
視覺化AI的決策過程

編譯/臺大生醫電資所 葛竑志
AI的黑盒子
20世紀末紅極一時的街機遊戲─Atari系列,因其操作簡單、畫面精簡且分數計算容易等特性,常被用作訓練人工智能的絕佳環境,而重返眾人目光。這些AI通常是在「強化學習」(Reinforcement Learning,RL)訓練而出,通常包含兩個部份:實際參與遊戲的「玩家」(Agent)與給予前者回饋的「裁判」(Critic,亦稱Interpreter)。玩家採取的「動作」(Action),將

圖一、RL基礎架構(來源:Wikipedia)
會改變遊戲「環境」(Environment);另一方面,依據遊戲規則與環境「狀態」(State)的不同,裁判將給予玩家相對應的積分與獎勵(Reward),透過即時回饋機制,以強化(或弱化)玩家的特定行為,以達到預期目標。
以「太空侵略者」這款遊戲為例,若發出的子彈能成功擊中敵人,便能獲得一分,反之則無。AI玩家必須能夠憑藉過往經驗,理解到底在什麼樣的情況下,做出怎樣的動作與反應,隨之調整自己的策略(神經網路參數)以獲取高分。
只是,在這些遊戲之外,面對如與「小精靈」相似的「吃豆仁小姐」(Ms. Pac-Man),RLAI總是遭遇無法突破的瓶頸。而這也凸顯出一個無奈的事實:在輸入的資料與輸出的結果之外,我們對於其間到底發生了什麼、系統的判斷標準與決策機制等,其實近乎無知。
視覺化─顯著圖
今年(2018)7月國際機器學習會議(International Conference on Machine Learning)上,美國奧勒岡州立大學的研究團隊提出以顯著圖(Saliency map)為基礎的分析策略,打開AI的黑盒子。其基本原理,是透過將遊戲畫面上的特定區域模糊化處理,來判斷此處影像對於AI玩家的後續動作與決策是否至關重要,甚至影響最終的輸贏。
當然,這樣的概念並不新穎。過去所謂「雅可比顯著圖」(Jacobian Saliency),便是以神經網絡中節點的輸出值,對像素的輸入值作偏微分,所得出的一階偏導數矩陣形式─雅可比矩陣(Jacobian matrix)為基礎所繪製。當梯度大時,意味著神經網路節點,對該區塊的像素值較敏感。簡而言之:便是藉由調整遊戲畫面上特定像素的值,來判斷該區域是否為左右AI最終決策的關鍵。
然而,這種依據梯度變化(Gradient-based)繪製而出的傳統顯著圖,有著一大缺陷:像素值的任何細微變動,即使人類肉眼無法區分,都有可能造成AI最終決策的偏差。為了讓視覺化效果更加明顯,研究團隊選擇以減少局部資訊(Perturbation-based),來測試模型的輸出是否隨之變動,以釐清AI決策時的依據。
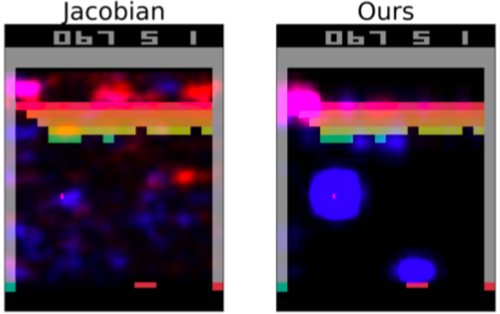
圖二、與傳統顯著圖的比較。藍色為玩家,紅色為裁判的關注點。(來源:S. Greydanus et al, 2018.)
黃雀捕蟬
同樣以「太空侵略者」為例,AI可以有兩種致勝策略:各方掃射,或鎖定特定目標逐一擊破。透過優化的顯著圖,研究人員觀察到「玩家」似乎是將焦點鎖定在特定目標上,計算時間與距離後再開火。當確定命中後,再轉移到下一個目標。而無論「玩家」或「裁判」始終都將目光放在自己與掩蔽物上,推測是希望利用掩蔽物躲避砲火,增加存活率的緣故。
另一方面,在「吃豆仁小姐」中,「玩家」的注意力則過分集中於豆子上,而忽略四處游走,甚至緊追在後的鬼。而「裁判」的回饋機制設定,也有著類似的問題,導致鬼的出現對「玩家」的行動決策影響甚微,無法領略主動迴避的重要性,並改變往後的行為模式。
而AI決策的視覺化,所關係的也絕非僅只是一場遊戲的輸贏而已。其他如自駕車系統,也通常是在RL架構下接受訓練。透過視覺化,研究人員在為系統「除錯」時,能更快縮小問題的方向,並即時修正。此外,若能親眼「看見」自駕車系統在切換車道時所注意的地方或背後的決策機制,對於無相關專業知識的一般大眾而言,也更能卸下心中的那份忐忑與猜忌。
編譯來源
Hutson, “Why does AI stink at certain video games? Researchers made one play Ms. Pac-Manto find out”, Science│AAAS, 2018.
參考資料
S. Greydanus, A. Koul, J. Dodge and A. Fern, “Visualizing and Understanding Atari Agents,” Proceedings of the 35th International Conference on Machine Learning, PMLR 80:1792-1801, 2018.