不實資訊如何趁我們線上購物時被散播開來?
自新冠肺炎爆發開始,各種關於到底要怎麼戴口罩、判斷症狀的依據或是接種疫苗到底有沒有幫助的資訊紛紛在社群網絡上散播開來,不實資訊在社群媒體上散播已不是新鮮事。不實資訊除了透過社群媒體散播開來之外,在現今幾乎成為我們生活中不可或缺的線上購物平台上,有沒有可能是另一個加速散播不實資訊的溫床?
Read more

自新冠肺炎爆發開始,各種關於到底要怎麼戴口罩、判斷症狀的依據或是接種疫苗到底有沒有幫助的資訊紛紛在社群網絡上散播開來,不實資訊在社群媒體上散播已不是新鮮事。不實資訊除了透過社群媒體散播開來之外,在現今幾乎成為我們生活中不可或缺的線上購物平台上,有沒有可能是另一個加速散播不實資訊的溫床?
Read more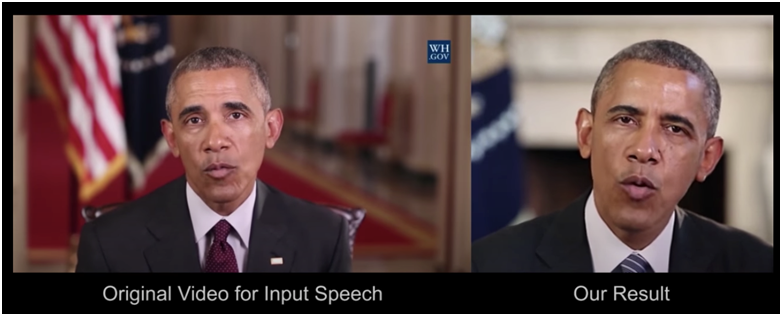
市面上有許多有趣的變臉或換臉APP,像是FaceApp,可以讓我們上傳自己的照片後讓系統把我們的面貌從男性變女性、髮型由短變為長、面容由老化變為年輕,甚至是把自己的臉完全變成另一個人名人的樣子。這些變臉的效果仰賴的是電腦視覺來辨識一個人的臉部細節,接著再仰賴電腦圖學的技術合成與改變原本臉上沒有的細節,像是長出鬍子、皺紋、去除斑點等。當這些技術越來越成熟的時候,除了被應用在一些有趣的美妝APP上供大家娛樂之外,近年來也越來越多人透過「深偽技術」把不同人的臉移花接木來製作假影片,進而操弄大眾的情緒和政治意向,甚至是成為性暴力的工具。在這真假難分的花花世界裡,我們有能力判別合成影片嗎?
Read more

Facebook收羅了10萬部Deepfake變造影片,並舉辦識別競賽,讓AI來對抗AI。
Read more
人工智慧讓每一個人都能輕易篡改影音,最大的威脅將是我們不再相信任何事。(續前文)
Read more
人工智慧讓每一個人都能輕易篡改影音,最大的威脅將是我們不再相信任何事。(續前文)
Read more
人工智慧讓每一個人都能輕易篡改影音,最大的威脅將是我們不再相信任何事。(續前文)
Read more
人工智慧讓每一個人都能輕易篡改影音,最大的威脅將是我們不再相信任何事。
Read more
2019年2月,OpenAI開發出幾可亂真的文本生成器GPT-2,因擔心有心人士濫用,延後公布完整原始碼;然而解鈴還需繫鈴人, MIT-IBM Watson人工智慧實驗室與哈佛自然語言實驗室(Harvard NLP)合作開發出一套工具GLTR(Giant Language model Test Room),能準確分析文章是否由機器生成或由人類所撰寫。以下簡單介紹GLTR的分析方法與運作。
Read more
2019年2月,知名研究團隊OpenAI發表了簡稱為GPT-2的文本生成模型。研究團隊使用達40 GB的資料量,結果好到讓研究人員為避免惡意濫用,決定暫緩開放原始碼。2019年5月初,兩個簡化後的模型在千呼萬喚中釋出,參數量分別為1.17億與3.45億個,雖與15億參數的原始版本相比,小巫見大巫,卻也顯示出僅是增加資料量與模型複雜度,電腦便可寫出令人難辨真偽的文字內容,輕易淪為假新聞的量產工具。
Read more

■2018年,「misinformation」獲選為一線上字典網站的年度代表字,這個單字有個很相似的親戚「disinformation」,乍看之下讓人有些傻傻分不清楚,很容易混淆。
從字義上來看,「disinformation」指的是「被故意散播容易誤導、或是含有特定偏見價值觀的資訊」,簡單來說就是所謂的惡意訊息,是個蠻嚴肅的字。相較起來,「misinformation」的意思就寬鬆許多,指的是「被散播的虛假訊息,無論傳播者是否有特定意圖」,或許可以把這個詞翻譯成所謂的「流言」。

假新聞、假消息氾濫的時代來襲,有心人士杜撰的不再只是充滿陰謀論的文字與情節,或是那些容易被看破的粗糙修圖,現在已能借AI之力偽造出以假亂真的影片了。這關乎的不再只是大眾的媒體識讀能力,而是我們人類是否有能力看穿偽造影片背後的真相呢?
Read more
看著別人恣意耍帥尬舞,或是優雅慢舞,你是否只能望著自己僵硬的肢體,徒呼負負?美國柏克萊大學的研究團隊利用對抗式生成網路,讓本身不太會跳舞的人也能在影片中翩翩起舞。
Read more