
機器學習與人工神經網路(三):AlphaGo 怎麼下棋?
![AlphaGo擊敗歐洲圍棋冠軍,登上自然期刊(Nature)的封面。(參考資料[1])](http://case.ntu.edu.tw/blog/wp-content/uploads/2016/12/front-1.jpg)
撰文|陳奕廷
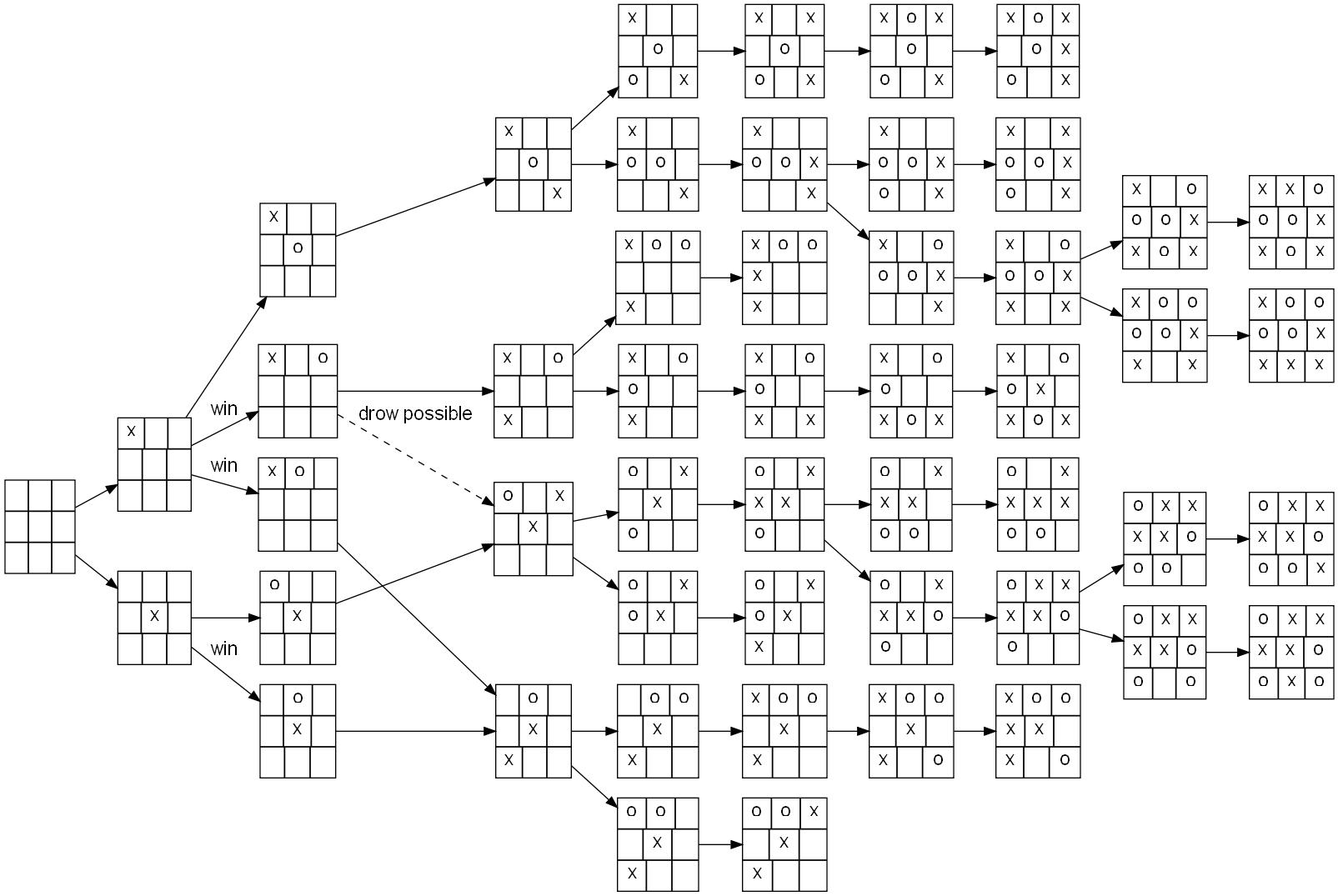
通常一場賽局(game)的發展可以用樹狀圖表示,將當下的可能性全部列出,並且分別推演接下來的步驟(圖一)。在圍棋和西洋棋中也能畫出樹狀圖。不同的是,西洋棋樹狀圖共有 10120 個不同的節點,比全宇宙的原子數目還要多(約 1080個)!更甚的事,在19*19的圍棋棋盤上,一共有 10360以上個可能性,是一個極度複雜的賽局。
●深藍如何擊敗西洋棋冠軍?
通常認為深藍透過暴力法計算可能的步驟,這個說法只對了一半。從上述的複雜度來看,不可能存在暴力解法找到必勝策略,因此深藍的演算法改用另一個策略,分為兩個部分:一個是上述的樹狀圖暴力法搜尋,但僅計算未來6步之內的所有可能性;第二,透過一個估計函數,算出6步之後盤面的勝率,深藍挑出其中勝率最高的路徑走。如此,深藍不必計算出所有的盤面,大大降低計算深度。但相對地,它只能挑選獲勝「機率」大的路徑,不能保證勝利。
簡而言之,深藍能否致勝取決於兩個條件:
- 電腦的計算能力。若能推算到第7步、第8步以後,盤面會越接近盤末點,估計出的勝率會越真實,決策也會越正確。
- 勝率估計函數的準確度。
當初 IBM 聘請幾位西洋棋高手為深藍設計這個函數。儘管當時函數的表現效果很好,但就像是在手寫辨識的例子中提到的一樣,人類設計演算法要付出極大心思,並且有其限制。在圍棋中,這將是深度學習能大展身手的地方。
●AlphaGo怎麼下棋?
上述的方法在圍棋上行不通。一場西洋棋對弈雙方平均一共進行約80手,而圍棋平均約有150手。若要有效評估每一步棋的勝率,必須向未來推算更多步驟。不僅如此,不同於西洋棋每個棋子移動的範圍有限,圍棋棋子可以任意擺放在19*19的棋盤上,每一步的樹狀圖很廣,推算未來所需要的計算量大上好幾個數量級。這也是為什麼在深藍獲勝後的20年間,圍棋仍被認為是人工智慧難以匹敵人類的棋藝。
![圖二、大幅減少計算的兩個關鍵:策略神經網路和估值神經網路。策略神經網路接受19*19的棋面(s),輸出一個19*19的數值陣列,每一個數值代表棋子下在該位置的機率(a)。估值神經網路接受19*19的棋面(s’),輸出該棋面的獲勝機率(v(s’))。(參考資料[1])](http://case.ntu.edu.tw/blog/wp-content/uploads/2016/12/Fig2.png)
第二種神經網路為估值網路(value network)。和深藍的估計函數的功能一樣,它讓 AlphaGo 僅需推算未來數步,剩下的交由估值網路來估計勝率,減少了樹狀圖探索的深度。但和深藍不同的是,這個估值網路不需要請圍棋高手來設計,而從透過千萬張棋譜訓練神經網路中的連結。
綜合來說,面對對手的一步棋,AlphaGo 會先用策略網路從所有可能性中,依照之前學習的經驗挑選幾步最可行的方案。針對這些可行的方案,估值網路算出它們的勝率,AlphaGo 從中挑選最佳的致勝方案。這種單從未來幾步棋的棋面評斷獲勝率的方式,可被稱為 AlphaGo 的「直覺」。有趣的是 Google 科學家另外融合了「快速推演」,即很快速但不準確地的推敲當前這步棋下到最後的結果。這像極了人類的思考方式,我們不僅透過直覺謹慎思考當下狀況,也大致推敲未來的情形。Google 科學家發現融合直覺和快速推演的結果,比單單使用兩者之一好上許多。
| 排名 | 姓名 | 性別 | 國籍 | 積分 |
| 1 | Ke Jie (柯洁) | 男 | 中國 | 3632 |
| 2 | AlphaGo | 男 | 英國 | 3592 |
| 9 | Lee Sedol (李世石) | 男 | 南韓 | 3508 |
表一:世界圍棋積分節錄。AlphaGo其實是一位男性。(source: updated on 12/09/2016 )
●AlphaGo 的勝利代表什麼?
回到文初的問題,AlphaGo 和深藍有什麼不一樣,讓世界這麼瘋狂呢?首先,在複雜度極高的圍棋中,AlphaGo 在對弈中計算的次數竟比深藍當時少了幾千次。這象徵著人工智慧已大幅進步。再者,這個進步並不只來自於計算能力。若只靠硬體科技的進展,人們預估至少要10年以後人工智慧才有機會在圍棋上和人類較勁。AlphaGo 利用深度學習,透過的策略網路和估值網路分別大幅減少計算的廣度和深度,是演算法上的突破。最重要地,這些算法基於人工神經網路,從大數據中學習,不需要請專家設計,因此不需要領域內知識(Domain Knowledge):深藍的算法僅適用於西洋棋,但AlphaGo算法的應用不局限於圍棋。這也是為什麼 Google DeepMind 總裁 Demis Hassabis 評論道:「AlphaGo 的目的不是要擊敗人類,而是要證明這種算法的能力,並用它解決現實生活中的問題。」
參考資料:
- David Silver et al., Mastering the game of Go with deep neural networks and tree search, Nature 529, 484–489 (2016)
- Christopher Burger, Google DeepMind's AlphaGo: How it works (2016)
--
作者:陳奕廷,台大物理系學士,史丹佛大學應用物理系博士班就讀中。
![]()