
AI點唱機

編譯/江彥成、黃思齊
音樂生成的難題
AI作曲並不稀奇,例如Open AI在2019年發佈的MuseNet就已經可以用10種不同樂器生成古典、爵士、甚至混成Bon Jovi的曲風,然而這類模型無論是輸入與產出都是所謂的「符號音樂」(symbolic music)──記錄了音高、時間點、(敲擊按鍵的)力度(velocity)與演奏的樂器,但不能處理人聲、音色等細微的表達差異;並且隨著樂曲時間拉長,難以顧及完整的音樂架構,例如前奏到副歌的一致性。
為了克服上述的限制,Jukebox的訓練資料與生成的樂曲都是原聲音檔。研究人員先由網路上蒐羅了120萬首歌曲(其中60萬是英語)。不單單是音訊,還包含了歌詞、作者、演唱者、曲風、年代等資訊,並參考這些歌曲在播放清單上的關鍵字或是與歌曲一併出現的情緒等。
取樣與生成
另一方面,正如前面所說,比起生成資料量小、音訊簡單的MuseNet,Jukebox要生成一首一般CD音質的歌曲(4分鐘,16位元,44kHz ),需要超過一千萬時步(timestep)來處理。相較之下,文本生成器GPT-2僅需1,000時步;電玩Dot2中,打敗人類玩家的OpenAI Five僅需數萬時步。在這樣龐大的資料流中,模型需要能夠處理跨度很大的相關性,才能學習到歌曲的高階語意(high-level semantics),如主旋律、歌曲力度、強弱張力、曲式編排等。
針對這一點,OpenAI團隊採用分層編碼,將44kHz的原始音訊(訓練資料)分別壓縮為不同壓縮幅度的三個音軌(8x、32x及128x)。最高階音軌(壓縮率最大)掌握了歌曲的大範圍結構,負責捕捉樂曲的高級語意,但同時利用較低階的音軌保留了那些被忽略的細節。
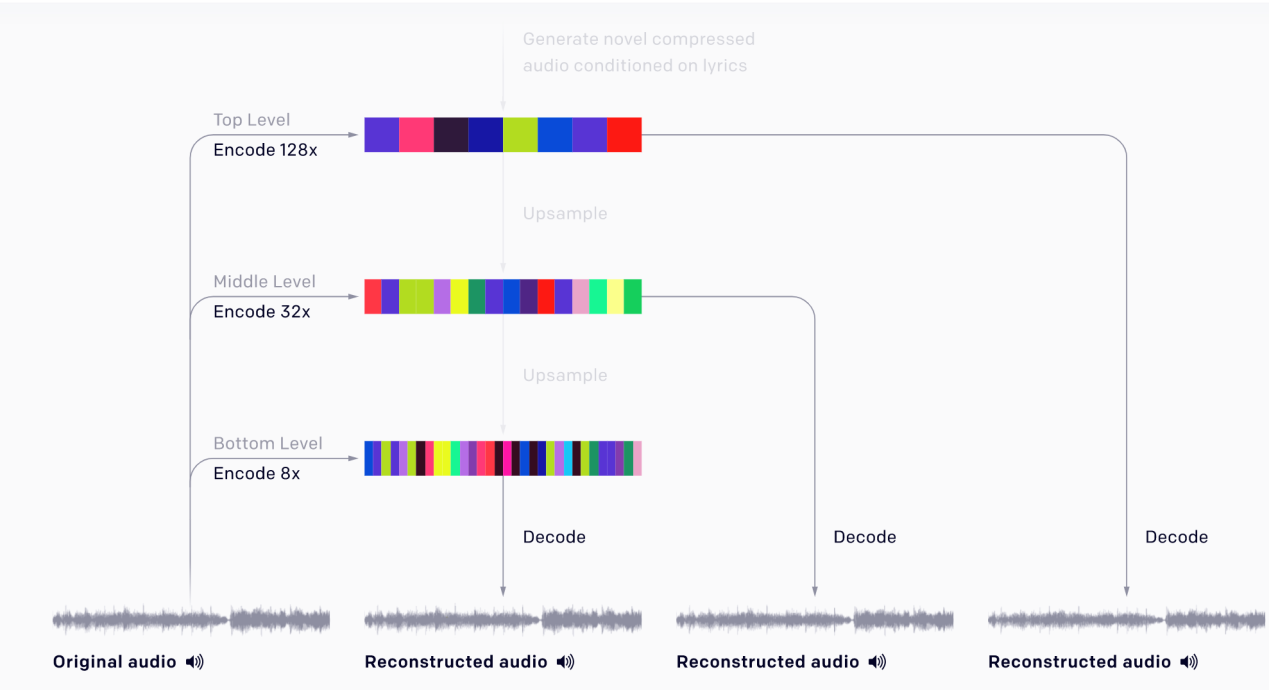
(圖片來源:OpenAI, 2020.)
當在生成新樂曲時,負責最高階音軌的轉化器由於能夠預測樂曲的曲風、演唱者等資訊,因此歌曲的宏觀特徵會先被定下來,而後由較低音軌的轉化器逐一補強微觀細節。
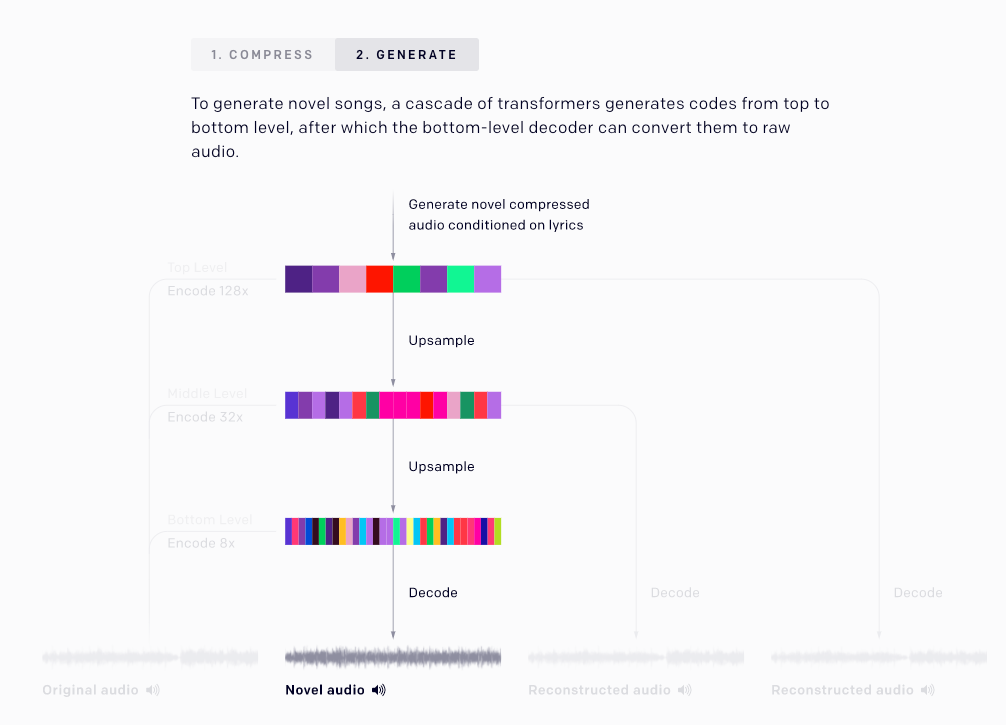
(圖片來源:OpenAI, 2020.)
也因為如此,JukeBox的研發途中還有個有趣的小插曲。研究人員為了使高階音頻的轉化器能夠預測生成樂曲的曲風,當初採用無監督學習的方式加以訓練。模型很快就能自動將流派相近的歌手歸為一類,將120萬首歌分為11類(分別是BLUES、Country、Classical、JAZZ、HIP HOP、R&B、POP、REGAGE、ROCK、Soundtrack與SOUL)。將其視覺化畫成一張地圖,研究團隊很驚訝地發現:Jennifer Lopez比起同屬pop曲風的Maroon 5,音樂特徵更接近鄉村歌手Dolly Parton!
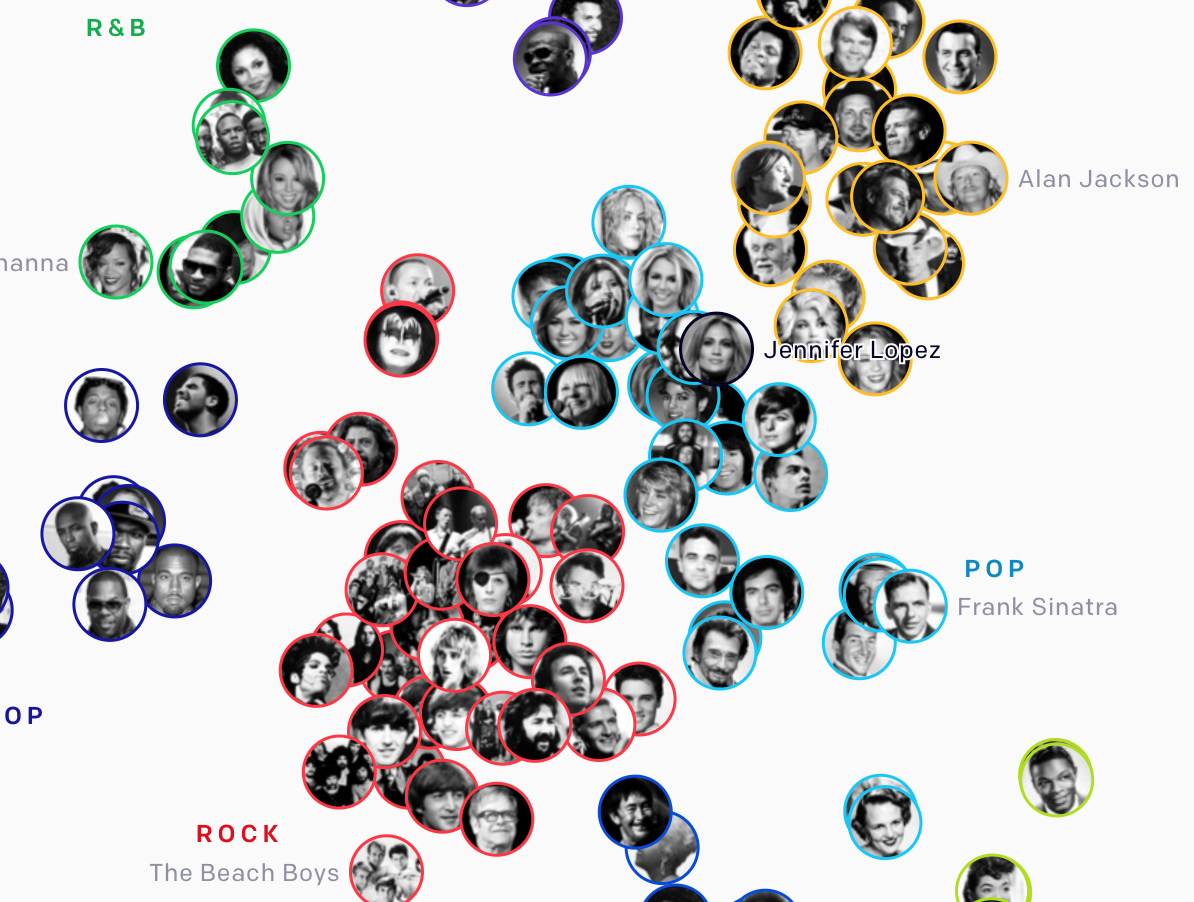
(圖片來源:OpenAI, 2020.)
一場著作權災難?
儘管Jukebox生成的歌曲已經可以聽出一定的連貫性、產生和諧的和弦,甚至表現出不錯的間奏,但大部分的作品仍然達不到一首「完整」作品的水準。Jukebox還無法重現出副歌反覆段落的形式,也無法形成有邏輯的首尾結構。生成的樂曲聽起來像是喝醉酒後的即興創作,音樂結構鬆散且原創力不足,並且仍存在許多流行音樂的影子,與人類作曲家相比還遠遠不及。
其次,Jukebox的訓練十分複雜,生成一分鐘的歌曲大約需要9個小時,難以商轉成為手機APP這類應用工具。
最後,由於Jukebox的學習源於網路上的歌曲,歌聲也是以現有的歌手素材重新合成的,這使得Jukebox的作品每一步都踩在著作權的紅線上。除了成品容易與原曲有重複的小節,也難以取得聲音主人的授權(Jay-Z就對Youtube提出了下架合成音樂的版權要求);若AI作曲想要發展商業用途,最終可能會演變成一場著作權災難。
即使如此,相較於之前的音樂生成模型,Jukebox還是創造了亮眼的技術成果,可以自動生成不限曲風、高度擬真的人類歌聲,讓這項技術有潛力成為未來人類音樂家的重要工具。
編譯來源
“Jukebox“, OpenAI, 2020.
參考資料
- B. Stephen, “OpenAI introduces Jukebox, a new AI model that generates genre-specific music“, The Verge, 2020.
- “MuseNet“, OpenAI, 2019.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)