圖,各類模型的整體表現一目了然。開發或研究員也可利用besuite針對特定能力的分析改善模型劣勢。圖中紅色代表了隨機行為,各項分數都很低;綠色為DQN(Deep Q Network);淺藍色線代表自助式DQN,其具有良好的探索能力;深藍色為Actor Critic,在「記憶」這項能力上展現優勢。(圖片來源:Osband et al., 2019.)
想要試試看bsuite還能做些什麼嗎?你可以在Github上下載,並找到相關教學。教學是以Colab寫成,可以直接在瀏覽器體驗bsuite的厲害之處,快來檢測看看自己的模型在強化學習各個核心能力的得分吧!
編譯來源
Osband et al., “Behaviour Suite for Reinforcement Learning“, arXiv.org, 2019.
參考資料
I. Osband, C. Blundell, A. Pritzel and B. Roy, “Deep Exploration via Bootstrapped DQN“, Papers.nips.cc, 2016.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)