
擺脫負樣本的限制

編譯/許晉華
傳統的二元分類學習法需要正負兩類樣本的資料,然而在許多情境中,負樣本的採集相對困難。日本理化學研究所(RIKEN Center)藉由加入「可信度」此一特徵,擺脫負樣本限制,令模型在僅有正樣本的情況下也能學習如何有效分類,拓展AI分類器的應用範圍。
二元分類在我們日常生活中隨處可見,細微至垃圾郵件篩選到如何分辨假新聞。當交付AI執行類似任務時,人類須先行將欲分類的資料一一標註,分為正(positive)、負(negative)兩類,讓AI從中找出區隔正負資料的邊界。以臉部表情為例,一開始,我們須依相中人物的表情,將照片區分為笑臉(正向)與哭臉(負向)兩類,等待AI找到能穩定區別兩者的判準後,便可以此為基準來分類新的資料。
這種做法的前提,是訓練集中同時存在正、負兩類樣本,缺一不可;但有時負向資料可遇不可求。就上述例子而言,實際上要找到哭臉相片還頗有難度,因為鮮少有人會在鏡頭前哭喪著臉。而現實生活中,類似的情況還不少見。例如零售商蒐集顧客的基本資料、購買紀錄等,便是想掌握顧客的消費行為,預測哪些消費族群較可能有回購的意願。只是取得常客資料(正樣本)容易,但對於那些未曾來店消費或一去不返的消費者(負樣本),店家幾乎不可能取得他們的資料。
類似的案例也常發生在App開發者身上。他們希望能預測特定消費者是否會繼續使用(正樣本)或刪除(負樣本)App,但同樣地,由於隱私保護政策的限制,一旦使用者刪除App後,使用者(負樣本)資料也會一併由資料庫中刪除。
可信度
為了解決這類窘境,日本理化學研究所(RIKEN Center)革新智慧綜合研究中心的研究人員Takashi Ishida、Niu Gang和Masashi Sugiyama等人研發了一套新的訓練方法,讓AI在缺乏負樣本的情況下仍能學習如何有效分類。關鍵在於加入「可信度」(confidence score)此一特徵。
可信度可以是購買意願、App用戶的參與度等,其數學上的意義是「資料屬於正樣本的機率」。不同於過去的方法,AI會基於正樣本數據和對應的可信度來劃出分類邊界。只是這裡的邊界,不再是區隔正負樣本的邊界,而是高可信度與低可信度正樣本間的邊界。
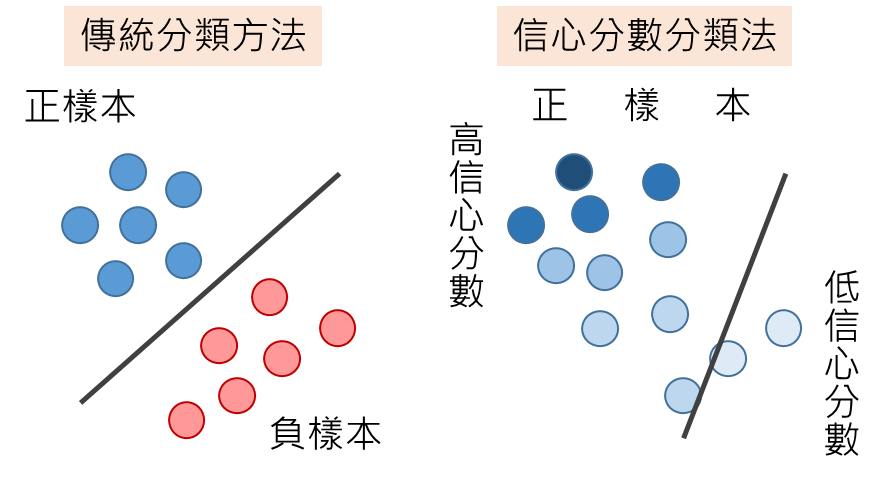
圖一、信心分數(可信度)分類法與傳統方法的比較。(來源:重繪自RIKEN)
效果與傳統方法無分軒輊

圖二、Fashion-MNIST資料庫(來源:Fashion-MNIST)
研究團隊最先使用時尚服飾資料集Fashion-MNIST來測試此法的分類效果,資料庫中網羅了7萬張28 x 28已標記的灰階服飾圖片,他們希望從中找出「T恤」的圖像(正樣本)。研究人員接著針對每張正樣本給予一可信度,如此一來,即使在沒有負樣本(實驗設定為涼鞋)的情況下,AI也能成功從中找出T恤,甚至與傳統分類方法的表現無分軒輊,準確率可高達99.5%。

圖三、CIFAR-10資料庫(來源:CIFAR-10)
除此之外,研究團隊也以另一資料集─CIFAR-10─再次驗證新分類法的分類效果。CIFAR-10蒐羅了6萬張32×32的彩色照片,其中包含如飛機、狗等10種不同物件。實驗定義「飛機」為正樣本,並將其他9類照片視為負樣本。二元分類的結果,發現在飛機─青蛙的任務中表現最好,達到90.8%的準確率。
Ishida表示,傳統的機器學習分類法雖然成績斐然,但遲遲無法突破負樣本的瓶頸,導致應用範圍受限;有了新的可信度分類法後,料可拓展AI分類器的應用範圍,尤其在資料的蒐集與使用受到相關規範或商業限制的情境下,也可游刃有餘。
編譯來源
RIKEN, “Smarter AI: Machine learning without negative data”, RIKEN, 26 Nov 2018.
參考資料
T. Ishida, G. Niu, M. Sugiyama. “Binary Classification from Positive-Confidence Data”, NeurIPS, 2018.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)