
AI智慧教室─帶你一窺聽眾的心聲
編譯|許晉華
試想一下在2024年的教室中,講台上有位學生正在練習報告,聽起來是否和現在我們練習的方式沒有不同呢?但仔細一看發現,學生手上戴著觸覺虛擬手套 (圖3) ,指導他如何調整肢體語言,旁邊還有螢幕正不斷顯示各種建議,提醒聲音再大聲一點。沒錯,他正在體驗的就是智慧教室。智慧教室透過蒐集、量化講者與聽眾的資料,藉由深度學習和穿戴裝置來即時反饋,彷彿講者能聽見台下聽眾的內心聲音,不斷隨著眾人的反應作應對,提升演講品質。
回到2018的今天,智慧教室不再是科幻電影裡才會出現的情節了,已經有研究團隊成功實作出完善的系統,未來不僅能在教育中實踐,更可以應用於其他需要溝通、回饋的領域中,實現智慧教室的偉大願景。
●智慧教室的整體系統架構
2017年Yelin Kim等人設計了一套智慧教室系統架構,並提出在實作前需要滿足的兩個假設:
- 講者和聽眾的情緒、肢體表現等行為皆可被量化。
- 在訓練模式中,透過深度學習找出兩者之間的關聯,並用學習到的資訊,能即時回饋聽眾反應給講者。而演說模式中,則是模擬聽眾反應,利用訓練模式中所得到的資訊,給予演說技巧的意見,有效地提升演講品質。
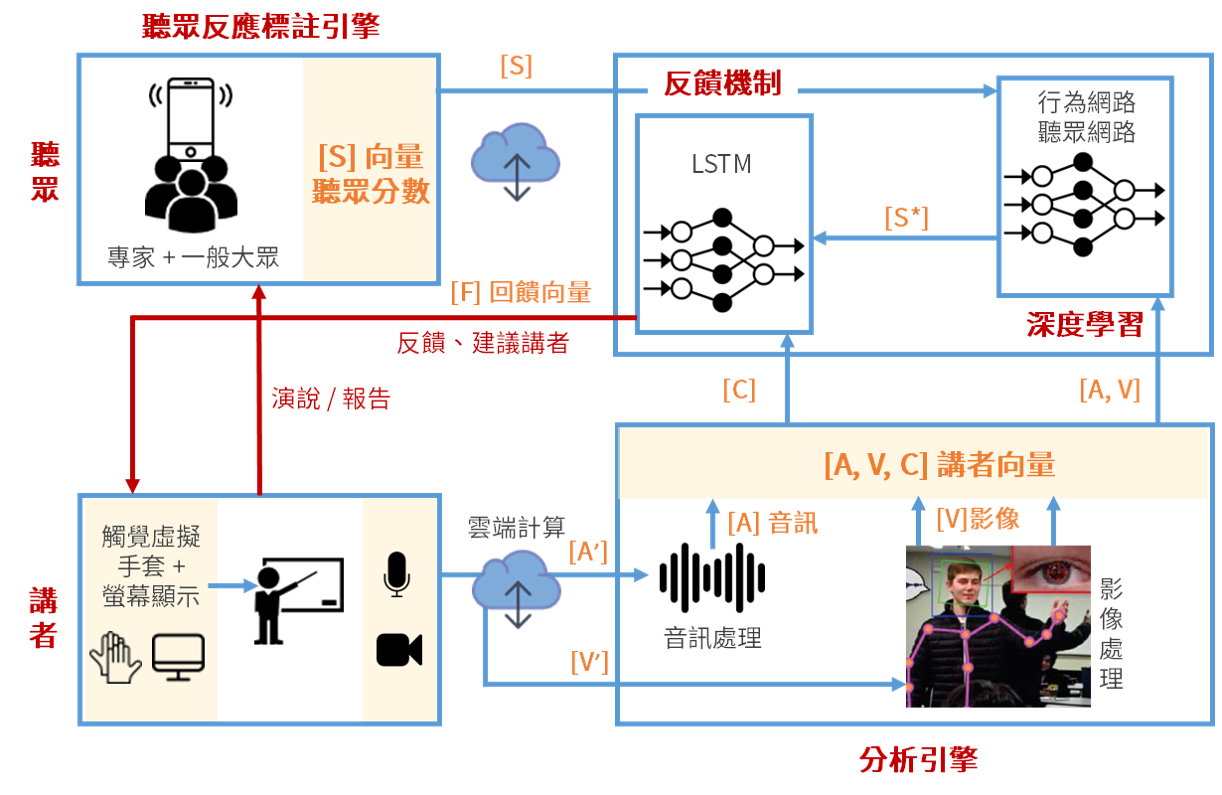
基於這些假設,智慧系統可分為四個部分:分析引擎、聽眾反應標註引擎、深度學習和反饋機制。首先,在演講或報告的過程中,分析引擎會將講者的音訊、影像及其認知特徵經處理後分別轉換為三個向量,用以量化他的情緒及肢體表現。同時,聽眾會依各個衡量標準來評估講者,綜合所得分數即為代表聽眾的特徵向量。
接著深度神經網路會針對量化後的音訊、影像及聽眾分數學習,找出講者哪些類型的行為會得到較高的分數。最後利用找出的關聯性,系統將會透過觸覺虛擬手套和螢幕即時反饋、給予建議,讓講者能適時地調整音調、手勢和肢體語言,不斷地增進演講技巧。
整套系統又分為訓練和演說模式,訓練模式主要找來真實的聽眾,包含專家及一般大眾,透過問卷調查得到聽眾評估的分數,再輸入到深度神經網路中作學習,進而輸出關聯規則。在演說模式中,改用模擬聽眾的行為來取代問卷調查,讓即便是缺少真實聽眾的狀況下,也能改善演說方式。
●無形的感受如何被量化?
研究團隊在報告過程中會採集講者的聲音、影像檔案和其他認知特徵─如臉部表情、手勢及瞳孔大小等 (圖1中的分析引擎) ,並將其原始資料轉換成訊號,分別為[A] (Action)、[V] (Video) 和 [C] (Cognitive) 三個向量,代表講者的行為量化。
在訓練模式中,針對聽眾則另外設計一份問卷,用來評估報告品質,一系列的問題包含了講者的眼神接觸、音調和肢體語言表達的程度,以1-5來評分。在演講期間讓聽眾在APP上回答問卷,APP後台連接雲端可即時上傳並分析問卷結果,系統會結合蒐集到的回覆,得到最終代表聽眾的分數向量 [S] (Score)。結合算式為 [S] = alpha * [P] (Peer, 一般大眾的加總分數) + beta * [E] (Expert, 專業人士的加總分數),其中alpha, beta為深度學習所得之參數。
●AI搭起了溝通的橋樑
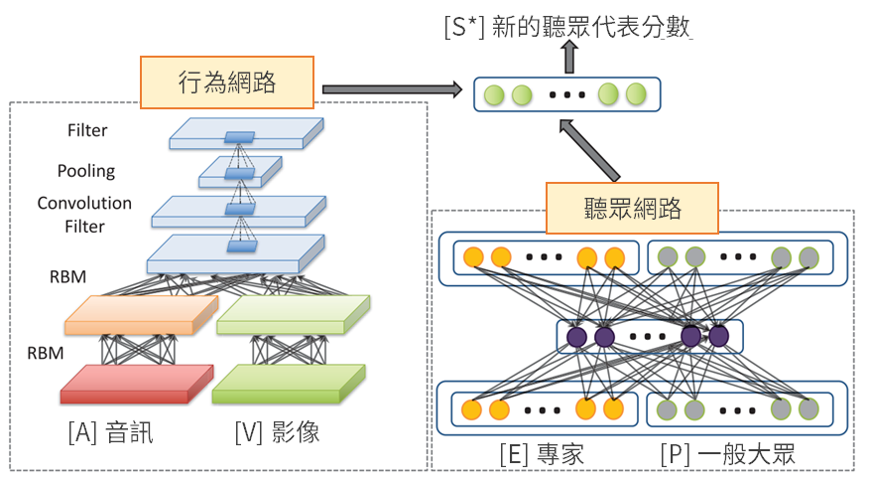
智慧教室系統主要是由兩個深度神經網路組成─行為網路和聽眾網路,分別學習、處理講者和聽眾的資訊,並結合以找出兩者之間的關聯性。其中,行為網路是針對講者的音訊與影像特徵進行學習,聽眾網路則是負責調配出上述式子中的最佳參數,以得到客觀的聽眾分數向量 [S] 。
行為網路主要由深度置信網路 (Deep Belief Network) 及卷積類神經網路 (Convolutional Neural Network) 組成。首先,音訊和影像會分別經過兩層受限玻爾茲曼機 (Restricted Boltzmann Machine) 作轉換,串接各自的輸出結果,再經卷積類神經網路及池化層 (Pooling layer) 學習得到新的特徵。而聽眾網路架構為稀疏自動編碼器 (Sparse Autoencoder),自動編碼器會對原始輸入資訊作轉換,重新學習資料的表達方式。
最後,將經由兩種網路架構轉換輸出的機率結合,並透過活化函數來得到新的聽眾代表分數 [S*] 。不同以往,過去講者只能根據自我經驗和教室氣氛來揣測聽眾的想法,但現在,我們可倚賴人工智慧,在整個學習過程中連結出台上與台下的互動關聯性,將無形的感知變為實質的建議。
●AI:「笑一個吧,會為你的演講更加分的!」
為了做到即時改善,必須每分每秒蒐集認知負荷向量 [C] 和轉換後的聽眾分數 [S*] ,因此選用長短期記憶模型 (Long-Short Term Memory) 實作反饋機制,這是一種特殊的循環神經網路 (Recurrent Neural Network) ,不僅能考量到每個時間點的資訊,還能學習到長期依賴的關係,經訓練後,輸出的回饋向量 [F] 即可用來給講者意見。
回饋向量 [F] (Feedback) 中,包含了大量的資訊─表情符號、震動的幅度和顏色等,搭配觸覺虛擬手套和螢幕顯示,打暗號給講者,例如:出現一個笑臉在螢幕上,表示AI建議講者此時應該要笑一下,或是手套上的震動,表示手勢應更加強烈,吸引注意並提高聽眾分數。諸如此類的明確暗示,可以讓講者快速理解,做出對應的行為,增進與台下聽眾的互動,提高整體報告品質。

●邁向智慧教室的偉大願景
研究團隊打破許多限制,不但實作出即時反饋系統,更結合人工智慧於教育領域中,實現了智慧教室的夢想藍圖,這套系統也有機會應用在其他領域,例如:促進醫病關係等需要大量溝通的場合。相信在不久的未來,AI將有能力來指導人類如何呈現一個完美的演講或報告,也許以後我們不須在上台報告前,緊張又毫無對策地對著鏡子練習,而是讓AI擔任小助手,提醒哪裡需要改進、如何做會更好,讓我們在正式上台時發揮最好的實力,人人都能有出色的演講。
![]()