
照片反光了?讓AI來幫你處理

編譯/賴佳昀
AI幫忙處理圖像
電腦視覺在現今的社會中有非常廣泛的應用,例如停車場的車牌辨識、圖片文字翻譯,甚至是自動駕駛。電腦必須透過相機或錄影機等設備才能「看」見影像,然後做出相應的反應。先不說因為設備設定而導致的圖像失真,其他像是柵欄遮擋、玻璃反光等障礙,都是電腦視覺需要克服的困難。人工手動修圖不僅細節繁瑣、耗時耗工,還不能即時將重建後的影像回饋給需要用到的程式或裝置。此時利用電腦自動修圖就成為最理想的選擇了!
目前大部分的演算法,都是針對單幀圖片設計,方法不外乎「鬼影線索」(ghosting cues)與「特徵學習」兩種。前者是透過玻璃反射出的「鬼影」,利用景深不同但內容一致的特性,以演算法移除反射;而後者則必須先對原始(無遮擋)的拍攝場景有充分了解才能進行。今天若是想將一個圖像的前景(遮擋物)和後景(想觀察的場景)清楚地分離開來,兩種方法都不可靠。
最近由台大研究團隊提出,利用移動相機捕捉到的序列圖像(像是連續拍攝)提供更多訊息,有效地分離前/後景。舉例來說,圖像前景和後景的景深不同,因此在序列圖像中移動速度不同,利用這個特性,就可以寫出演算法來分離兩者,將遮擋物移除。
又好又便宜
利用前後景運動速度的不同,已經可以得出一些相當不錯的成果,但是那些方法不僅在計算能力上的要求很高(俗稱計算代價昂貴),還需要很嚴謹的假設與模型配合,例如亮度上要保持一致、需要可以精確估計前後景運動的能力等;即使後來以三維卷積神經網路(CNN)為核心,可以不依賴任何預設模型來處理圖像,但得出的結果卻不如先前優秀。
有鑑於此,台大團隊先使用了細密運動估計法(dense motion estimation)在前後景間切換,找出各自的運動向量,從粗略到精細重新建構不同圖層的內容。與此同時,圖層並不由人工設定,而是透過機器學習的方式來告訴演算法何為前景,何為後景。如此一來,演算法便可由多樣化的圖像中學習,無須依賴經典假設。因此若是碰到一些與假設不是那麼契合的數據,也能容錯的空間,進而在應用層面上更有彈性。
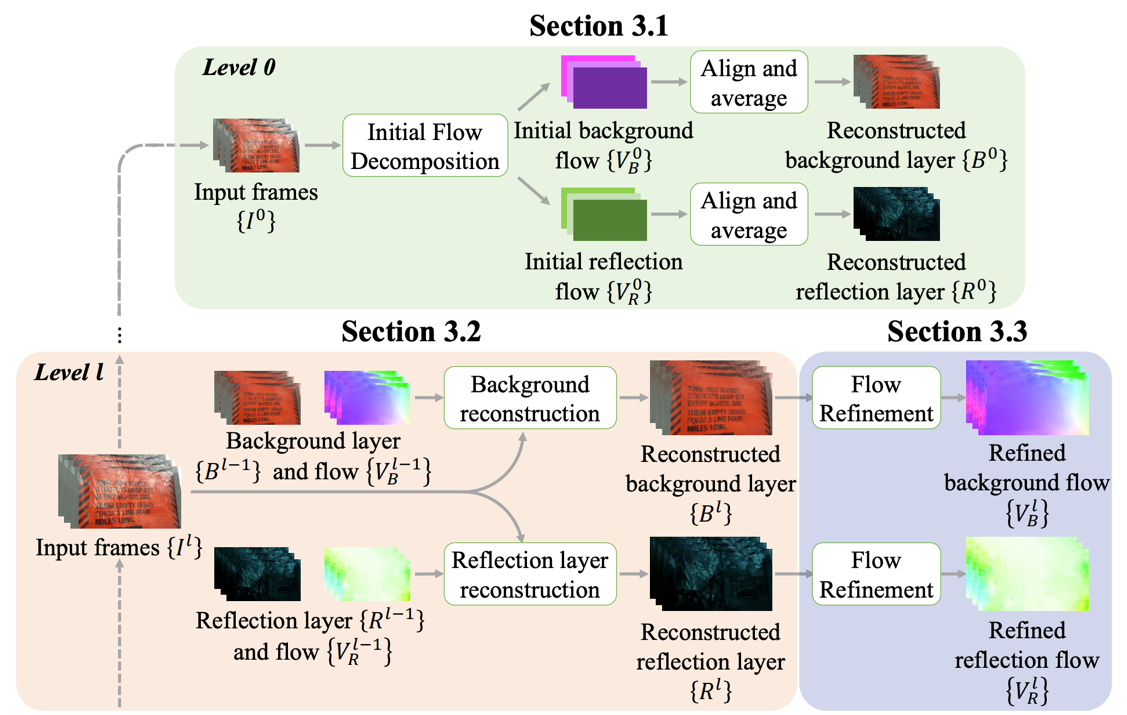
(圖片來源:Liu, Y. et al., 2020.)
詳細地來說,演算法首先粗略地估出前景(圖一上方綠色方形)、後景(圖一上方紫色方形)單一均勻的光流場(flow field),也就是前後景的運動情形。而後用光流場重建出前後景,再來透過已事先訓練好的CNN微調前後景的光流場(圖一下方淺綠方形和紫綠方形),直到最佳成果。

圖二、展示了一些經過處理的遮擋圖片例子,經過分離之後,背景即很清晰地凸顯出來,不再受反光或是遮擋影響。(圖片來源:Liu, Y. et al., 2020.)
值得一提的是,CNN事先訓練時所使用的數據為人工合成,而非實際拍攝的圖像。在應用到真實數據時,若是要處理各種不同的遮擋效果,也只需對演算法做一些小更動即可。
參考資料
- Y.-L. Liu, W.-S. Lai, M.-H. Yang, Y.-Y. Chuang, and J.-B. Huang, “Learning to See Through Obstructions,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 14215-14224.
- Y. Shih, D. Krishnan, F. Durand, and W. T. Freeman, “Reflection removal using ghosting cues,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2015, pp. 3193-3201.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)