
從一張2D影像直接建構3D資訊
■面對一張影像,我們「得到」的比起我們實際「看到」的豐富許多。我們的大腦在理解影像時,會將常識應用在其中,解讀影像沒有包含的部分。例如:看到桌子的三隻腳,我們能推論出被擋住的第四隻腳的形狀和顏色。要訓練人工系統達到相同的空間認知能力,需要大量手工標記的數據。對此,DeepMind公司近日發展一種人工智慧,能蒐集數據並訓練自己,突破數據不足的限制。對於一張2D影像,它能建構出3D的空間資訊,並且對從未看過的場景做出正確的預測。
 撰文|陳奕廷
撰文|陳奕廷
面對一張影像,我們「得到」的比起我們實際「看到」的豐富許多。我們的大腦在理解影像時,會將常識應用在其中,解讀影像沒有拍到的部分。例如:進入一個從未看過的房間,看到桌子的三隻腳,我們能推論出被擋住的第四隻腳的形狀和顏色。儘管我們沒有看遍房間的每一個角落,也仍然可以大致上畫出房間的空間形狀,或是想像出從另一個角度看房間會是什麼樣子。
這個空間視覺認知能力對人類來說毫不費勁,但對人工系統來說卻相當不容易。直至今日,最先進的視覺辨識系統大多是用大數據訓練的人工智慧,訓練的過程需要大量手工標記的數據。取得這些數據非常昂貴且費時。因此,現有的數據大都只包含空間中的一小部分而已,人工智慧的認知能力被這些數據侷限。在現實應用中,我們需要能完整認知空間的資訊的人工智慧。
●從2D影像獲得3D資訊
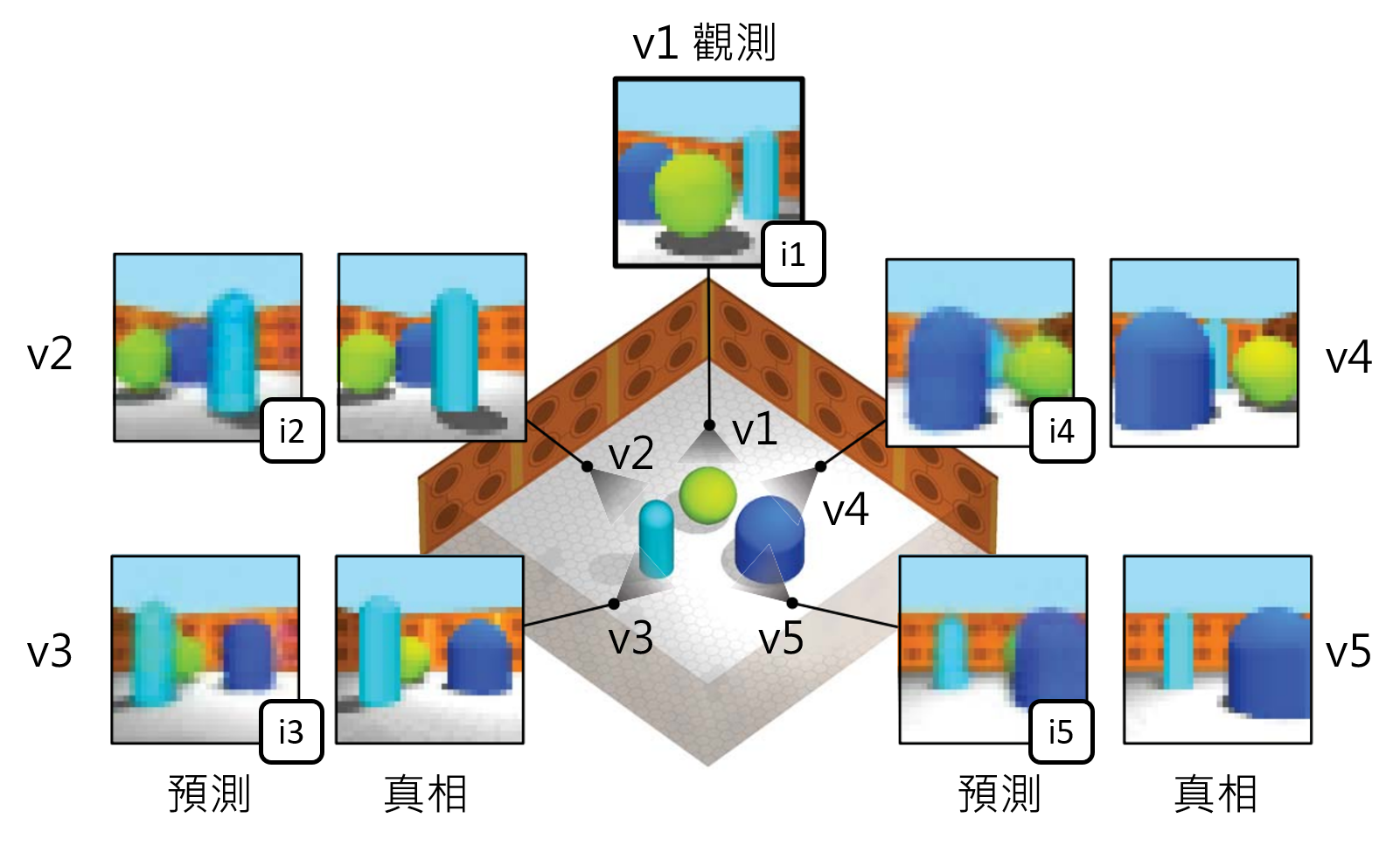
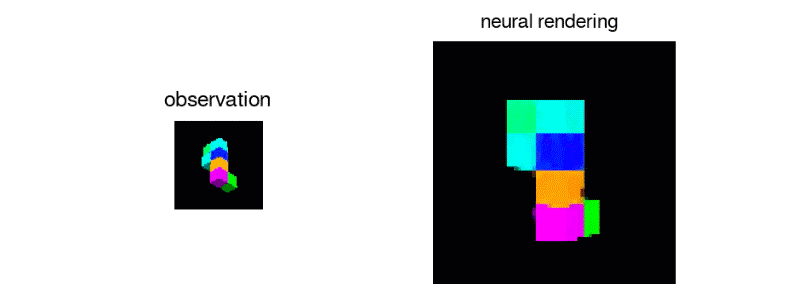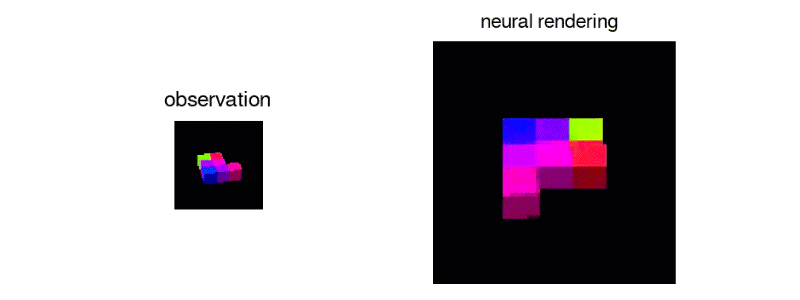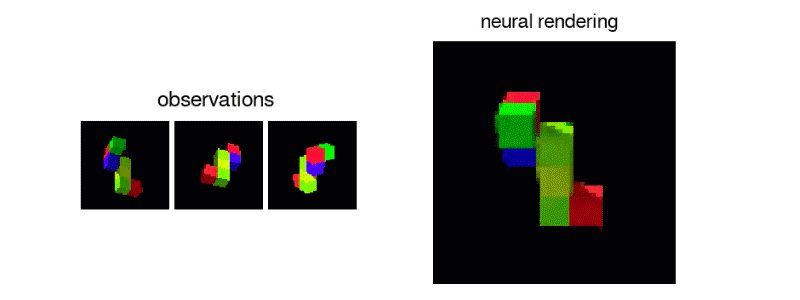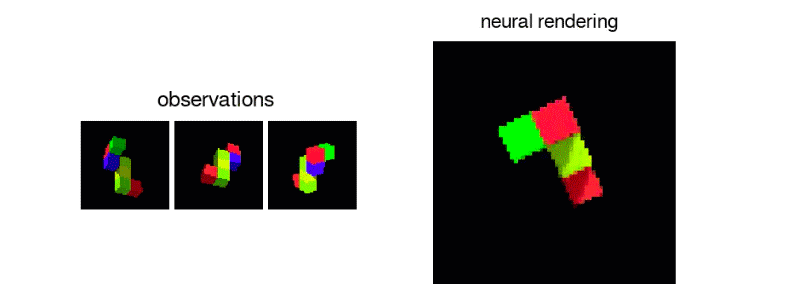
位於英國倫敦的Google DeepMind 近日發展一種人工智慧,能蒐集數據並訓練自己,突破數據不足的限制。這種人工智慧被稱為「生成式詢問網路(Generative Query Network, GQN)」。實際應用情形如圖一。在一個空間中,將一個視角v1(包含座標和方向)和從這個視角看到的影像(i1)輸入人工智慧,人工智慧能依此建構出空間的資訊。接著,人工智慧能對沒看過的視角做預測,例如:在沒看過的視角v2它能預測一張影像i2,這個預測影像和真相非常接近。在圖一中其他沒看過的視角v3, v4和v5也有一樣的表現。只看一張影像就能建構3D空間的資訊,並對其他未曾看過的視角做了幾乎正確的預測,效果非常驚人。
●生成式詢問網路
以下介紹這個人工智慧的原理。如圖二所示,它的架構分為兩個階段:空間特徵網路F和生成網路G。前者輸入一個視角v1(包含座標和方向)和v1上拍的一張影像i1,輸出一個特徵向量r1。空間的各種資訊(包含一個房間的大小、有哪些傢俱物品、傢俱顏色材質等) 被抽象的壓縮在這個特徵向量r1之中。如果有多張影像輸入,例如圖二中的i1和i2兩張影像,經過處理後變成r1和r2兩個特徵向量。這兩個特徵向量分別包含空間的部分資訊,相加之後得到更多資訊。越多影像相加而成的特徵向量r包含越完整的空間資訊。接著,演算法進入第二階段:生成神經網路G(圖二)。除了輸入空間特徵向量之外,使用者還需要輸入一個詢問:「在視角v3上,景色看起來怎麼樣呢?」。生成網路會根據特徵向量r和視角v3,生成一張影像,預測從視角v3看整個空間的形貌。
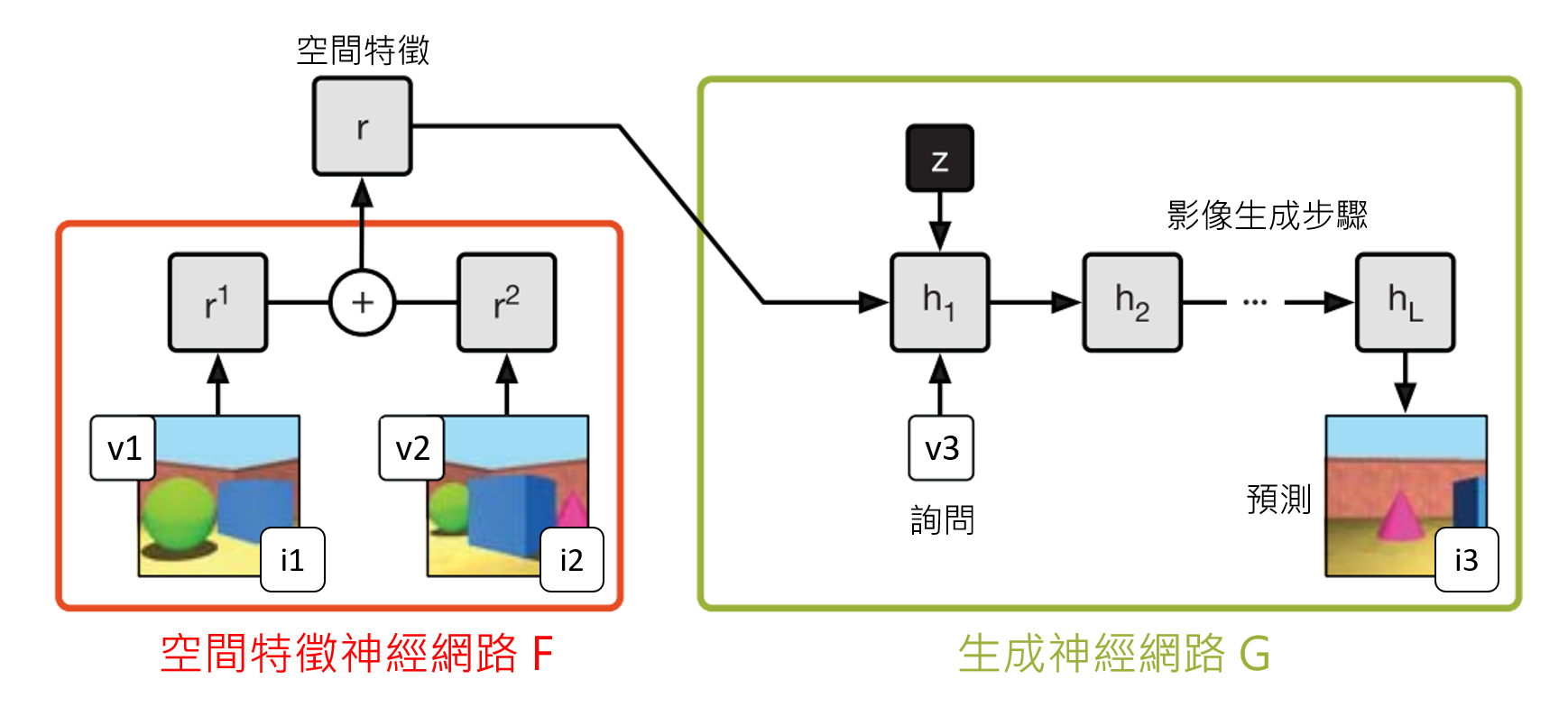
在訓練這個人工智慧時,特徵和生成網路是一起訓練的,這樣的訓練架構有兩大好處。第一,不需要手工標記的數據。在大部分方法中,數據需要被人類手工定義每個像素的景深等3D資訊當作正確答案,人工智慧再從這些已標記的數據中學習。相較之下,在生成式詢問網路中,3D資訊被隱藏在空間特徵r之中。在學習的過程中,對答案的地方不是這個3D資訊r,而是由3D資訊生成的2D影像i3。透過這樣2D到3D再到2D的方法,讓人工智慧對手工標記的數據需求降低,訓練時能使用的數據更多,表現更可靠。第二,它能處理較複雜的問題。這個架構將「學習特徵」和「學習生成」的部分完全分開。特徵網路專精於學習空間最重要的抽象特徵,例如長方體各個節點的座標。生成網路專精於學習輸出影像,例如畫出長方形上的材質和陰影。這樣專業分工的架構,使得人工智慧學習力更強。
●與3D相機的比較
除了使用人工智慧之外,另一種從2D影像獲得3D資訊的方法是使用3D相機。它的原理是對同樣的景色用稍微不同的視角拍兩張照片。在兩張照片中,相同的物品會有稍微不同的位置。差異越小的物品代表距離越近,反之代表越遠。台灣的嵌入式相機模組產業是世界知名的,在許多無人車、無人機和亞馬遜公司的無人商店AmazonGO使用的3D相機都是台灣製造。相較人工智慧,3D相機計算速度和準確度高上很多,在商業和工業上都達到應用的標準。人工智慧的方法則還是在研究的階段,除了速度慢、準確度稍低之外,目前只能針對簡單的場景和物體做預測。但是不同於只能分析「看得到的物品」的3D相機,人工智慧能預測「沒有看到的物體」的形貌,這方面相當具有潛力。
參考資料:
- S. M. Ali Eslami et al., Neural scene representation and rendering, Science, 360, 6394, 1204 (2018)
--
作者:陳奕廷,台大物理系學士,史丹佛大學應用物理系博士班就讀中。
![]()