
「剪」出最有效率的神經網路

撰文/陳儁翰
樂透假說
典型的剪枝分為三個步驟,分別是訓練、剪枝還有微調。在訓練階段,我們一般會選取一個較大的模型,使得在訓練完成後能夠去除掉冗餘的參數得到較小的模型,且不會造成準確率驟降。下一步,剪枝:針對各參數或參數組的重要性進行排序,並移除比較不重要的參數。最後,微調:彌補剪枝後造成的性能降低而再次訓練。
MIT計算機科學與人工智慧實驗室的研究人員憑藉這樣的觀察提出「樂透假說」(the lottery ticket hypothesis):只要是一個密集的、隨機初始化的前饋神經網路,都包含了數個子網路可以經過獨立的訓練,在相似的訓練時間得到相似準確度。以剪枝的角度來說,就是在經過一般訓練流程的神經網路中,都可以透過剪枝得到一個有相似準確度的子網路,就像在彩券堆中找到那張中了樂透頭彩的彩券。
剪枝的意義與價值
在典型的剪枝流程裡,微調這個步驟是基於現有的參數再次訓練。然而,實驗結果表明,我們可以拿剪枝後的模型直接重新進行訓練,大部分情況下都會得到比微調更好的結果,甚至會超越剪枝前模型的表現。
下表整理了不同微調與訓練方法,在不同資料集中的表現。
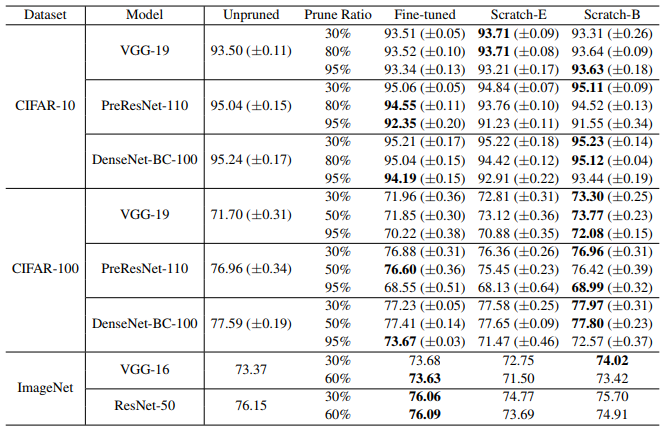
(來源:Liu et al. 2019.)
Unpruned代表未剪枝的模型,Prune ratio代表剪掉的比例,Fine-tuned是微調的模型, Scratch-E是剪枝後重新訓練且疊代次數相同,Scratch-B是剪枝後重新訓練且訓練時間與計算資源相同。可以看到Scratch-B在許多情況都有較高的準確率,甚至很多時候能超越未剪枝模型的準確率。
這樣的結果告訴我們:剪枝的價值不在於把訓練得到的參數留下來,而在於留下剪枝後的網路架構。剪枝可以被視為一種尋找優秀模型架構的方法,並可以視計算資源選擇微調或是重新訓練剪枝後的新模型。
參考資料
- Z. Liu, M. Sun, T. Zhou, G. Huang and T. Darrell, “Rethinking the Value of Network Pruning“, arXiv, 2019.
- J. Frankle and M. Carbin, “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks“, arXiv, 2019.
- H. Li, A. Kadav, I. Durdanovic, H. Samet and H. Graf, “Pruning Filters for Efficient ConvNets“, arXiv, 2019.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)