
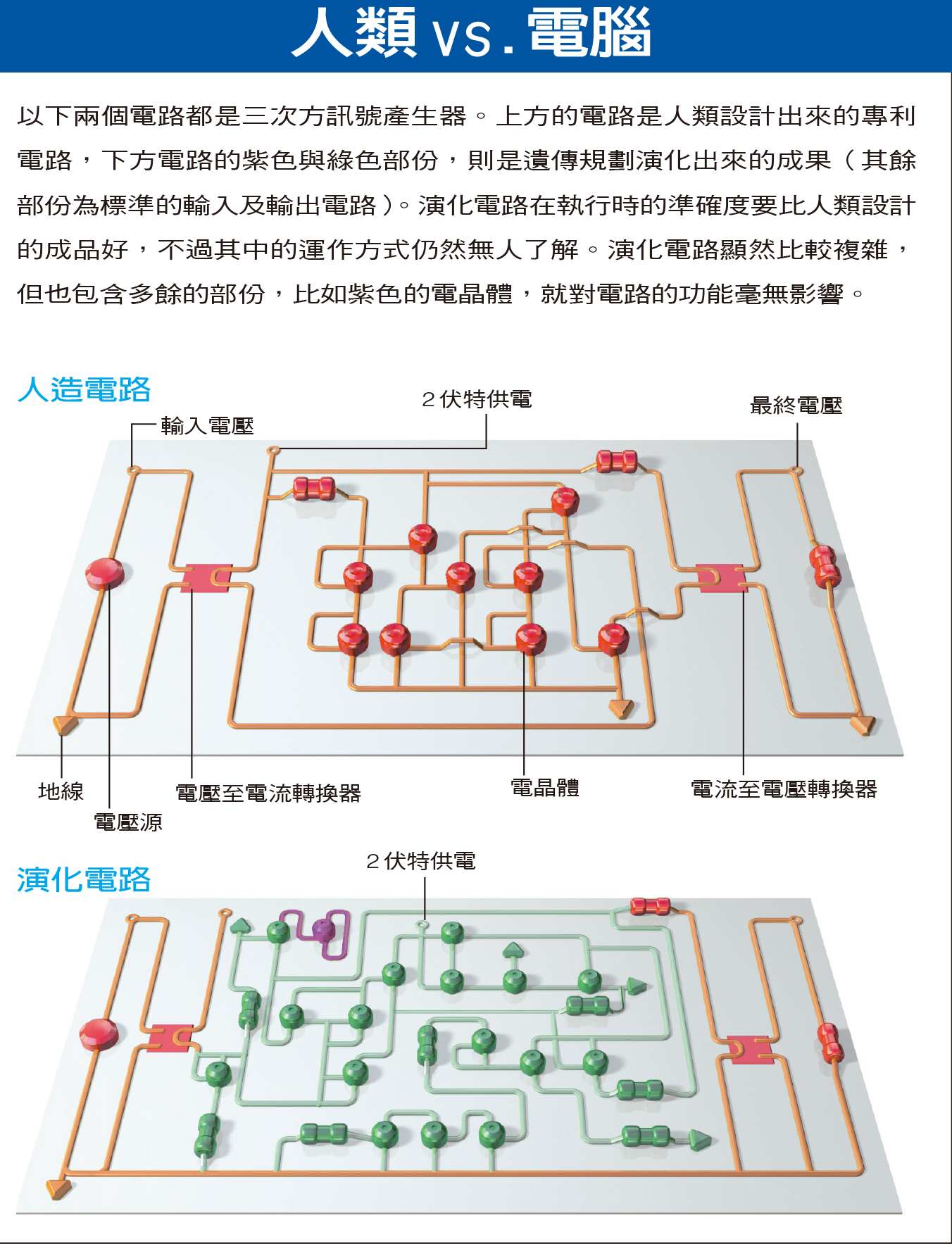
演化,AI的第三條路!(2/2)

撰文╱John R. Koza、Martin A. Keane & Matthew J. Streeter|譯者╱鍾樹人|審訂╱李國偉
轉載自《科學人》2003年3月第13期
可演化的硬體
在演化過程裡,我們必須對每個世代中成千上萬的後代,進行有效的適應度評估。以電路來說,我們一般會用標準的電路模擬軟體,來預測族群中每個電路的行為。不過,在可演化硬體這個新興的重要科技領域中,我們可以立刻組裝微晶片,實質測試遺傳規劃執行過程中每個電路的效用。
這些晶片稱為「快速可重組的實地規劃閘陣列」,由數千個一模一樣的小單元所構成,每個單元都能依照各自規劃的方式,執行多種不同的邏輯功能。晶片「底層」的記憶位元組可依特定需求製造每個單元,使各單元能夠執行特定的邏輯功能。其他的組態位元(configuration bit)則可規劃晶片上相互連結的路線,以多種不同的方式連結不同的單元,或把單元連結到晶片的輸入與輸出針腳。只要讓組態位元發生變化,晶片的「性格」(也就是它的邏輯功能與相互連結)也會動態地跟著在奈秒之間發生改變。
目前約有十餘家公司出售這種快速可重組晶片,但是主要用於數位電路上;商用的類比晶片在功能上則極端受限。我們已用可重組數位晶片製造出一種排序網路,相較於原始的專利版本,我們所用到的步驟更少。
演化的執行時間
自然界的演化擁有數十億年的「執行時間」供它創造奇蹟,人為的遺傳規劃如果也耗費這麼長的時間,用處就不大了。一次遺傳規劃,通常包含數十或數百個世代的演化過程,可製造出含有數萬至數十萬個體的族群。上面表格所列足以與人較量的作品,只要在筆記型電腦上執行一週的遺傳規劃,有一半是可以製造出來的。不過,在2000年後取得專利的六種發明,全都需要更大的運算能力。
自然界的生物如果是分佈在半隔離的次族群內,會比較容易演化。遺傳規劃若是在連結鬆散的電腦網路內執行,狀況似乎也是如此。每一部電腦都可針對各自次族群內的個體,執行耗時的適應度評估程序。接著,當每個世代演化到最後時,有一小部份(根據適應度篩選出來的)個體會移入網路中鄰近的電腦,所以每個半隔離的次族群,也就可以享有別處演化改進所帶來的好處了。
我們已經建立了一個「貝奧武甫式」(Beowulf-style)電腦叢集,其中包含1000台已經有點過時的350MHz奔騰電腦。在我們碰到的最耗時的問題上,每評估一個個體的適應度,大約得花費一分鐘的電腦時間。如果一個族群有100個世代,共10萬個體,那麼在我們的電腦叢集內執行完一次遺傳規劃,就大約要花費七天的時間。
這1000台電腦每秒總共可執行大約3500億次計算。乍聽之下,這個電腦時間數值好像很快,不過,其實比起人腦內幾兆個細胞執行運算的速度,它就顯得遜色了。(目前認為,每個人腦細胞具有大約10000個連結,而且每秒可執行1000次運算。)
我們預計不超過十年,50GHz(也就是每秒執行500億次計算)的電腦將變得普及。屆時,每個以合理價格取得桌上型工作站的人,將擁有執行遺傳規劃的運算力,並可演化出值得獲取專利的發明。可想而知,遺傳規劃未來將成為一種常見的發明機器。

半個世紀前的預言
電腦科學先驅涂林(Alan M. Turing)曾預言,50年之內機器將擁有與人相當的智力。就在他做出這項預言半個世紀之後的今天,遺傳規劃能造出人類發明物已非難事。在這50年當中,研究人員流行採取兩種方法,力圖實現涂林的預言。這兩種方法分別是使用邏輯推演,以及建立囊括人類集體知識與專門技術的資料庫(也就是所謂的「專家系統」)。兩種方法大致反映了涂林在1950年提出的綱領。第一種方法是撰寫程式(毫不意外的,靈感來自涂林在1930年代對計算的邏輯基礎所做的研究),而程式的設計目的,則是以邏輯方式分析狀況及問題,然後提出相對的因應之道。第二種方法是涂林所稱的「文化搜索」,其中應用了從專家處蒐集而來的知識,以及專門技術。
人工智慧與機器學習的目標,是讓電腦可根據「該完成什麼」這樣的高階敘述來解決問題。遺傳規劃在解決每一個新問題時,都是在人類極少參與的狀況下,自行發展出與人類相當的機器智慧,而且既未採用邏輯推演,也沒有採用人類知識資料庫。
涂林測試
涂林也曾提出一個測試機器智慧的著名方法。在某個受到廣泛使用的涂林測試法版本中,一位裁判會收到「隔牆」傳過來的訊息,並試著判斷這個訊息是來自機器還是人。我們並未主張,遺傳規劃已經模擬出涂林測試中所要求的人類認知能力。不過,遺傳規劃的確已經通過一項有關創意及創造力的測試,這項測試只有相當少數的人曾經通過。美國專利局實施這項測試也已有200年以上的歷史。
專利局收到發明物的書面描述後,會判斷這些發明對於相關領域中擁有一般技巧的人而言,是否並非顯而易見。自動方法只要複製出先前已取得專利的人類發明,這個方法就已經通過專利局的智力測驗。因為原來由人類設計的東西,已經符合了專利局對專利取得的標準,所以電腦產生的複製品,當然也符合專利局的標準。
這項智力測驗所測試的,並不是閒嗑牙,也不是在玩遊戲。當一個機構或個人願意花時間與金錢發明某種東西,並進入冗長且昂貴的專利申請過程時,他們已經判斷,這項發明應該具有科學及實用的重要性。不僅如此,專利局也要求提出申請的發明物應該真正有用。能獲得專利的發明物,正代表了有創意的人完成了重要的工作。
有些人可能覺得訝異,竟然可透過一種非定向性的方法,並且無需用到邏輯或知識,得出與人類智力等量齊觀的機器智慧。不過涂林可不會覺得奇怪,他在1950年的論文中,也曾指出這第三種求得機器智慧的方法:「可藉由遺傳或演化搜索,以存活力的高低作做為判斷標準,以找出基因的組合。」
涂林並未指出,如何以「遺傳或演化搜索」發展出機器智慧,不過他明確指出:
我們不能期望一開始就得到優良的小孩機器(child machine)。我們必須試著先教導這樣一個機器,並且看看機器的學習成效如何;然後再試試另一個機器,並看看成果是更好或更壞。這種過程與演化之間存有明顯的關聯,對應方式如下:
小孩機器的結構=遺傳物質
小孩機器的改變=突變
天擇=實驗者的判斷
從多方面來看,遺傳規劃已經實踐了涂林所承諾的第三種獲取機器智慧的途徑。(完)
(本文由教育部補助「AI報報─AI科普推廣計畫」取得網路轉載授權)