
GAN以外的選擇:對抗強健模型在電腦視覺的應用

編譯/許守傑
對抗安全與對抗強健
過去我們發現影像辨識模型只要樣本有小小的變動,就可以讓辨識結果有大幅度的改變。例如,若我們只是單純取一張貓咪的照片,模型能夠正確辨識;但只要稍微改變貓咪影像中的少數像素,就可以讓模型辨識錯誤,即使影像前後的改變極微,就人眼而言可能完全分不出差異。機器學習模型在面對這樣的對抗樣本(Adversarial example)時效能就變得不穩定,同時也可能被惡意利用而成為安全漏洞,因此目前許多研究都以對抗安全(Adversarial security)為目標而努力。然而,我們能夠期待的,就僅只如此而已嗎?
Dimitris Tsipras等人在2019年的論文中發現一個現象:即當我們操作一張圖像,直到一個對抗強健分類器將該影像分類到錯誤的類別時,就可以得到該錯誤類別的顯著特徵(例如我們改變「貓」圖像中的某些像素,直到一個已經學會如何抵抗對抗樣本干擾的圖像辨識模型仍然會將該張影像誤認為「狗」時,我們便可得到「狗」這個類別的顯著特徵)。換句話說,這就像是我們先讓模型記住容易混淆的類群所擁有的特徵,以避免未來被雜訊所影響而導致誤判;而依循此法訓練出的模型,所學習到的特徵也更符合人類的視覺認知。
然而事實上,從另一個方向思考,我們可以在影像空間中使用梯度下降法(Gradient descent)讓對抗強健模型各分群的對數機率(Log-probabilities)最大化(也就是模型把某張影像分到某群的機率),前述的現象同樣也會發生。
某張圖像經對抗強健模型分到某群的機率最大化後,便可得到該類別的顯著特徵,且更貼近人類視覺認知。(圖片來源:L. Engstrom et al., 2019.)
電腦視覺應用
然而除了更強健的模型外,這方法還能被應用在電腦視覺領域,例如:影像生成、影像轉譯、影像修復、提高影像解析度、由草稿自動生成更細緻的圖像等諸多用途上。

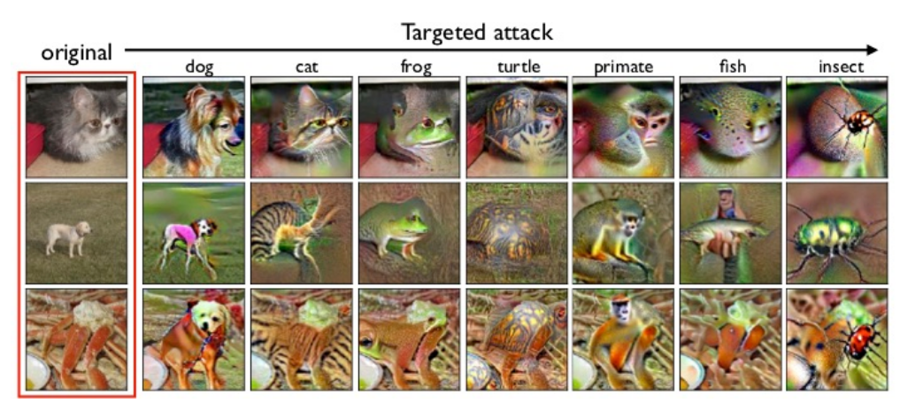
對抗強健模型應用於影像轉譯,此處列舉幾例效果較好的例子。(圖片來源:L. Engstrom et al., 2019.)
以影像修復為例(下圖),原始圖像被部分挖空模擬圖像缺損(第二列),即使模型所修復的圖像(第三列)與原始圖像(第一列)不盡相同,但對人類來說都還在合理範圍內,若非細看,一時可能還無法察覺違和之處。此處僅列舉幾例簡短說明,原始論文中作者尚提供多項互動式範例,相當推薦讀者可以動手體驗。

相較於以往電腦視覺領域所提出各種複雜的實作方法,Engstrom所提出的強健模型不僅相對單純,也讓我們發現基本分類器除了簡單的分類外,也有許多潛在的應用空間,這是當初僅考慮對抗安全和模型可靠度時所未曾預見的。
編譯來源
Gradient science, Robustness beyond Security: Computer Vision Applications, 2019
參考資料
- Santurkar et al., “Image Synthesis with a Single (Robust) Classifier”, arXiv.org, 2019.
- Engstrom et al., “Adversarial Robustness as a Prior for Learned Representations”, arXiv.org, 2019.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)