
真偽莫辨的人像產生器

編譯/葛竑志
你相信上圖中所有人物都是假的嗎?透過對抗式生成網路(Generative Adversarial Network,GAN)與新興技術,就能憑空產生一些不存在的人事物,甚至可按照使用者需求,訂製出清晰且逼真的影像。自2014年Ian Goodfellow首次提出後,GAN開始在各大頂級研討會上佔有一席之地。截至今日為止,已有許多進化版本被提出來。但到底為何會如此受到矚目呢?
近十年來,隨GPU及平行運算的能力大幅提升,神經網路已朝向深層化與規模化的方向發展,但也逐漸遇到一項嚴峻挑戰:具標記的資料集可遇不可求。若無雄厚資本與計算能力的加持,所訓練出的AI模型表現恐不如預期。因此,與其一張張圖片諄諄善誘教導機器如何辨別,許多電腦科學家更期望AI可以完全脫離人工標記的輔助、自主學習。這種不倚賴人為干涉的學習方法稱作「非監督式學習」(Unsupervised learning),GAN正是此種框架下表現相當突出的機器學習模型。
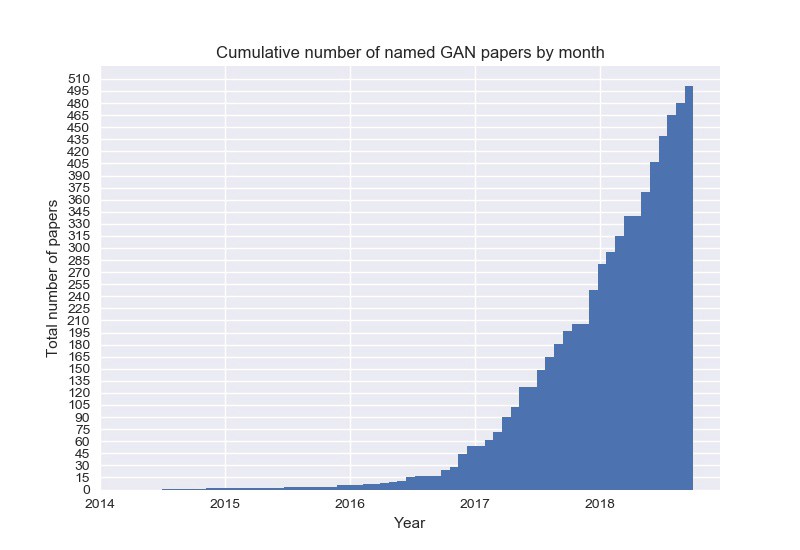
圖一、近年來與GAN相關的論文發表數量急遽攀升。(來源:The GAN Zoo)
Goodfellow當年在思考如何使用機器產生圖片時,便描繪了兩個相互獨立的神經網路:Generator(生成器)與Discriminator(鑑別器)。前者在給定的隨機向量(Latent vector)下,透過摺積層(Convolution layer)產生圖片;後者則判斷該圖片的真偽。在兩個網路你來我往、相互切磋的過程中,Generator所產生的圖片也越來越逼真。
提升解析度
起初,GAN所生成的圖片大小主要還是在64×64以下,過大則容易失真,直到國際知名GPU製造商Nvidia的研究團隊提出漸進式學習方法(Progressive GAN)[4]。一開始,他們將Generator和Discriminator的層限制在相當小的維度,如4×4;同時,送到Discriminator的真實圖片也需同步降低取樣大小至4×4。待訓練一段時間後,在兩個神經網路各疊一層倍增的維度,如8×8,並繼續以同維度的圖片訓練。週而復始直至1024×1024時,就能產生高畫質、不容易失真的圖片了。
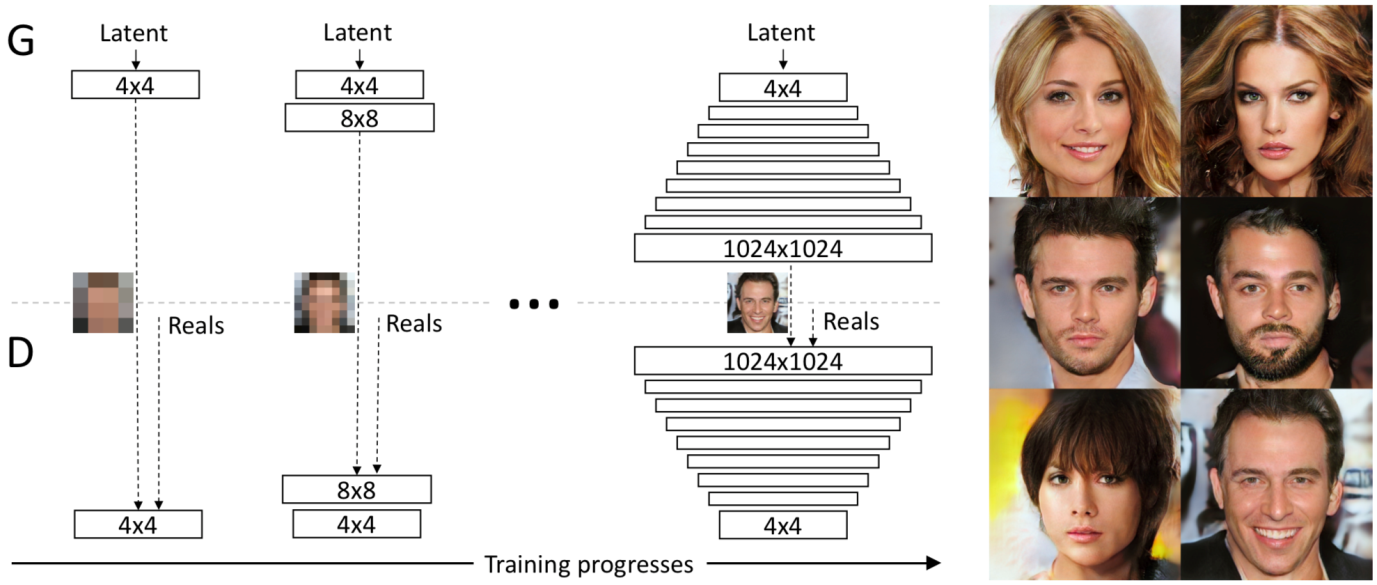
圖二、Progressive GAN的訓練架構。(來源:T. Karras et al., 2018.)
細察Generator的架構,發現越底層的神經元控制著人臉較粗糙的特徵,如臉型、膚色及髮型;反之,越上層則處理越細部的特徵,如表情、眼睛的閉合、髮色到膚質等細節。最近,同一團隊也釋出升級版本─以風格轉換為基礎的GAN(Style-based GAN)。
風格轉換
相信你一定不陌生那些能預測你上了年紀或轉換性別後會長怎樣的應用程式。理論上,藉由調整Latent vector的某些元素,就能左右圖中人物的性別、髮長或膚色等;然而,實際操作可能比你想像中還要來得困難。
例如,若原先的訓練資料集有所偏誤(biased),例如以亞洲人的圖像為大宗了話,則任憑給定的Latent vector多麽地不同,Generator最後的輸出結果就只是稍有不同的黃膚色人臉。主要原因在於訓練資料的變異度過小,導致Generator的輸出空間不夠大,即使再怎麼調整latent vector都無法超出原先訓練的範疇。
此外,特徵糾纏(Features entanglement)現象也令人難以釐清Latent vector中的哪些成份究竟控制著人臉的哪個特徵。使得任何數值的調整,都是牽一髮而動全身,稍有不慎,便是面目全非。為此,新提出的架構主要採用了以下三種核心技術:
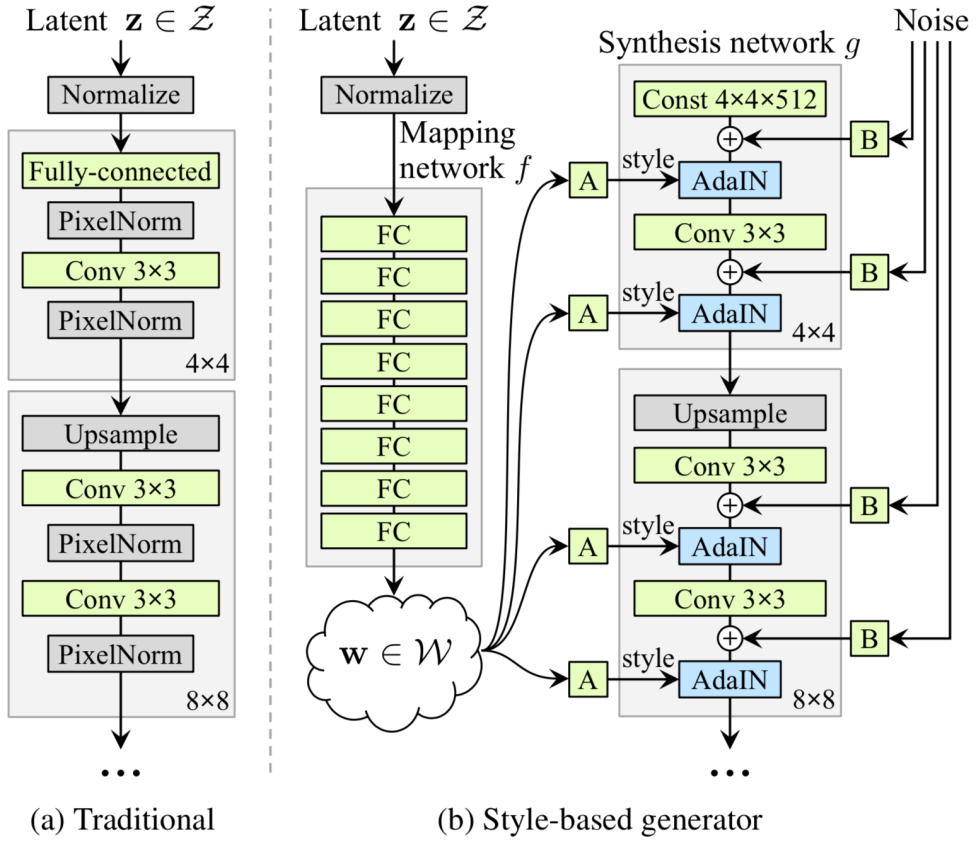
圖三、Style-based GAN的架構。(來源:T. Karras et al., 2018.)
第一,有別於傳統GAN直接將latent vector作為圖片形成的基底,Karras等人則將基底固定住(圖三4x4x512的部分),而後借用風格轉換(Style transfer)的概念,在各個解析度的層上,逐步為所謂的「內容」加上來自Latent vector的「風格」,最終組合成一張畫質相當高的圖片。
第二,Latent vector會先通過數個全連結層(Fully connected layer)所構成的網路。在團隊的假設中,若採傳統GAN的架構,Latent vector會在Z空間中極盡所能地近似訓練圖片的分佈,將直接導致糾纏現象(Entanglement)的發生。為此,他們使Latent vector透過一種非線性轉換(從Z空間到W空間)成w向量後,再套用到「內容」身上。透過這個額外的神經網路,擴展的Latent vector的轉換空間,使得w向量不再受限於訓練資料的機率分佈,同時能降低不同特徵之間的相關性,達到特徵解離(Feature disentanglement)的目的[3]。
第三,在各個解析度層中加入「風格」與「隨機成分」。在「風格」上,他們使用仿射變換(Affine transformation,如圖三a),將w向量轉換為AdaIN(Adaptive Instance Normalization)所需的縮放與偏誤參數。另一方面,為了仿真人臉中如頭髮、細紋等較複雜的細緻特徵,每個層都會額外加上經過縮放(如圖三b)的雜訊,作為隨機成分的來源。
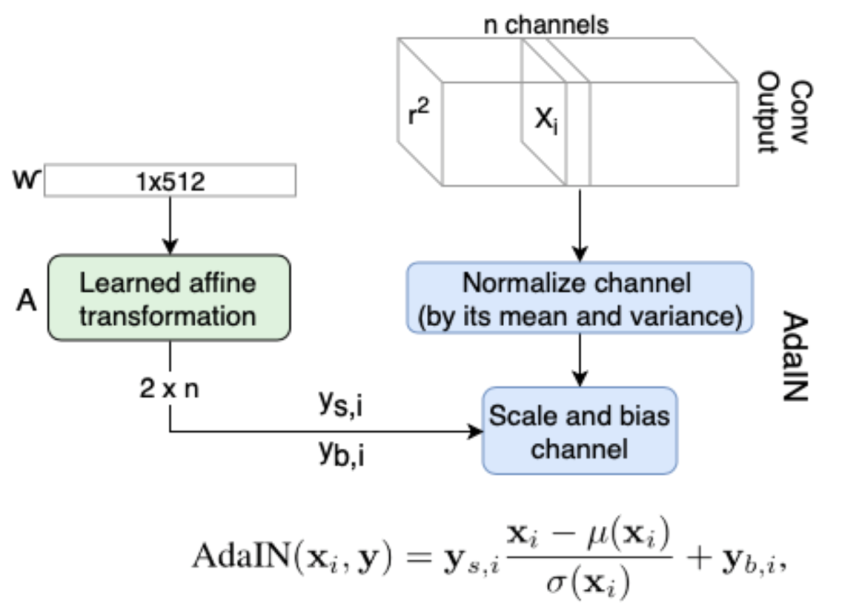
圖四、加入「風格」的流程與AdaIN的轉換。AdaIN是風格轉換中將「內容」正則化為「風格」分布的技巧。其中y來自於「風格」成分,x來自於「內容」成分。(來源:R. Horev, 2018.)

圖五、在不同層上合成不同人臉特徵。(來源:[7])
與Progressive GAN相同,Style-based GAN較為底層的Latent vector代表人臉上較粗略的特徵,中層控制著表情與眼睛,最上層則是髮色與臉部等細節。Nvidia團隊利用巧思,改變Latent vector的輸入方式,從而由不同階層的輸入改變圖像風格,著實令人期待往後的技術突破。
編譯來源
Will Knight. These incredibly realistic fake faces show how algorithms can now mess with us. MIT Technology Review. 2018.
參考資料
- R. Horev, “Explained: A Style-Based Generator Architecture for GANs – Generating and Tuning Realistic Artificial Faces“, Towards Data Science, 2018.
- W. Knight, “AI software can dream up an entire digital world from a simple sketch“, MIT Technology Review, 2018.
- T. Karras, S. Laine, T. Aila, “A Style-Based Generator Architecture for Generative Adversarial Networks“, Arxiv.org, 2018.
- T. Karras, T. Aila, S. Laine, J. Lehtinen, “Progressive Growing of GANs for Improved Quality, Stability, and Variation“, ICLR 2018.
- X. Huang, S. Belongie, “Arbitrary Style Transfer in Real-time with Adaptive Instance Normalization“, ICCV 2017.
- A. Hindupur, “The GAN Zoo”, GitHub.
- A Style-Based Generator Architecture for Generative Adversarial Networks, YouTube, 2018.
(本文由教育部補助「AI報報─AI科普推廣計畫」執行團隊編譯)