
Siri「聽」見你的心

編譯/台大電機系 吳奕萱
傳統評估方法
過去常見的方法,是讓患者填答健康狀況問卷(Patient Health Questionnaire, PHQ),了解患者過去的精神狀況與生活習慣。而後由醫療人員根據專業知識,由關鍵回答組合中評估個案的狀態。亦有人使用決策樹(decision tree),由特定問答模式,推估患者的沮喪情緒。然而這些方法的前提,是患者必須先回答特定的問題,因此應用範圍有限。
一種新的方法,則是從患者的說話特徵出發,分析其語音訊號隨時間的變化。2018年,麻省理工學院(MIT)研究人員便是利用神經網路模型,從對談的文字與音訊萃取語音特徵,直接從人們日常生活中的自然互動,搜尋沮喪情緒的跡象[2]。
從患者對談紀錄出發,尋找語音序列特徵
模型的訓練與測試,運用了虛擬醫師與142名個案的對談紀錄[3]。每段對談中包括直接的問題(例如:「你覺得自己內向嗎?」)與對話性的回覆(例如:「聽起來很棒!」)。收集的資訊包括音訊與交談內容的逐字稿。
這些個案皆有心理健康相關的因素,根據健康狀況問卷的填答結果標記為0~27分的「沮喪指數」(通常10分以上視為有沮喪的現象)。訓練資料集中約有20% 的「沮喪」個案。
模型架構:長短期記憶(LSTM)、上下文無關
訓練模型的目標是判定個案「沮喪與否」以及「沮喪的程度」,可分別視為二元、多元分類問題。
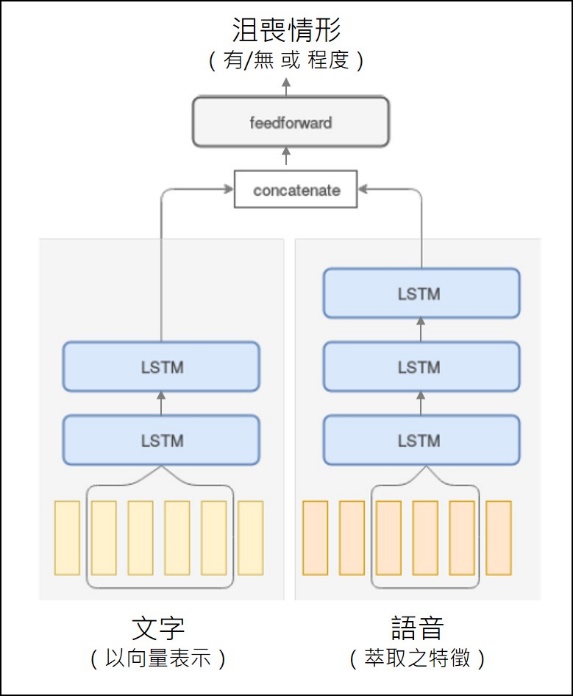
圖一、整合對答內容與語音資訊之模型(來源:T. Alhanai et al, 2018.)
首先,輸入的文字以Doc2Vec轉換為向量,音訊則以約 300 個特徵值表示。音訊的特徵來自一幀幀影格的音高、共振峰頻率、頻譜特性,例如:梅爾倒頻譜係數(Mel-scale Frequency Cepstral Coefficients,簡稱MFCC)。MFCC考量了人耳對不同頻率聲音的辨別程度,並取他們的平均值、標準差等統計資訊。
接著,以2至3層雙向LSTM(bi-directional Long Short-Term Memory)模型,分別處理文字與音訊輸入。激活函數(activation function)為tanh、sigmoid,並以交叉熵(cross-entropy)為損失函數(loss function)訓練模型,判斷這個人是否「沮喪」。
這是個「上下文無關(Context-free)」模型,因為機器沒有限定要接收到什麼類型的問答內容,意即判斷時不需仰賴對話中出現特定的問題與回答。此外,將資料以序列作為單位進行訓練的另一大好處,則是能考量整段對話的內容,以及語調隨時間的變化。學到這些與沮喪相關的語音特徵後,便能從新使用者所講的話語中,尋找相近的特徵。
模型的表現
模型衡量的標準是精確度(precision)、召回率(recall)、以及綜合前兩者的F1分數。在精確度上,模型判定為沮喪的個案有七成與醫師的判斷相同;在召回率上,實際的沮喪個案有 83 % ,順利為模型所偵測;F1 分數則達 77 %。相較於運用 SVM(Support Vector Machine,支援向量機)處理相關文字、音訊的模型(precision 60 %,recall 43 %)[4],有明顯的進步。
過去的研究曾顯示:有些字詞,如:「難過」、「低落」等,常伴隨較單調、波形較無起伏的音訊。而沮喪的人也傾向以較慢的語速說話,且詞與詞間有較長的停頓。目前研究人員正嘗試摸索模型是基於哪些語音特徵來決定使用者的沮喪程度,希望能為結果提供更多解釋,使人們對機器的判斷更有信心。
編譯來源
R. Matheson, “Model can more naturally detect depression in conversations”, MIT News, 2018.
參考資料
- T. Alhanai, M. Ghassemi, J. Glass, “Detecting Depression with Audio/Text Sequence Modeling of Interviews”, Interspeech, 2018.(code)
- J. Gratch, R. Artstein, G. M. Lucas, G. Stratou, S. Scherer, A. Nazarian, R. Wood, J. Boberg, D. DeVault, S. Marsella et al., “The distress analysis interview corpus of human and computer interviews” LREC, 2014.
- M. Valstar, J. Gratch, B. Schuller, F. Ringeval, D. Lalanne, M. Torres Torres, S. Scherer, G. Stratou, R. Cowie, and M. Pantic, “Avec 2016: Depression, mood, and emotion recognition workshop and challenge”, Proceedings of the 6th International Workshop on Audio/Visual Emotion Challenge. ACM, 2016.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)