
電影推薦大有學問

撰文/陳育婷
推薦系統
1990年代中期,由於「評分結構」的研究逐漸受到重視,「推薦系統」於是演變成一門獨立的學問;在多數情況下,其可以被概括為「估計用戶對未知商品評分的問題」。一旦我們可以估計用戶對未知商品的評分,就可以找出分數最高的商品推薦給用戶。
假設:
C:所有用戶形成的集合;
S:所有潛在物品形成的集合;
u:為評估商品(s)對用戶(c)的效用函數(utility function),
針對某用戶c,我們希望能推薦一項在S集合中對用戶c效用最大的商品s。上述想法可簡單表示如下:
針對一用戶c,我們可以用一系列例如年齡、性別、所得的特徵來表示;同樣地,我們也可以用一系列的商品特徵來定義一商品s,以電影推薦系統為例,電影名稱、類型、導演與演員等,都可被用以定義s。
效用函數通常只在一部分的集合中有完整的對應值。例如在電影推薦系統中,一般收視戶可能只為一小部分的電影評過分,我們可以簡單的用戶-評分表格表示:
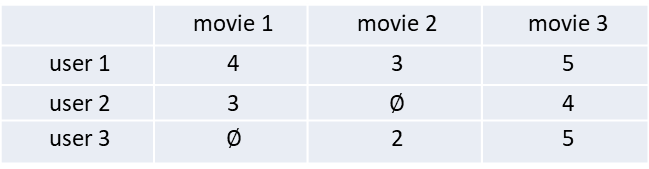
推薦系統的目標,就是以各種方法推估表格內空集合(Ø)的值。如此,我們才能從所有商品中選出最高分的前幾種商品推薦給用戶。
需要注意的是:所推薦的商品雖應與用戶喜好相似,卻也需與用戶過往的瀏覽紀錄有一定的區別,帶有一些新意,而非舊調重彈,例如針對同一事件但不同敘述的報導。依據估計評分的方式,可以將推薦系統大致分為「基於內容」、「偕同過濾」或「混和過濾」等三類(以下皆以電影推薦系統為例)。
基於內容的推薦(Content-Based Recommendations)
此方法只運用用戶c評分過的電影資訊,去推測他(她)對未評分過的電影s的評分。核心概念是從該用戶已評分的電影中,找出n項與s最相似的電影,並推薦這些電影給該用戶。此方法可以透過兩種方式實踐:啟發式學習以及模型學習。
前者主要是運用一系列的關鍵字去代表用戶及電影,並計算用戶及不同電影之間的相似程度,相似程度的衡量可以用相關係數等指標量化;後者則是將模型套用到現有資料,學習並進而預測電影評分,許多模型都可以運用在推薦系統,諸如決策樹、貝氏分類器、類神經網路等。
協同過濾推薦(Collaborative Recommendations)
此方法利用與用戶c相似的用戶群的資料,來推估c對電影s的評分。至於如何找到與用戶c有相似品味的用戶群,則可分為兩種方法─記憶式學習及模型學習。前者藉由兩用戶共同評分過的電影,來計算兩者間的相似度(可以用相關係數或餘弦相似性表示),並以此將中每位用戶對電影s的評分做加權平均,得到評分估計。後者則是直接將模型套用到所有用戶對該電影s的評分資料,學習並預測電影評分。
混和推薦(Hybrid Recommendations)
上述兩種方法可以下列四種方式結合,截長補短,使得即使在評分資料稀少,如新用戶或新電影時,仍可適用:
- 分別運用「基於內容」與「協同過濾」兩方法預測評分,再結合兩者評分得到最終評分。
- 將「基於內容」的用戶特徵加入「協同過濾」法內,以預測評分。兩用戶間用來計算相似度的特徵不再僅限於共同評分過的電影,也可以包含用戶的基本資料。
- 將「協同過濾」的特徵加入「基於內容」內預測評分。
- 發展一套結合兩方法之特徵的預測模型。
更省時的推薦演算法
上述方法奠定了推薦演算法的基礎,但卻有一個共同問題:運算時間。無論是基於內容、協同過濾或混合推薦法,都必須在瀏覽過所有電影及用戶資料後,方可開始計算。隨著資料量增長,計算時間也勢必大幅拉長,如何降低運算時間因而成為重要議題。今年(2018)7月12日機器學習研討會中,由哈佛大學電腦科學家Yaron Singer 與Eric Balkanski提出的演算法,能在短時間內找出最佳解,更聰明也更快速地解決問題。
相較於傳統電影推薦系統,需在瀏覽所有電影資料庫的電影後,方能列出推薦清單;新的演算法一開始只選取一定數量的電影,在這些電影之中找出最符合推薦標準的幾部電影,並捨棄未選上的電影,而後再由縮小後的資料庫中隨機選取一定數量的電影,保留最符合標準的電影,並捨棄其他,持續重複上述步驟。如此做法,創建推薦清單的速度是傳統演算法的10倍以上。
而其應用範圍,也不僅限於電影推薦。在另一個試驗中,這種新的演算法能迅速找出紐約計程車的最佳路徑,速度是傳統方法的六倍以上。除此之外,也可以加速資料處理的速度,並拓廣運用到如社群媒體或基因資料的分析。
參考資料
- G. Adomavicius, A. Tuzhilin. “Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions.” IEEE Transactions on Knowledge and Data Engineering 17(6), pp.734–749, 2005.
- C. Basu, H. Hirsh, and W. Cohen. “Recommendation as classification: Using social and content-based information in recommendation.” AAAI Proceeding, pp. 714-720, 1998.
- M. Temming, “Solving problems by computer just got a lot faster“, Science News, July 16, 2018.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)