
人工智慧能創造偉大的藝術嗎?(1/2)

撰文/Dinsa Sachan│譯者/甘錫安
轉載自《BBC知識》2018年4月第80期

電腦程式藉由簡單人形創作出《我的人造謬斯》。去年Sónar+D科技藝術展中,藝術家Barqué-Duran把這個作品描繪在牆上。(圖片來源:Albert (圖片來源:Albert Barqué-Duran/Sonar+D)
去年在巴塞隆納舉行的Sónar+D藝術科展令人眼花撩亂。展覽中,許多藝術愛好者為了一睹西班牙藝術家Albert Barqué-Duran,在牆壁上作畫的創意展現過程而大排長龍。類似狀況在藝術展中似乎顯得稀鬆平常,但那可不是尋常的作品。
在展示牆旁邊的電腦螢幕上,是位臉孔略微模糊的妖嬌裸女。這其實是由人工智慧程式繪製的畫作,Barqué-Duran只是把程式的「想像」畫在牆上。

英國藝術家Cohen打造由AI程式艾隆控制的繪畫機。(圖片來源:Hank Morgan/scinetphotos.com)
沒錯,人工智慧(AI)已正式踏入藝術領域。然而大眾想知道的是:AI真的能創作藝術嗎?它是否會成為下一個梵谷或林布蘭?彷彿橫空出世的AI藝術,其實早已誕生多年。美國卡內基美侖大學副教授Ali Momeni說,「藉助機器學習和AI創作的作品屬於新媒體藝術,已經發展了數十年。」史上首位AI藝術家是英國藝術家Harold Cohen創造的「艾隆」(AARON),從它1970年代誕生到2016年Cohen去世為止,艾隆繪出了多種風格的畫作。
近幾年來,類似計畫更是百花齊放。Momeni認為,免費軟體資源和遊戲產業的硬體進展(如Google的TensorFlow等),是推動AI藝術的關鍵角色。TensorFlow是免費軟體程式集,開發者可藉此撰寫AI程式。顯示卡上的繪圖處理器,對許多電腦遊戲而言十分重要,它的處理速度極快,也是創作數位藝術作品的利器。
除了這些關鍵要素,還有資料集的問世。Momeni解釋,「必須先有依據『如何分類或產生新事物』的分析數據,例如辨識影像的數據庫ImageNet等,軟體工具才能運作。但十年前還沒有這類數據。」
AI藝術家嶄露頭角
 教導程式在Sónar+D科技藝術展中創作裸體畫的是德國藝術家Mario Klingemann。Klingemann這項作品的核心是「生成式對抗網路(GAN)」,這是種類神經網路,也就是模擬大腦運作的AI演算法。Klingemann運用數種類神經網路,創造複雜精細的畫作。首先,他必須準備一套訓練資料,包含數千個範例影像,內容是擺出各種姿勢的人類。接下來,他運用類神經網路,將這些影像簡化成簡單人形,並用這組資料訓練另一種類神經網路(也就是GAN)。GAN會檢視這組人形以及原始照片,在處理數千張這類圖片之後,它就能學會如何把簡單人形轉換成各種姿勢的人類影像。由於掌握人類外型對GAN而言相當困難,所以它也犯過不少錯誤。不過克林格曼表示,「對我而言,這就是跟類神經網路一起工作最有趣的部分,它會帶來許多未知的驚喜。」
教導程式在Sónar+D科技藝術展中創作裸體畫的是德國藝術家Mario Klingemann。Klingemann這項作品的核心是「生成式對抗網路(GAN)」,這是種類神經網路,也就是模擬大腦運作的AI演算法。Klingemann運用數種類神經網路,創造複雜精細的畫作。首先,他必須準備一套訓練資料,包含數千個範例影像,內容是擺出各種姿勢的人類。接下來,他運用類神經網路,將這些影像簡化成簡單人形,並用這組資料訓練另一種類神經網路(也就是GAN)。GAN會檢視這組人形以及原始照片,在處理數千張這類圖片之後,它就能學會如何把簡單人形轉換成各種姿勢的人類影像。由於掌握人類外型對GAN而言相當困難,所以它也犯過不少錯誤。不過克林格曼表示,「對我而言,這就是跟類神經網路一起工作最有趣的部分,它會帶來許多未知的驚喜。」
對Klingemann等藝術家而言,藉由藝術進行AI實驗,可瞭解機器的創造力。Klingemann說,「目前大多是讓類神經網路學習如何把影像轉換成另一種影像的視覺範例,但相同原理也能運用於聲音、文字或其他類型的資料。」
他認為,只要降低AI創造藝術的成本,企業就會採用。舉例來說,零售商可運用AI創作商店或餐廳的壁畫,產生原創設計,再大量印製這些作品。
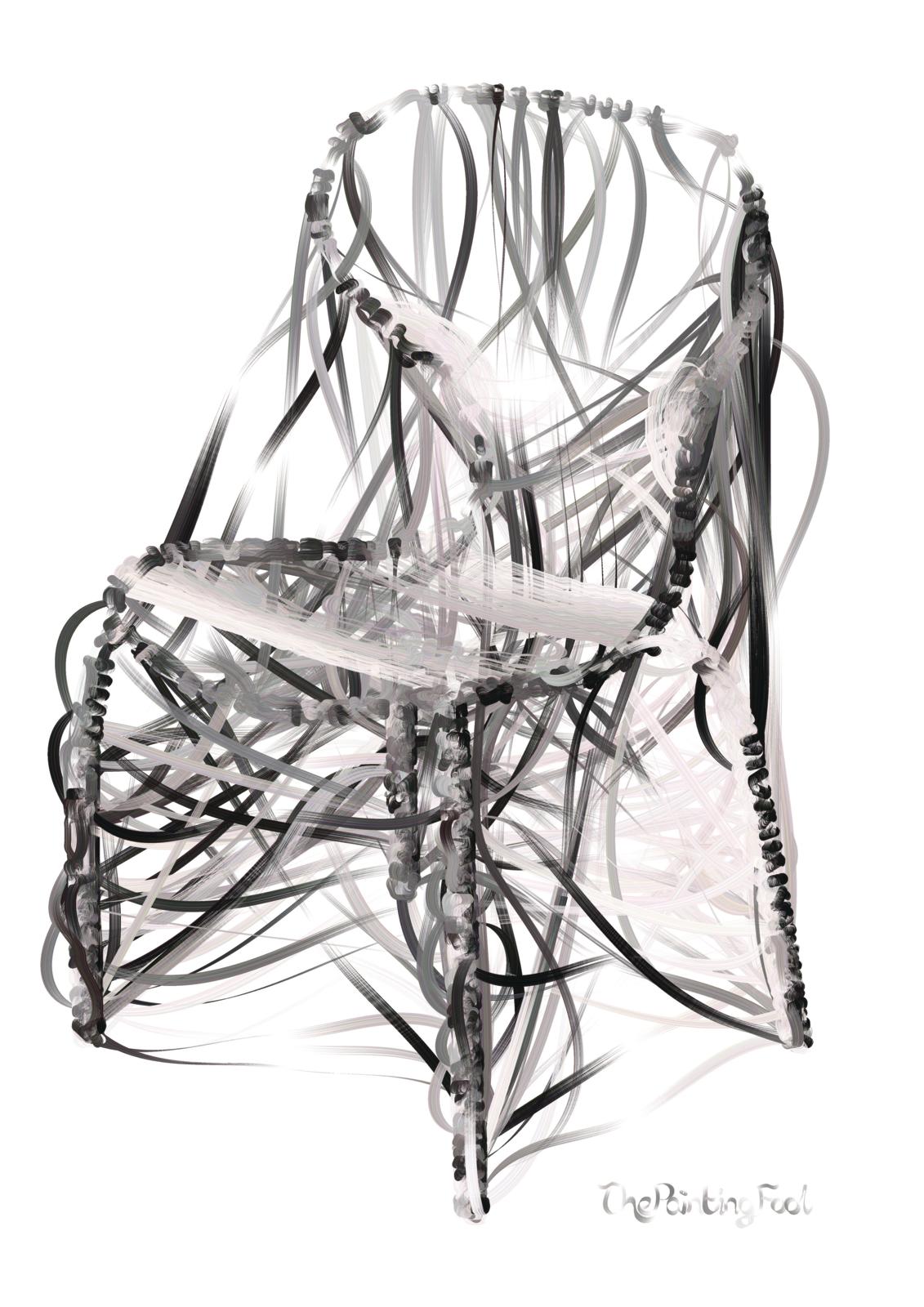
AI程式傻瓜畫家的早期作品《坐立不安》(Uneasy)。(圖片來源:The Painting Fool)
另一位 AI藝術家是英國倫敦金匠學院電腦科學家Simon Colton創造的「傻瓜畫家」(The Painting Fool),Colton常說傻瓜畫家有旺盛的企圖心。傻瓜畫家學習創作的來源包括機器學習和自然語言處理等AI技術。機器學習技術使用能自我學習的演算法(也就是解決問題的基本規則);在藝術世界中,這代表我們不需要每次創作時都重新設定機器。另一方面,自然語言處理技術則可讓電腦理解人類的語言,並加以應用;一般電腦通常無法做到。
如今許多博物館和畫廊都展示傻瓜畫家的作品。2013年巴黎某次展覽中,傻瓜畫家為觀眾繪製畫像,讓眾人深深著迷。為了讓程式產生情緒,研究人員也讓程式看報紙。Colton表示,「如果它讀到10篇令人快樂的文章,例如足球隊贏得冠軍或是孕婦生下三胞胎等等,心情就會很好。」
程式會依據心情選擇形容詞,例如快樂;如果程式感到快樂,就會要畫中人微笑;如果它不開心,就會要畫中人走開。這個程式甚至能思考自己的作品,以成品解釋自己的心情。
傻瓜畫家的才華部分借自美國楊百翰大學Dan Ventura教授的心血結晶:數位藝術家溝通處理元件(DARCI),它和人類一樣能欣賞繪畫。范杜拉表示,「它會觀看圖片,嘗試理解其形狀和形式,並加以解釋。」 Ventura的研究團隊讓程式觀看數千張已由人類加註形容詞的影像,因此DARCI可在觀看時確定圖片屬於快樂、悲傷或可怕。(待續)
(本文由教育部補助「AI報報─AI科普推廣計畫」取得網路轉載授權)