
會思考的電腦(1/2)

撰文╱Yaser S. Abu-Mostafa|譯者╱鍾樹人
轉載自《科學人》2012年11月第129期
重點提要
- 機器學習是資訊科學的一個分支,可從大量資料內取得訊息,並對未來做出預測。
- 機器學習可用來辨識經濟趨勢、建立個人化的推薦系統,以及打造「會思考」的電腦。
- 雖然機器學習越來越受歡迎,但必須先具備大量資料,才能處理問題。
- 我們必須小心,避免機器推論出根本不存在的模式。
兩年前,一家女裝公司找上我,要我幫忙提升他們的時尚推薦能力。我對於這個領域所知甚微,任何神智正常的人都不會向我尋求意見——畢竟我是男性,還是個資訊科學家。但他們尋求的不是我個人的意見,而是我在機器學習方面的建議,我照辦了。僅僅根據銷售數字與顧客調查,我就可以把自己從未見過的服飾推薦給不曾謀面的女性。我的推薦勝過了專業造型師,再提醒你一次,我對女性時尚依舊所知甚微。
機器學習可讓電腦從經驗中學習,而且無所不在。它改善了網路搜尋的相關性、讓血液檢測更精確,並且提高了約會服務幫你找到伴侶的可能性。機器學習程式會讀入一組現存的資料,從中歸納出模式,然後運用這些模式預測未來。過去10年來的進步已改變了這個領域,我們企圖完成的工作,都是運用機器學習技術把電腦調校得比人類更「聰明」。IBM的電腦「華生」就是實例,它打敗了益智節目「危險邊緣」的人類冠軍。
然而,機器學習最重要的挑戰與參加益智節目的電腦無關。幾年前,線上影片出租公司Netflix希望協助顧客尋找喜愛的影片,尤其是那些飽受冷落的舊片。這家公司已建立了影片推薦系統,但自知遠遠不足,於是舉辦一場競賽來提升現有系統的性能。規則很簡單,第一個打敗既有系統、且讓性能提高10%的參賽者,就能獲得100萬美元的獎金,吸引了全球數萬人報名參加比賽。
對機器學習的研究者來說,這是一場夢寐以求的競賽(不僅是獎金,雖然那實在很誘人),因為最關鍵的就是資料:Netflix提供了多達一億筆的真實資料,隨時都能下載。
展開訓練
Netflix這場競賽持續了三年,許多團隊解決問題的方式是解析各個影片,將其分成一長串不同的屬性。例如你可以根據不同的特質幫影片打分數,像是趣味度、複雜度,或是演員魅力。對某位觀眾進行推薦時,則回頭分析他租過的影片,讀取他對不同屬性的評價,像是有多麼喜歡喜劇、偏好簡單或複雜的情節,以及有多麼喜歡看那些迷人的電影明星(見下圖)。
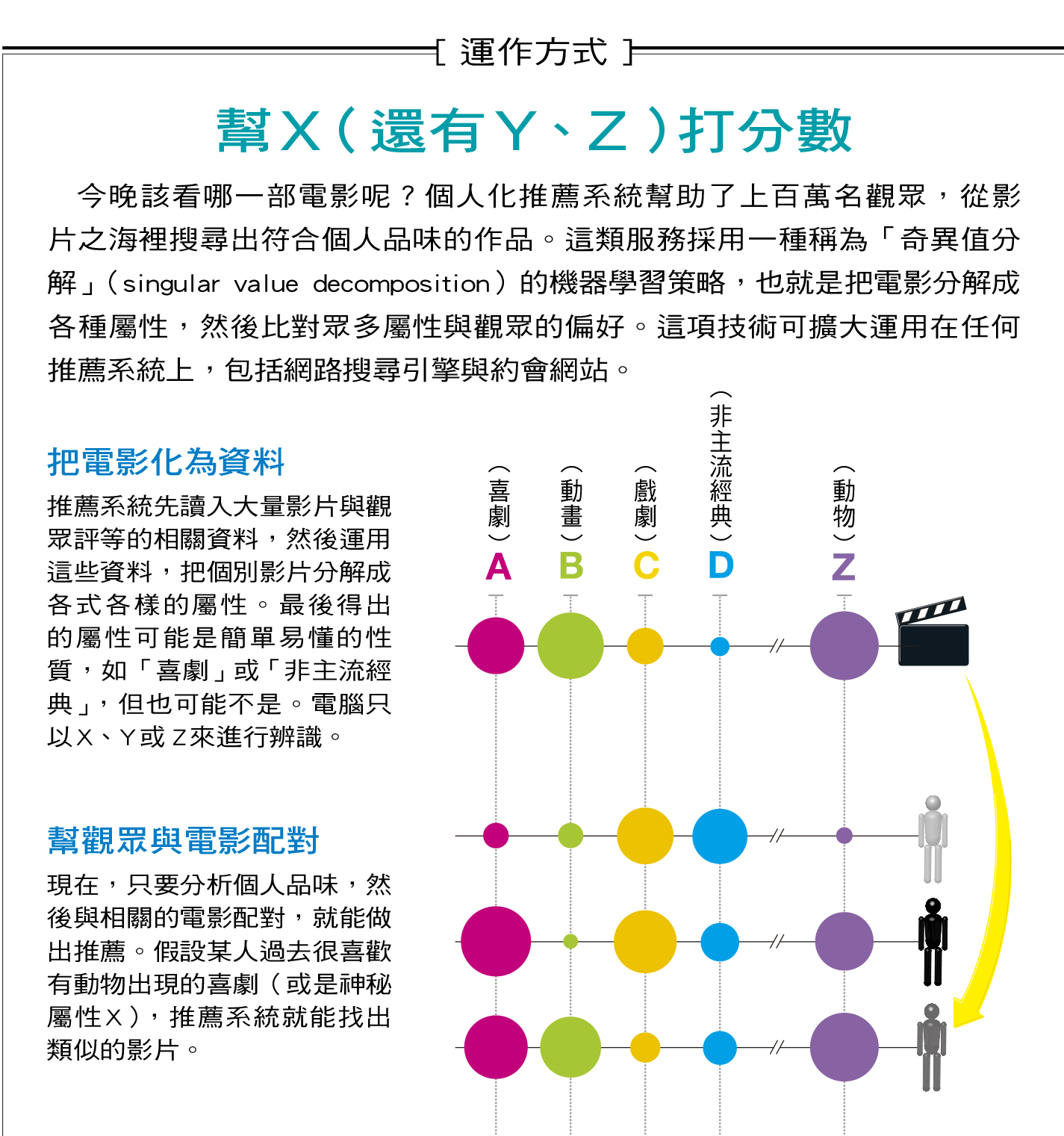
接下來只要比對觀眾的偏好與電影的屬性,就能做出預測。假設他熱愛喜劇和複雜的情節,也許會喜歡糾結的鬧劇,像是「熱情如火」或「笨賊一籮筐」。我們一般想到的都是容易辨識的屬性,像是「喜劇」或「複雜的情節」,但電腦卻不必知道這些。事實上,整個過程完全自動,研究人員根本不必分析影片內容。機器學習程式會從不知名的隨機屬性開始,等程式取得觀眾過去對影片的評等後,再慢慢微調,直到屬性可完全反映出觀眾對影片的評價。
舉例來說,如果喜歡影片A的人也喜歡影片B、C與D,程式就會產生一個與A、B、C和D共同相關的新屬性。這個過程發生在所謂的訓練階段,電腦會搜尋上百萬名觀眾的評等,目標是根據實際評等產生一組客觀的屬性。
電腦學習程式所產生的屬性有可能很難詮釋,並不像「喜劇內容」這樣直截了當,這些屬性可能相當細微,甚至不可理解,因為程式的目標是找到最好的方法來預測觀眾怎麼評價某部電影,並不需要向我們解釋是怎麼做的。
這不是我們熟悉的運作方式。在我剛開始工作時,曾經幫某銀行建立信用核證系統,系統完成後,銀行希望我解釋每個屬性代表的意義。這個要求和系統的表現無關,因為系統運作沒有問題。銀行要求的是合理性,銀行不能不明不白否決某人的信用,只向對方解釋:因為X<0.5。
不同的機器學習系統會各自發展出獨一無二的屬性。在Netflix競賽的最後幾星期,各個團隊開始利用所謂的「聚合技術」把不同程式整合在一起。長達三年的競賽進入最後一小時,有兩組人馬還在為首獎拚搏。計分板顯示「和合隊」(Ensemble)略勝於「貝爾可實用混沌隊」(Bellkor’s Pragmatic Chaos),和合隊裡有一名隊員是我在加州理工學院的博士畢業生。最後統計出來的得分,兩隊不分軒輊,性能都比原來的系統高出10.06%。根據比賽規則,若是平手,則由優先提交結果的隊伍獲勝。經過三年競賽,到了最後一小時的衝刺,貝爾可隊比和合隊早20分鐘提交,結果就是百萬獎金的差別。(待續)
(本文由教育部補助「AI報報─AI科普推廣計畫」取得網路轉載授權)