
給AI一個安全、舒適的學習環境

撰文/許守傑
環境探索的風險
強化學習(Reinforcement Learning)的靈感來自於心理學中的行為主義,認為行為是生物與環境互動的結果,並能透過獎勵或懲罰而強化。套用於AI之上,便是利用適當的獎勵函數(reward function),強化智慧體在反覆試錯的探索過程中所表現出有助於達成任務的「良好」行為,並降低無效行為的出現頻率。然而探索本身就是一件有風險的事,如何防止智慧體在過程中傷害周遭人事物的安全,並沒有想像中的簡單。
舉例來說,若自動化工廠想以強化學習訓練機器人手臂來組裝零件。一開始時,機器人可能會試著隨機搖動手臂,但這樣就有可能傷害到周遭的工作人員。雖然在這樣的情境中,我們可以緊急停機或將機器手臂周圍淨空來防止可能的危險,然而隨著AI的應用場域愈趨多樣,這類的預防措施不一定可行,也就必須考慮其他的安全探索策略。
受限的強化學習
然而一般的強化學習很難做到這一點,因為這意味著在設計獎勵函數時,需要同時考慮任務達成效率與安全要求這兩個基本上互斥的目標;OpenAI認為「受限的強化學習」(Constrained Reinforcement Learning)會是更好的選擇。受限與一般的強化學習類似,只是除了獎勵函數外,另外增加了成本函數(cost function)來限制智慧體。假設我們想讓自駕車從A點開到B點,除了以獎勵函數來鼓勵智慧體用最少的時間完成任務外,同時也以成本函數約束自駕車的駕駛行為必須符合交通規則。如此一來,開發者就不需要在效率與安全兩者間做出取捨,而是可以選擇想要的結果,讓演算法自主探索。
除此之外,受限的強化學習還有另一項優點。以上述同樣的例子為例,假設我們的獎懲機制是每次智慧體到達目的地時都會收到一筆車馬費(與抵達時間成反比),但在途中若與其他車輛發生碰撞也需支付一筆罰款。在一般的強化學習中,碰撞罰款通常是固定的。這樣的設計──尤其當完成任務的獎勵遠超過所設定的固定罰款時──很容易使得智慧體只為了獎勵而完全不理會車禍的風險;相對的,在受限的強化學習中我們可以在一開始訓練時選擇一個可接受的碰撞率作為最低的安全標準,一旦智慧體碰撞次數超過該標準便大幅提高罰款,使得任務獎勵變得沒有誘因,智慧體也就不會因為貪快而無視其他用路人的安全。
安全的學習環境
即使如此,在受限強化學習AI訓練完成前,仍然需要一個(對周遭其他人)安全的學習環境。Safety Gym便是OpenAI專為強化學習AI所設計的一組工具,提供各種學習環境並備有不同的難度與複雜度。目前套件中預設有Point、Car和Doggo三種機器人,AI需要學習控制各類機器人並完成三種預設任務之一,每種任務各有兩種難度。

以Doggo機器人為例,由左至右的任務分別是抵達指定地點、按下指定按鈕和拖拉物件至指定地點(綠色圓椎)。藍色圓為指定不得觸碰的區塊,當機器人不慎觸碰便會出現如列二的紅色警示燈。(圖片來源:OpenAI, Safety Gym, 2019.)
開發團隊在Safety Gym上試行各種強化學習模型,並繪製出如下圖的學習曲線,建立各模型的基準效能。
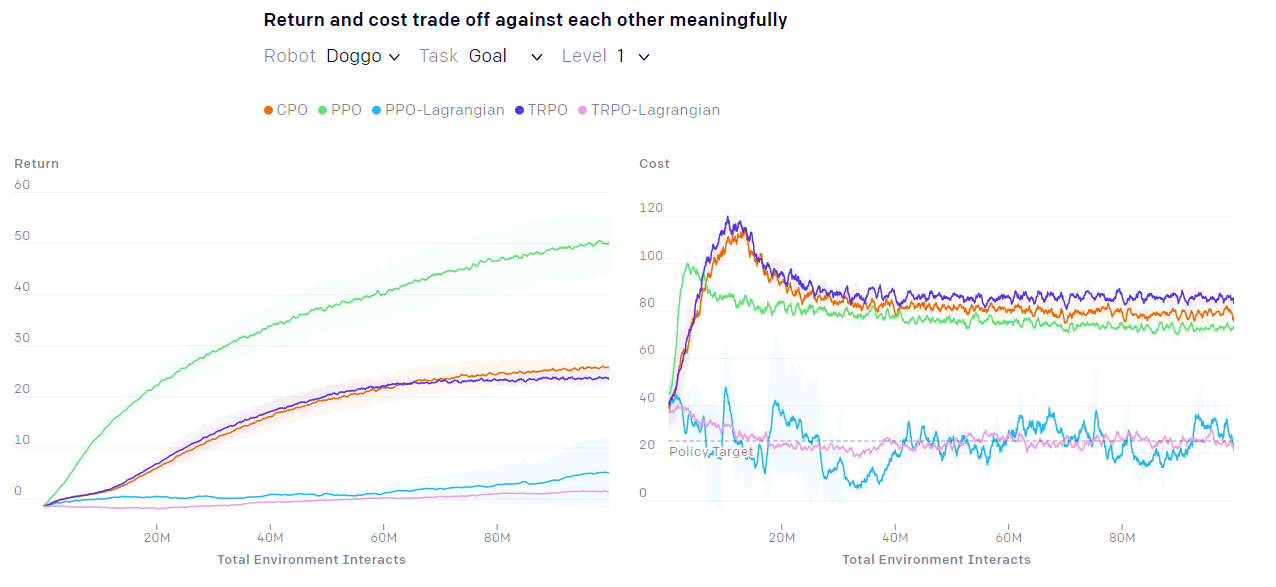
針對「操作Doggo機器人移動至指定地點」這項任務,各種(包含一般與受限)強化學習模型的學習曲線。(圖片來源:OpenAI, Safety Gym, 2019.)
除了透過這樣的開源框架,任何AI開發人員都能夠輕鬆地在AI的安全性上進行協作外,OpenAI的最終目的是希望將Safety Gym推廣為所有強化學習AI的安全標準測試,就像我們已經可以以特定任務來量化系統的準確度與表現一樣。
編譯來源
OpenAI, Safety Gym, 2019
參考資料
- A. Ray et al., “Benchmarking Safe Exploration in Deep Reinforcement Learning”, openai.com, 2019
- J. Achiam et al., Constrained Policy Optimization, arXiv.org, 2017
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)