
面對如同黑盒子的神經網路,AI科學家如何解釋內在機制?

編譯|葛竑志
位在加州的Uber總部,Yosinski像許多AI科學家一樣,想辦法要把深度學習(Deep Learning)應用在他們的自駕系統上。將大量已標記的影像,像是斑馬線、消防車、安全帶等拿來訓練出一個能夠辨識物體的模型之後,他在想這樣的模型是否也能夠認出鏡頭前的自己?Yosinski將攝影機轉向自己一看,令人意外的是,某幾個神經網路(Neural network)的節點(Neuron)上還真能看到自己臉的輪廓。
好奇的他還做了幾個實驗,發現各個節點擅長認得的東西不太一樣,有些很會辨識身上的衣服,有些則是書上的文字,這些事情並沒有人告訴這塊模型去學習,那它到底是如何懂得去認得這些東西呢?「我們不是非常了解它們,而且我們對AI的認知差距正越來越大。」他這麼說。[1]
近年來,深度學習已為許多跨領域科學研究注入大量活水,也為現代科技開啟了更多的可能性。然而,複雜的神經網路就如同一塊黑盒子,在始終難以從外部去了解其中原理的情況下,更也考驗著人們對於AI的信任程度。2017年,來自一項歐盟的指示,要求任何決策可能影響公眾利益的公司將來必須要說明其預測模型的邏輯,此外,美國軍方的藍天研究機構也將挹注七千萬美元在「可解釋AI」計畫上(Explainable AI),顯示去理解AI、打開黑盒子已是個迫不可待的趨勢。這門新的學問,Yosinski稱它叫作「AI神經學」(AI Neuroscience)。
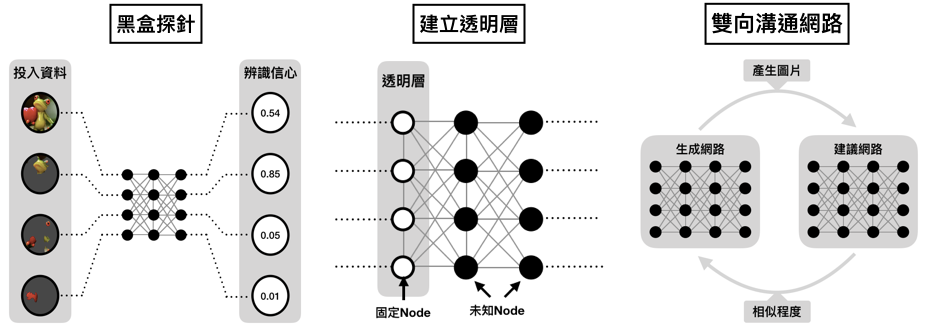
●黑盒探針-投入資料的重新組合
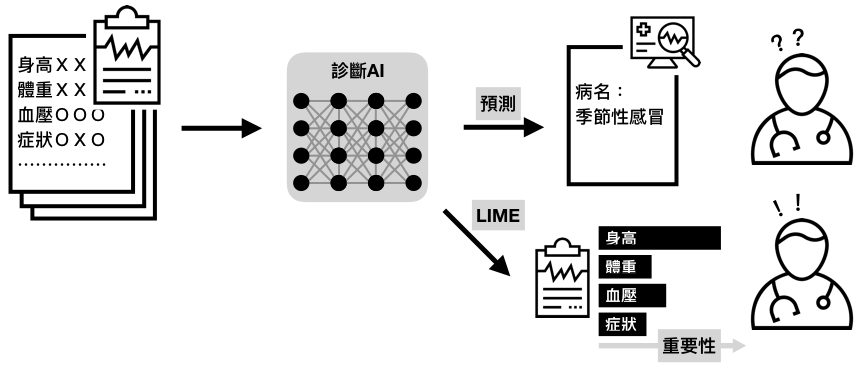
在許多使用深度學習做決策的當下,使用者往往就是投入輸入參數、放到模型,最後就直接得出結果,若事小還可接受,但若這個決策非常之重要,那麼不免讓人得去懷疑資料到底在模型中扮演了什麼角色 。
華盛頓大學的Ribeiro提出LIME(Local Interpretable Model-agnostic Explanations),或許能夠對此作出解釋 。他們僅僅是先將輸入資料進行分割,並使用這些區塊組合送入模型,最後比較出哪種組合最能夠讓模型預測出指定的結果。像是這一張圖片裡的青蛙手上拿著愛心,整張圖片送進模型後被認為是青蛙的機率只有0.54(畢竟還有青蛙本體以外的雜訊),但若投入的區塊僅是青蛙頭部,則表現會更好,這或許也說明了模型學習到去辨識青蛙頭部的特徵。[2]
一位在Google GlassBox計畫的主持人Gupta,曾提出單調內差查表(Monotonic interpolated loolup tables)來提生神經網路的透明性。試想生活中有許多參數間本來就具有一定的相關性,這些事情若是已知,便不需要再透過神經網路去重新學習的。舉例而言,今天想從一台二手車的各項資訊去計算它應有的出售價值,當各項參數都固定時,儀表板上的里程數必將與其價值成單調負相關函數,這是十分直覺的結果。回到實際面,在許多資料量不足或雜訊過多的情形下,神經網路訓練的成效並非每次都可以幸運地獲得良好結果,若能將特定參數間的關係預先定義好,減少黑盒節點的部分,將有望能助於人們了解模型意義,並更易於控制模型學習的走向。[3]
●機器看到的和我們不一樣——使用複數個模型互相做辨識與生成
Yosinski在後續的研究中嘗試將訓練好的神經網路用於產生影像。他們將彩色雜訊(Colored static)輸入模型中,並固定輸出端的分類結果為「火山」,再來把焦點放在特定的節點上,透過倒傳遞(Backpropagation)方式取得最能夠讓該節點活化(Activation)的
梯度後,再疊加於彩色雜訊上。起初結果讓人很困惑,因為看起來還是很像雜訊,但或許對神經網路來說,這已經是最像火山的一幅影像了。[1]
Yosinski的團隊也使用生成對抗式網路(GAN),除了使用「生成模型」(Generator network)從訓練圖片集去合成指定的影像,更採用另一個「建議模型」(Adversary network)針對前一個模型產出的圖片去判斷是否符合初始期望,並回饋給生成模型產出更逼真的影像。他們的結果發現許多圖片確實合成出逼真的火山樣貌,某些正在噴發、有些則是休止、某些在白天、有些在黑夜,也有些看不出是什麼。[4]
事實上,即便我們不容易去理解模型看到的最佳解(例如前面火山的例子),GAN確實有助於我們去理解模型學習到的是哪些特徵。Yosinski解釋,某些結果的錯誤可能來自於訓練資料、標記方式或是神經網路本身的問題,重複類似的實驗就可以去印證、並處理問題所在。「這些提示也許能為AI神經學提供一些方向」,他說,「這還只是個開始,就像空白地圖上才剛探索完一小部分。」

參考資料:
[1] Understanding Neural Networks Through Deep Visualization
[2] Introduction to Local Interpretable Model-Agnostic Explanations (LIME)
[3] Monotonic Calibrated Interpolated Look-Up Tables
[4] Plug & play generative networks: Conditional iterative generation of images in latent space
![]()