
獨角獸=70%馬+30%犀牛 一張圖教會AI三種「動物」

編譯/許守傑
更有效率的學習方法
傳統的機器學習模型訓練方式十分仰賴大量的學習資料,例如為了使模型能夠辨別一匹馬,便需要提供數千張馬的圖像,這不僅是許多企業(尤其是資料取得、存取不易的領域)遲遲不願涉足AI的主要原因之一,也是(監督式)機器學習與人類學習最大的不同之處。
在人類的學習過程中,幼兒通常只需要看少量(有時候甚至完全不需要任何)範例,便有辦法正確辨識一個物件。好比說給兒童分別看一頭馬和一隻犀牛的照片,並且告訴他獨角獸是一種介於兩者之間的傳說動物,孩子便可以輕易認出故事書插圖中的獨角獸。
人類與機器在學習效能上的巨大差異,帶給了科學家啟發:有沒有可能讓AI模型也能像小朋友一般聰明,只需要少少的訓練資料就能達到一樣的學習效果呢?加拿大滑鐵盧大學(University of Waterloo)的一篇新研究將這種學習方法稱為「LO-shot學習」(Less than One-shot learning,比單樣本更少的學習)。
資料蒸餾
以廣受歡迎的電腦視覺資料庫MNIST為例。MNIST收錄各式各樣的手寫數字影像,從0到9共6萬筆資料,常被用來訓練或測試新的模型。在過往的研究中,麻省理工學院的科學家發明了一種資料萃取技術,經過精心設計和最佳化後,可以將整個MNIST的資訊量以10張影像表示(也就是將大量資料濃縮為一小筆資料)。兩者對訓練或測試一個模型而言是等效的,也就是說:用這10張影像訓練出的模型,與直接使用MNIST訓練的模型,在圖像辨識的準確度上勢均力敵。

圖一、MIT科學家將MNIST壓縮到僅剩下10張影像。(圖片來源:Tongzhou Wang et al., 2018.)
滑鐵盧大學的研究人員希望進一步改進這個「資料蒸餾」(data distillation)的過程:如果可以將6萬張影像縮減到10張,為什麼我們不將它再壓縮到5張呢?他們發現訣竅在於創造一個同時具有多個數字特徵的影像,就好像「獨角獸」同時具備「馬」和「犀牛」的特徵,但本身既非「馬」,也非「犀牛」一樣。
舉例來說,以往我們會直接將「3」標註為「數字3」;但「3」的樣子看起來其實與數字「8」有幾分相似,與數字「7」相去甚遠,於是我們可以換個方式告訴機器:這個影像是60%的數字3、30%的數字8和10%的數字0。這種「軟標籤」(soft label)就是資料蒸餾的關鍵,使得單一圖像可以承載更多資訊。
軟標籤的驚人成果
然而單一圖像上,最多可以疊上多少類(category)的軟標籤呢?答案是,幾乎沒有上限。理論上模型只需要兩筆資料,就可以分出數萬種資料類別。研究人員在數學上證明了這一點,並通過「k-最近鄰居演算法」(k-Nearest Neighbor,kNN,最簡單的機器學習分類法之一)演示LO-shot學習的驚人成效。
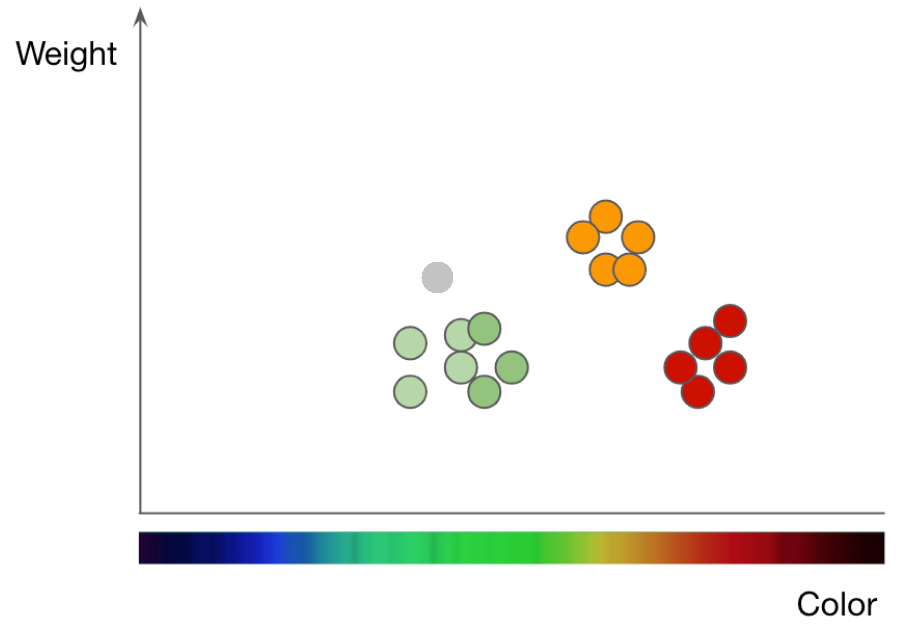
圖二、以「顏色」及「果重」區分「蘋果」與「橘子」兩類水果。(圖片來源: 改編自Machine Leaning 101, Jason Mayes)
什麼是kNN?這裡可以圖二簡單解釋。橫軸的「顏色」(colour)與縱軸的「果重」(weight),是我們選擇用以區分「蘋果」與「橘子」兩種水果的特徵。透過觀察與秤重,我們可以將手邊確定種類的水果標示在圖中,例如紅、綠分別是紅色與綠色的蘋果,橘色資料點代表橘子(訓練資料)。灰色點,則是一顆顏色與果重已知,但種類未知的水果;按照它在平面上的位置,由於離它最近的鄰居是綠色資料點(綠蘋果),所以我們推估應該也是一顆(綠)蘋果,這就是kNN的分類原理。
如果像灰色點這樣的取樣點夠多,我們就可以畫出紅、綠、橘三者各自在圖二這張二維平面上所佔據的區域。研究人員發現:透過操縱訓練資料的軟標籤,我們可以在分類空間上切割出任意幾何色塊,即使遠超過訓練資料的數量。
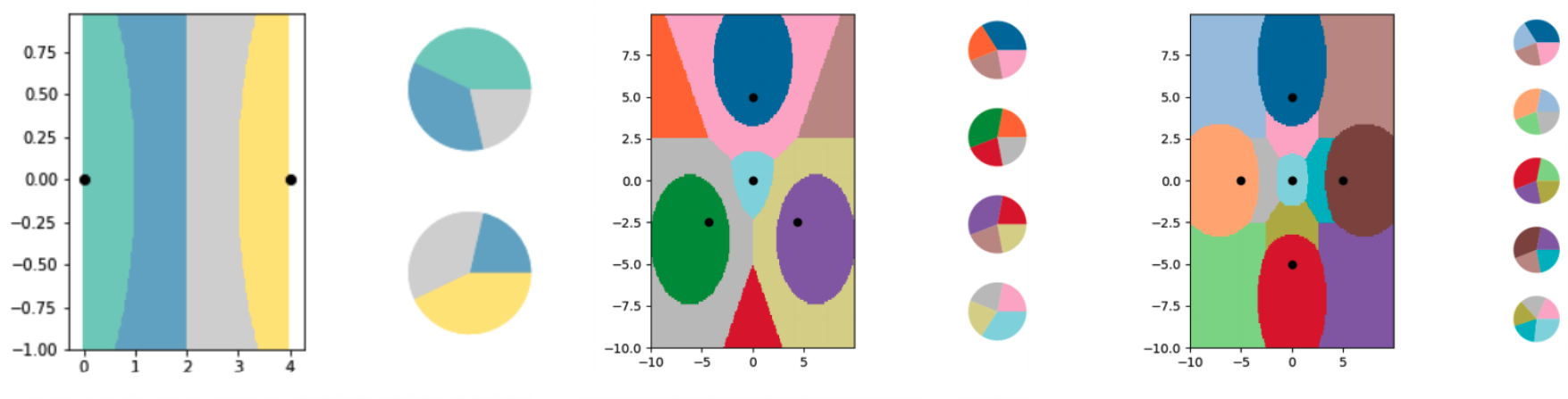
圖三、 研究人員以kNN演示LO-shot學習的潛力。透過操縱軟標籤(每個平面右側的圓餅圖),可以在平面上畫出任意幾何色塊(資料類別的邊界線)。可以看到劃分出的類別數(色塊數)比資料點個數來得多。(圖片來源:Ilia Sucholutsky et al., 2019.)
當然,這種方法還是有其局限性,比如說屬性較複雜的資料集,軟標籤的設計也會越困難。但最重要的是,LO-shot學習方式從根本上減少了訓練一個AI模型所需的資料量,解決AI應用的頭號問題;此外,它還可以改善資料的隱私性,因為需要個人提供的資訊量更少。隨著這樣能夠大幅提升效率的新創見出現,相信未來的機器也能在學習上更貼近人類,發揮更大的功效!
編譯來源
K. Hao, “A radical new technique lets AI learn with practically no data”, MIT Technology Review, 2020.
參考資料
T. Wang et al., “Dataset distillation”, arXiv.org, 2018.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)