
楊立昆 Yann LeCun(1960-)
與Hinton最初是在一次會議上相遇,發現彼此有著相同的研究主題,於是離開法國遠赴加拿大成為Hinton的博士後研究生。他開發的手寫數字辨識模型LeNet,不但是電腦視覺常見的卷積神經網路(Convolutional Neural Network,CNN)原型,更是首次將反向傳播演算法付諸實踐(於是證實Hinton的想法是可行的)。目前任教於紐約大學,同時是Facebook的首席AI科學家。在2016年的一場會議中,以一個「蛋糕的比喻」強調無監督式學習的重要性,卻意外在學術圈引起軒然大波。
撰文/Balboa Crenshaw(現職為數據科學家)|編輯/高敬堂
審訂/許志仲 (國立屏東科技大學資訊管理系助理教授)
●「2001太空漫遊」到單板機
1960年7月8日,Yann André Le Cun出生於法國巴黎西北邊一個小鎮上;由於日後發展的重心著重於美加兩國,為了避免英語使用者常將自己姓氏的一部分「Le」誤認為中間名,於是改變姓氏書寫方式為「LeCun」。父親是一位航空機械工程師,母親是一位家庭主婦,另外還有一位哥哥一同長大。小時候的LeCun受到父親的影響,已經對各種科學與工程感到強烈的興趣,常常與哥哥一起建造飛機模型與電子玩具。九歲那年,他在一次偶然的機會下看了「2001太空漫遊」(2001: A Space Odyssey)這部電影,那是他第一次看到「有智慧」的機器,以及人類智慧如何演進的故事,在LeCun的心中埋下了好奇的種子。
17歲那年,他買了生平第一部電腦。那是一台單板機(single-board computer),只有一個小小鍵盤與一個只能顯示六位數字的螢幕,除了必須自己編程,更重達四公斤。LeCun因為對文藝復興音樂、爵士樂情有獨鍾,也能吹奏雙簧管、長笛等各種古典樂器,便利用這台單板機打造出簡單的「管樂合成器」(wind synthesizer)。當然,在玩音樂的同時,LeCun的編程能力也有長足的進步。
●大學時的兩本書
大學時,LeCun就讀電機工程。那時他修了很多應用數學與物理學的課,也開始對神經科學起了興趣。他做了一些現在可以稱為「人工智慧」的專題,不過,是大學時期讀到的兩本書堅定了LeCun未來的研究方向與興趣。
一本叫做《語言與學習》(Language and Learning),這本書透過哲學家Jean Piaget與語言學家Noam Chomsky兩人之間的辯論,來探討語言的本質:語言是與生俱來的天賦,還是後天學習的能力?其中關於「學習機器」(learning machine)的討論更深深吸引著LeCun;另一本《感知器:計算幾何學概論》(Perceptrons: an introduction to computational geometry),則是由人工智慧的先驅Marvin Minsky與Seymour Papert合著。這是LeCun第一次接觸到「感知器」(perceptron)這個名詞,對於打造一個「可學習的機器」躍躍欲試。只是,同一本書中也同時點出了作為單層神經網路的感知器其實應用有限,於是無論是「感知器」或「可學習的機器」,這類結合神經科學與電腦科學的理論在當時的學術圈基本上已經被人遺忘。復興,於是成為LeCun繼續向前的動力。
●人工神經網路的復興
LeCun在巴黎第六大學(又稱Université Pierre et Marie Curie,現已與巴黎第四大學合併為Sorbonne Université)攻讀博士的第一要務,便是突破過去1960年代感知器神經元的限制,發展出「多層神經網路」(Multi-layer neural network)與今日「反向傳播演算法」(Backpropagation)的雛形。
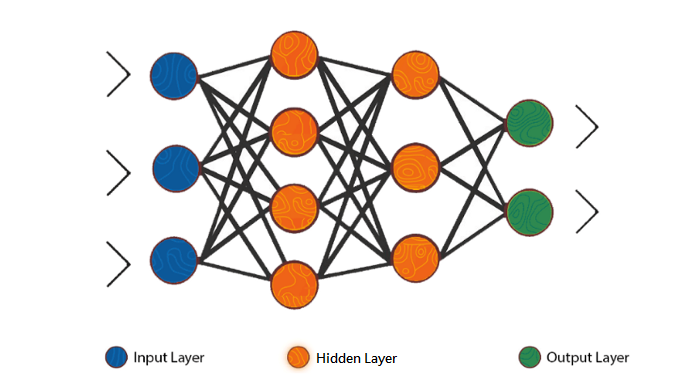
一個(多層)人工神經網路模型,是由一個個「神經元」(neuron;沒錯,正是沿用了生物學上的名詞)組成,可以大致分為三類:第一類是輸入的訊號,由「輸入神經元」組成,可以是影像、聲音或是其他任何你想研究的訊號,通常稱之為「輸入層」;第二類為通稱「隱藏層」(hidden layer)的結構,是人工神經網路的核心所在:隱藏層有幾層?每層又包含多少個神經元?每個神經元又應該對收到的訊號做什麼(專業術語是:乘上多少「權重weights」並加上多少「偏差bias」)?種種參數都關乎著模型的成敗;最後一類是「輸出層」(output layer),這是輸入的訊號經過隱藏層運算之後得到的結果。
「反向傳播演算法」便是依據輸出層的結果來分析與修正模型,而這段「分析與調整參數」的程序,正是每個人工神經網路正式上路前的前置「訓練」。由於是由最後一層的輸出層開始「往回走」,經過隱藏層,到一開始的輸入層,逐步調整每個神經元的權重與偏差,直到最後得到的結果符合我們的期待,因此稱為「反向」傳播演算法。而這種預先知道標準答案或預期機器應該給出什麼結果的學習方法,又稱作「監督學習」(supervised learning)。
雛形雖然是有了,但是當時LeCun的機器處理矩陣乘法(神經元訊號操作時會用到)的運算速度頗慢,實在不足與外人道。直到一次研討會,LeCun結識了當時由美國遠道而來的Geoffrey Hinton,發現Hinton竟然也在研究反向傳播演算法。兩位好像從平行宇宙而來的知音,一拍即合,除了共同發展出更完善的反向傳播演算法,Hinton也邀請LeCun參加隔年的暑期研討會。那是1986年的夏天,可以說是現代人工神經網路復興的起點。
1987年,27歲剛取得博士學位的LeCun,在成功重拾眾人對神經網路的信心後,跟著Hinton來到加拿大,在多倫多大學展開他的博士後研究員生涯。同年冬天,在蒙特婁的一場演講上,一個年輕小伙子提出了許多聰明的問題,擄獲了LeCun的目光,因此認識了另一位未來的工作夥伴──Yoshua Bengio。
●AT&T貝爾實驗室
1980年代末,LeCun帶著Bengio與其他組員,來到了當時美國電信巨擘AT&T所屬的實驗室──AT&T貝爾實驗室(Bell Laboratories,後陸續易主,目前由Nokia所有)。這座美國最大的業界研究機構,培育了無數菁英,許多發明至今依然影響深遠。LeCun與他的研究小組很快就將反向傳播演算法付諸實踐,應用在「卷積神經網路」(Convolutional Neural Network,CNN)上。這種進階版的人工神經網路,可以自動尋找資料中的「型樣」(pattern)或「表徵」(representation),於是經常應用在圖形與文字影像的辨識上。而它的靈感竟來自於動物(包含人類)的視覺系統!
在動物的初級視覺皮質中,存在著S(simple cells,簡單細胞)與C(complex cells,複雜細胞)兩種細胞。S細胞只針對特定走向的條紋(準確來說,是明暗對比的邊緣)有反應,例如:一群S細胞可能只針對南北走向的直條紋有反應(姑且稱作「直條S細胞」),另一群則只針對東北-西南走向的條紋有反應。因為這種特性,S細胞的功能就像一個濾鏡(filter,或稱kernel),直條S細胞就只看的見視野特定區域中的直線條紋。作為S細胞的下游,C細胞彙整了有著相同條紋偏好的S細胞所傳來的訊息,於是相較於單一群S細胞,所看到的不再只是小區塊內的直線條紋,而是更完整的線條。
日本電腦科學家福島邦彥在1979年仿照這樣的階層架構,開發出一種稱作「新認知機」(Neocogintron)的多層人工神經網路,也就是卷積神經網路的前身。S細胞「加上濾鏡」的這個步驟,是利用數學上一種稱作「卷積」(convolution)的運算完成,也是「卷積神經網路」這個名稱的由來;C細胞「彙整」來自S細胞資訊的動作,則被稱為「池化」(pooling)。在人工神經網路中,池化後的影像會再被送到另一層S細胞,「卷積→池化」的步驟會重複數次,由線條、夾角到最後完整圖形,得到更全面、抽象的圖像「特徵」(feature)。LeCun便是在這樣的基礎上,開發出能辨認手寫數字的模型──LeNet。LeNet最後成功商業化,被金融和郵務機構拿來讀取信件或支票上的手寫郵遞區號、數字與條碼,不但是LeCun在業界的第一桶金,也證明了當初與Hinton一同鑽研的反向傳遞演算法與卷積神經網路是可行的。
只是好景不常,對於人工神經網路寄予厚望的人們很快不再滿足於手寫數字的辨認。然而更複雜、多樣的圖像,意味著更多層、更深的隱藏層,隨之提升的運算量卻遠遠超出當時硬體設備所能負荷。登高易跌重,眾人很快失去了耐心,人工神經網路又再次被打入冷宮。與此同時,AT&T為了與其他電信公司競爭,傾心專注於通訊服務的經營,於是將公司內部從事設備開發與製造的部門拆分出來,原先的實驗室則被一分為二,成為「貝爾實驗室」與「AT&T實驗室」兩個不同公司下的研究部門。雖然LeCun可以留在AT&T實驗室繼續自己的研究,但是許多其他領域的朋友,包含當初協助他們將LeNet拓展到金融服務業的工程人員,都被拆散到了另一個實驗室,這使得所有相關計畫被迫暫停。
LeCun於是有整整六年沒有再碰人工神經網路。在這段稱為「第二次寒冬」的時間裡,LeCun雖意志消沉卻非一蹶不振。他重整之前寫到一半的論文,並與其他組員研發出新的圖片壓縮技術──DjVu。
DjVu的特點,在於將圖像中重複性高的形狀獨立出來,當再次出現時只要記錄位置資訊即可,因此可以有效壓縮高解析影像,也是其名稱取自法語déja vu(意為似曾相識)的原因。許多藝術與文化產業的檔案,例如全彩雜誌內頁的掃描,若以djvu的檔案形式儲存,相較於傳統jpeg或pdf,檔案大小可以小上五倍以上。
所幸硬體設備的效能隨後迎頭趕上,特別是近幾年來GPU(Graphic Processing Unit,圖像處理器)在許多科學運算上逐漸嶄露頭角。許多研究者發現GPU對於可高度平行化的簡單任務(例如卷積),有著取代CPU(Central Processing Unit,中央處理器)的巨大潛力。自此之後,接著GPU結合人工神經網路,漸漸走出低谷
●產學兩棲
2002年,LeCun離開了AT&T實驗室,帶著組員來到日本電氣公司(Nippon Electric Company,NEC)位於美國普林斯頓的研究中心。無奈當時NEC研究中心正值轉型期,許多LeCun想合作的研究對象都相繼出走;一年半的短暫停留後,LeCun再次轉移陣地來到紐約大學,一直待到今日。
他先後與其他學者在紐約大學成立了數據科學中心,並擔任中心的共同主任;2013年,被Facebook看上,獲聘擔任其下AI研究部門──Facebook AI──的主任。今日Facebook與Instagram上的人臉辨識與自動標註功能,很大一部分是LeCun與其團隊的研究成果。也因為如此,LeCun積極倡導在法律、金融與醫學界行之有年的產學合作制度──讓從事資料科學研究的學者一部分時間待在業界、另一部分時間在大學任教──引進商界的資源與經營模式,相信AI的未來發展將如虎添翼。
雖說這樣「產學兩棲」的學者不在少數,然而樹大難免招風。LeCun的這個舉動引起了紐約大學其他同僚的非議,認為這會排擠一名教授投注在教學上的時間與精力,正如一個人「不能同時服侍兩個主人」。孰是孰非,或許只有時間才能證明了!
2018年,LeCun因為「在理論與工程上的突破,使得深度神經網路成為電腦世界一個不可或缺的元素」,與Hinton及Bengio共同獲得了有「電腦科學界的諾貝爾獎」之稱的杜林獎(Turing Award)。除了是對研究的肯定,這座獎項更為Hinton、LeCun與Bengio三人之間,這段亦師亦友的感情下了最好的註解。即便如此,LeCun卻似乎不滿足於此。
他曾打過這麼一個比方:
人類與動物的學習大都是非監督學習。所以說如果「智慧」是一塊蛋糕,那麼非監督學習才是蛋糕本體,監督學習則是那層糖霜,強化學習(編註:另一種機器學習方法,其原理類似心理學上的「制約」)不過是上頭的櫻桃。
Most of human and animal learning is unsupervised learning. If intelligence was a cake, unsupervised learning would be the cake, supervised learning would be the icing on the cake, and reinforcement learning would be the cherry on the cake.
監督學習所訓練出的模型,通常只有在特定目標、狹隘的範圍內才有不錯的成效,這與人類舉一反三、鑑往知來的學習方法有很大的區別。不難看出對於LeCun而言,我們距離真正的「智慧」還有很長一段路要走。
參考資料
- Eye on AI. (2019). Episode 17 – Yann Lecun [Video].
- LeCun, Y. (2018). Facebook’s chief AI scientist says that Silicon Valley needs to work more closely with academia to build the future of artificial intelligence.
- LeCun, Y. (2020). Yann LeCun’s Home Page.
- LeCun, Y., Boser, B., Denker, J., Henderson, D., Howard, R., Hubbard, W., & Jackel, L. (1989). Backpropagation Applied to Handwritten Zip Code Recognition. Neural Computation, 1(4), 541-551. doi: 10.1162/neco.1989.1.4.541
- Lindsay, G. (2020). Convolutional Neural Networks as a Model of the Visual System: Past, Present, and Future. Journal of Cognitive Neuroscience, 1-15. doi: 10.1162/jocn_a_01544
- Minsky, M., & Papert, S. (1988). Perceptions. An introduction to computational geometry. The MIT Press: Cambridge.
- Piaget, J., & Chomsky, N. (1981). In Piattelli-Palmarini, M. (Ed.), Language and learning: The Debate between Jean Piaget and Noam Chomsky. Cambridge, Mass: Harvard University Press.
- Recht, B., Forsyth, D., & Efros, A. (2018). You Cannot Serve Two Masters: The Harms of Dual Affiliation.
(本文為教育部「人工智慧技術及應用人才培育計畫」成果內容)